Phân phối tài nguyên linh động trên Kubernetes
Trong thế giới công nghệ ngày nay, K8s ngày càng trở nên phổ biến trong số các công ty đang tìm cách phát triển các sản phẩm có khả năng mở rộng và hiệu quả. Trong bài đăng hôm nay, chúng tôi sẽ giới thiệu một số cách quản lý tài nguyên phần cứng trong K8s.
Tổng quan
Một trong những mục tiêu thiết yếu nhất của Kubernetes (K8s) là chạy workloads bên trong các container một cách hiệu quả. Tuy nhiên, một thách thức đáng kể phát sinh từ thực tế là workloads khác nhau có các yêu cầu khác nhau. Ví dụ, workloads yêu cầu sử dụng nhiều GPU từ các node khác nhau để đào tạo và suy luận cần các cài đặt GPU cụ thể để hoạt động tối ưu. Sự đa dạng trong các yêu cầu này làm nổi bật nhu cầu quản lý tài nguyên hiệu quả để phân bổ đúng tài nguyên cho từng workload. Các tài nguyên chính phải được quản lý bao gồm CPU, bộ nhớ, lưu trữ và plugin thiết bị cho GPU. Bằng cách giám sát hiệu quả các tài nguyên này, chúng ta có thể đảm bảo rằng workloads nhận được sự hỗ trợ cần thiết để hoạt động thành công trong môi trường container.
Tài nguyên tích hợp có thể được tìm thấy trên trạng thái node bằng kubectl describe no <your_target_nodename> trong đó
cpu,ephemeral-storage,hugepages-1Gi,hugepages-2Mivàmemorylà các tài nguyên tích hợp mà K8s cung cấp sẵn
Capacity:
cpu: 24
ephemeral-storage: 23812322Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 65522222Ki
pods: 110
Allocatable:
cpu: 20
ephemeral-storage: 220020012312
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 6540123Ki
pods: 110
Một trong những plugin tùy chỉnh phổ biến là volume plugin cho phép các nhà cung cấp lưu trữ khác nhau tích hợp giải pháp lưu trữ của họ vào cụm K8s
- Ví dụ, dữ liệu trên pod có thể được cấu hình để lưu trữ trên Hệ thống tệp mạng (NFS)
apiVersion: apps/v1
kind: Deployment
metadata:
name: test
spec:
selector:
matchLabels:
app.kubernetes.io/component: test
replicas: 1
template:
metadata:
labels:
app.kubernetes.io/component: test
spec:
containers:
- image: registry.k8s.io/test
name: test
volumeMounts:
- mountPath: /test_nfs
name: test_nfs
volumes:
- name: test_nfs
nfs:
server: my-nfs-server.example.com
path: /my-nfs-volume
readOnly: true
Nhưng vấn đề với volume plugin là nó được kết hợp chặt chẽ với K8s core code, do đó, các nhà cung cấp lưu trữ khó có thể tích hợp các giải pháp lưu trữ của họ vào K8s codebase.
Device Plugin
Device Plugin không chỉ cho phép các nhà cung cấp lưu trữ mà còn cho phép các nhà cung cấp phần cứng khác tích hợp các giải pháp phần cứng của họ vào cụm K8s mà không cần thay đổi K8s codebase. Vì Device plugin là plugin Kubelet, device plugin chạy trong mọi node trong cụm như một daemonset
Cụ thể, sau khi Kubelet nhận được phản hồi từ K8s api-server, cái mà yêu cầu Kubelet triển khai các pod có yêu cầu phần cứng cụ thể trên node, Kubelet sẽ gọi một số phương thức được xác định trước tới Device Plugin
GetDevicePluginOptions: trả về các tùy chọn để giao tiếp với Device ManagerListAndWatch: trả về luồng List of Devices bất cứ khi nào trạng thái của Device thay đổi hoặc Device biến mấtAllocate: được gọi trong quá trình tạo container để Device Plugin có thể chạy các hoạt động cụ thể của thiết bị và hướng dẫn Kubelet các bước để làm cho Device khả dụng trong containerGetPreferredAllocation: trả về một tập hợp các thiết bị được ưu tiên để phân bổ từ danh sách các thiết bị khả dụng. Phân bổ được ưu tiên kết quả không được đảm bảo là phân bổ cuối cùng do device manager thực hiệnPreStartContainer: được gọi, nếu được Device Plugin chỉ định trong giai đoạn đăng ký trước mỗi lần khởi động container. Device Plugin có thể chạy các hoạt động cụ thể của thiết bị như đặt lại thiết bị trước khi làm cho các thiết bị khả dụng cho container.
service DevicePlugin {
rpc GetDevicePluginOptions(Empty) returns (DevicePluginOptions) {}
rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {}
rpc Allocate(AllocateRequest) returns (AllocateResponse) {}
rpc GetPreferredAllocation(PreferredAllocationRequest) returns (PreferredAllocationResponse) {}
rpc PreStartContainer(PreStartContainerRequest) returns (PreStartContainerResponse) {}
}
Thay vì tích hợp triển khai phần cứng vào K8s codebase, các nhà phát triển nhà cung cấp chỉ cần triển khai các phương pháp này dựa trên cấu hình phần cứng của họ và phát hành dưới dạng daemonset
Ví dụ bên dưới là khi k8s-device-plugin được triển khai để chia một GPU duy nhất trên một node thành 2 GPUs, vì vậy thay vì nvidia.com/gpu thông thường, nvidia.com/gpu.shared được tìm thấy trên tài nguyên của node.
Capacity:
cpu: 24
ephemeral-storage: 23812322Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 65522222Ki
nvidia.com/gpu.shared: 4
pods: 110
Allocatable:
cpu: 20
ephemeral-storage: 220020012312
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 6540123Ki
nvidia.com/gpu.shared: 4
pods: 110
Bất kỳ workload nào, ví dụ như pods, deployments, đều có thể sử dụng Device Plugin, ví dụ như nvidia.com/gpu.shared để yêu cầu phân bổ phần cứng
apiVersion: apps/v1
kind: Deployment
metadata:
name: test
spec:
selector:
matchLabels:
app.kubernetes.io/component: test
replicas: 1
template:
metadata:
labels:
app.kubernetes.io/component: test
spec:
containers:
- image: registry.k8s.io/test
name: test
resources:
requests:
nvidia.com/gpu.shared: 1
responses:
nvidia.com/gpu.shared: 1
Tuy nhiên, Device Plugin có những hạn chế riêng.
- Đầu tiên, nó không hỗ trợ tài nguyên được chia sẻ, Device Plugin không thể sử dụng cùng một tài nguyên cùng lúc. Ví dụ, hãy xem xét trường hợp của nvidia.com/gpu.shared: nếu có 4 nvidia.com/gpu.shared khả dụng và tất cả chúng đều đang được sử dụng, bất kỳ workload nào yêu cầu thêm nvidia.com/gpu.shared phải đợi cho đến khi một resource khả dụng để schedule.
- Thứ hai, không có cài đặt nào về resource không giới hạn, do đó Device Plugin áp dụng hạn ngạch riêng của mình cho các tài nguyên không giới hạn. Ví dụ, Device Plugin cho KVM vẫn áp đặt hạn ngạch mặc dù KVM không phải là tài nguyên bị giới hạn, vì nó chỉ là cấu hình của CPU.
- Cuối cùng, Device Plugin thiếu khả năng cấu hình nâng cao. Trong một số trường hợp, nhiều thành phần phần cứng từ cùng một nhà cung cấp có thể yêu cầu các cài đặt khác nhau. Ví dụ, hai GPU giống hệt nhau trên cùng một node có thể cần các cấu hình riêng biệt, nhưng Device Plugin không cho phép các điều chỉnh nâng cao này.
Giới thiệu về Dynamic Resource Allocation và các APIs
Dynamic Resource Allocation (DRA) cung cấp tính linh hoạt và khả năng thích ứng cao hơn trong quản lý tài nguyên
- Không giống như phân bổ tĩnh trong Device Plugins cái mà yêu cầu số lượng cố định cho các tài nguyên đã chọn, DRA cho phép các yêu cầu và chỉ định linh hoạt hơn cho Pod và Container
- Phương pháp này khái quát hóa volume API cho nhiều tài nguyên khác nhau, chẳng hạn như GPU, cho phép quy trình phân bổ phản hồi nhanh hơn và hiệu quả hơn, có thể đáp ứng tốt hơn nhu cầu thay đổi của workload.
Có 3 API cơ bản cho DRA
ResourceClass: Xác định resource driver nào xử lý một loại tài nguyên nhất định và cung cấp các tham số chung cho tài nguyên đóResourceClassđược quản trị viên cụm tạo ra khi cài đặt DRA.
ResourceClaim: Xác định một resource driver cụ thể được yêu cầu bởi workload- Do người dùng tạo hoặc cho từng Pod bởi control plane dựa trên
ResourceClaimTemplate
- Do người dùng tạo hoặc cho từng Pod bởi control plane dựa trên
ResourceClaimTemplate: Xác định thông số kỹ thuật và một số metadata để tạoResourceClaim- Do người dùng tạo khi triển khai workload
Ví dụ, nếu không có DRA, chúng ta cần xác định số lượng GPU cho workload của mình
apiVersion: apps/v1
kind: Deployment
metadata:
name: test
spec:
selector:
matchLabels:
app.kubernetes.io/component: test
replicas: 1
template:
metadata:
labels:
app.kubernetes.io/component: test
spec:
containers:
- image: registry.k8s.io/test
name: test
resources:
requests:
nvidia.com/gpu: 1
responses:
nvidia.com/gpu: 1
Nhưng với Dynamic Resource Allocation, chúng ta cần
- Đầu tiên, hãy xác định
ResourceClassđược liên kết với trình điều khiển tài nguyên, ví dụ nvidia.com trong ví dụ này -
- Trong đó resource driver nào cần được cài đặt trong hệ thống local
apiVersion: resource.k8s.io/v1alpha2
kind: ResourceClass
metadata:
name: gpu.nvidia.com
driverName: gpu.resource.nvidia.com
Sau đó, hãy định nghĩa ResourceClaimTemplate cái mà tương đối giống với Persistent Volume Claim
apiVersion: resource.k8s.io/v1alpha2
kind: ResourceClaimTemplate
metadata:
name: gpu-template
spec:
spec:
resourceClassName: gpu.nvidia.com
Cuối cùng yêu cầu ResourceClaimTemplate để sử dụng tài nguyên trong workload
apiVersion: apps/v1
kind: Deployment
metadata:
name: test
spec:
selector:
matchLabels:
app.kubernetes.io/component: test
replicas: 1
template:
metadata:
labels:
app.kubernetes.io/component: test
spec:
containers:
- image: registry.k8s.io/test
name: test
resources:
claims:
- name: gpu0
- name: gpu1
resourceClaims:
- name: gpu0
source:
resourceClaimTemplate: gpu-template
- name: gpu1
source:
resourceClaimTemplate: gpu-template
Hơn nữa, cùng một resource có thể được chia sẻ giữa các container giống nhau trong pod
- Trong trường hợp này, 2 container đang pod
testđang sử dụng cùng một tài nguyên GPUshared-gpu
apiVersion: apps/v1
kind: Deployment
metadata:
name: test
spec:
selector:
matchLabels:
app.kubernetes.io/component: test
replicas: 1
template:
metadata:
labels:
app.kubernetes.io/component: test
spec:
containers:
- image: registry.k8s.io/ctr0
name: ctr0
resources:
claims:
- name: gpu
- image: registry.k8s.io/ctr1
name: ctr1
resources:
claims:
- name: gpu
resourceClaims:
- name: gpu
source:
resourceClaimTemplate: shared-gpu
Hoặc cùng một nguồn có thể được chia sẻ giữa các workload khác nhau
- Trong ví dụ này, 2 deployments test1 và test2 đang sử dụng cùng một tài nguyên GPU shared-gpu
apiVersion: apps/v1
kind: Deployment
metadata:
name: test1
spec:
selector:
matchLabels:
app.kubernetes.io/component: test1
replicas: 1
template:
metadata:
labels:
app.kubernetes.io/component: test1
spec:
containers:
- image: registry.k8s.io/ctr
name: ctr
resources:
claims:
- name: gpu
resourceClaims:
- name: gpu
source:
resourceClaimTemplate: shared-gpu
apiVersion: apps/v1
kind: Deployment
metadata:
name: test2
spec:
selector:
matchLabels:
app.kubernetes.io/component: test2
replicas: 1
template:
metadata:
labels:
app.kubernetes.io/component: test2
spec:
containers:
- image: registry.k8s.io/ctr
name: ctr
resources:
claims:
- name: gpu
resourceClaims:
- name: gpu
source:
resourceClaimTemplate: shared-gpu
Cấu trúc của Dynamic Resource Allocation
Có 2 thành phần chính của Dynamic Resource Allocation
- Controller – deployment
- Gọi default scheduler để quyết định node nào có thể được chỉ định yêu cầu
ResourceClaim - Phân bổ
ResourceClaimkhi node được schedule - Hủy phân bổ
ResourceClaimkhi workload bị xóa
- Gọi default scheduler để quyết định node nào có thể được chỉ định yêu cầu
- Kubelet-plugin – daemonset
- Phân phối trạng thái node cho Controller để schedule workload
- Chuẩn bị tài nguyên node như một phần của phân bổ
ResourceClaim - Unprepare – dọn dẹp – tài nguyên node như một phần của hủy phân bổ
ResourceClaim
Dynamic Resource Allocation cũng cung cấp 2 loại phân bổ
- Immediate: Tài nguyên được phân bổ ngay sau khi
ResourceClaimđược tạo - WaitForFirstConsumer: Phân bổ tài nguyên bị hoãn lại cho đến khi pod đầu tiên được lên lịch
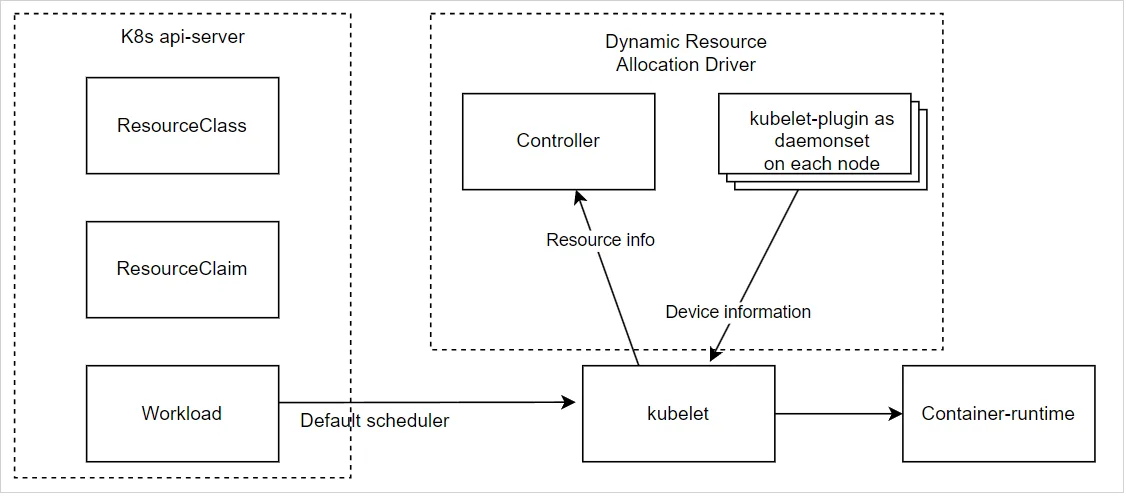
Immediate Allocation Flow
- Bước 1: Quản trị viên triển khai DRA, kiểm tra xem 2 thành phần chính có được cài đặt đúng trên cụm không
- Bước 2: Quản trị viên tạo
ResourceClasscho trình điều khiển tài nguyên
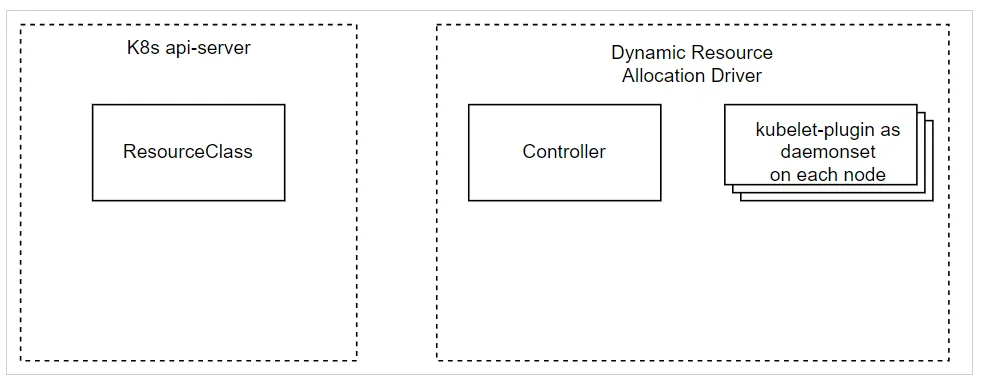
Bước 3: Sau đó, người dùng tạo ResourceClaim tham chiếu đến ResourceClass
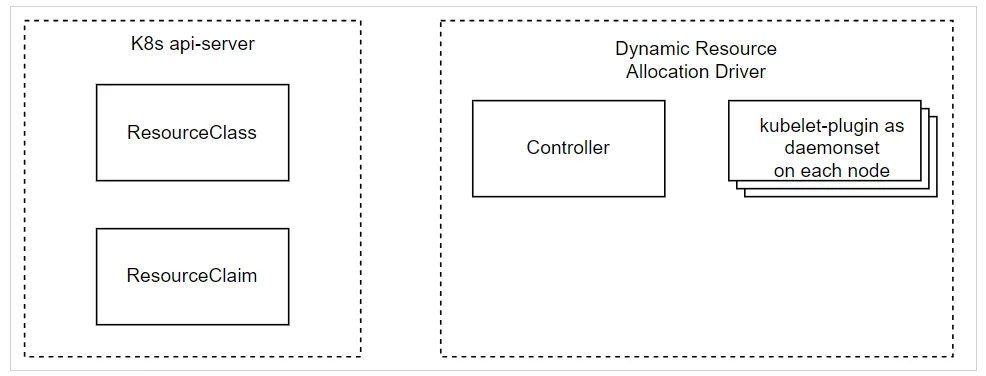
- Bước 4: Controller sau đó phân bổ
ResourceClaimnày trên node được phân bổ, cụ thể- Nó đặt thông tin liên quan đến tài nguyên được phân bổ
- Sau đó, nó chuyển thông tin đến kubelet-plugin để chuẩn bị tài nguyên node
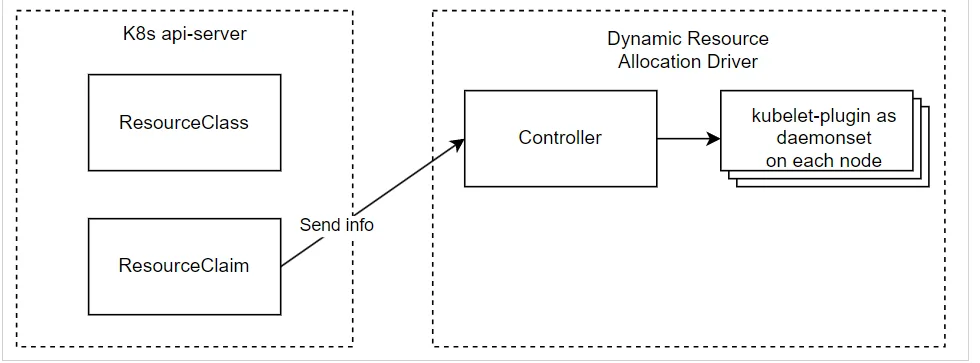
Bước 5: Sau đó, người dùng tạo khối lượng công việc sử dụng ResourceClaim
WaitForFirstConsumer allocation flow
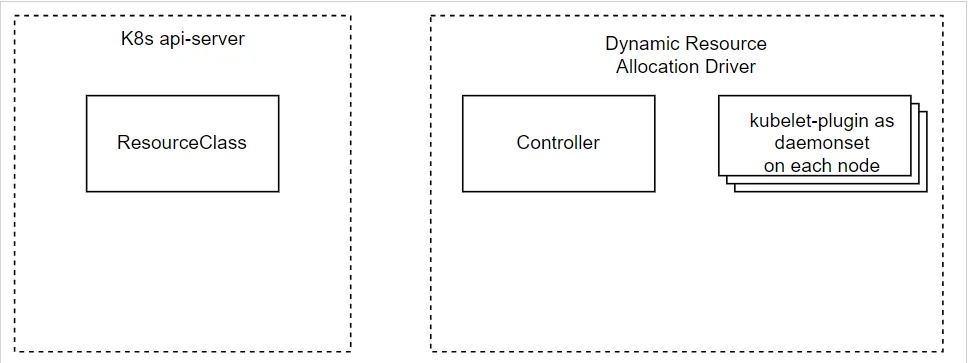
- Bước 1: Quản trị viên triển khai Dynamic Resource Allocation, kiểm tra xem 2 thành phần chính đã được cài đặt đúng trên cụm chưa
- Bước 2: Quản trị viên tạo
ResourceClasscho trình điều khiển tài nguyên
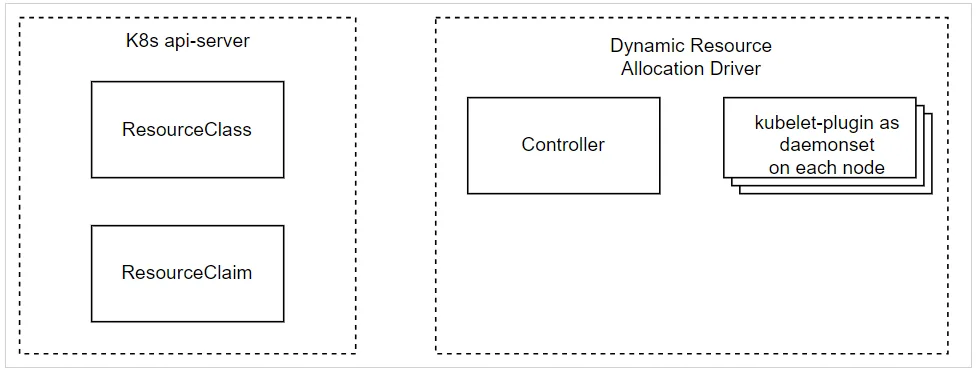
Bước 3: Sau đó, người dùng tạo ResourceClaim tham chiếu đến ResourceClass
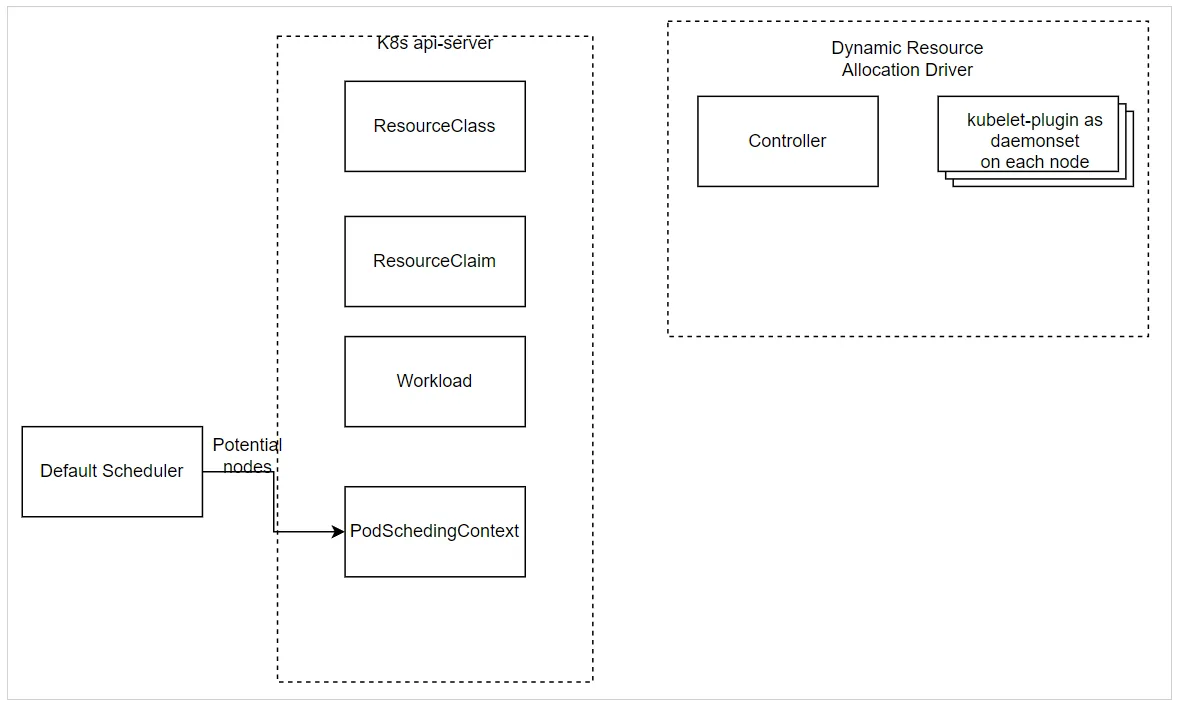
- Bước 4: khi workload được tạo, default scheduler sẽ bắt đầu tạo danh sách các node thích hợp với
ResourceClaim- Sau đó tạo PodSchedulingContext để phối hợp lập lịch pod khi
ResourceClaimcần được phân bổ cho một Pod trên các nút này
- Sau đó tạo PodSchedulingContext để phối hợp lập lịch pod khi
- Bước 5: Controller cập nhật PodSchedulingContext với các node không thể được phân bổ
UnsuitableNodes- Lặp lại cho đến khi một node được chọn để phân bổ tài nguyên
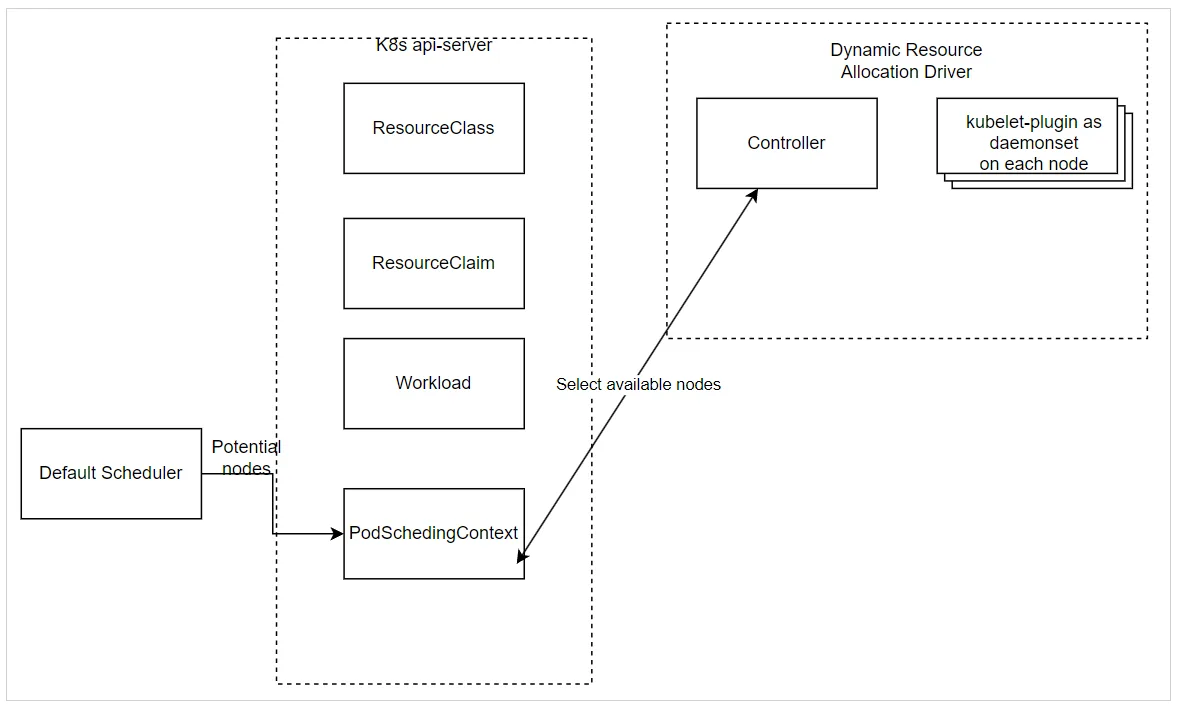
- Bước 6
- Sau đó, Scheduler đặt node này trong PodSchedulingContext
- Sau đó, Controller phân bổ
ResourceClaimtrên node này với các bước tương tự như Immediate Allocation
Tham khảo
https://kubernetes.io/docs/concepts/extend-kubernetes/compute-storage-net/device-plugins
https://kubernetes.io/docs/concepts/scheduling-eviction/dynamic-resource-allocation