CCTV – Tìm kiếm người từ nhiều camera
Trên thế giới, việc ứng dụng camera giám sát kết hợp trí tuệ nhân tạo vào đời sống ngày càng trở nên phổ biến. Gần đây một nhóm các nhà nghiên cứu trực thuộc Đại học Thành phố New York (CUNY) đã nhận định rằng các hành vi không đúng chuẩn mực đạo đức hoặc vi phạm pháp luật trên đường phố và tại các nhà ga công cộng đã giảm lần lượt 24% và 28% sau khi các khu vực trên được triển khai các máy quay an ninh. Theo một thống kê không chính thức, tổng số lượng camera giám sát trên toàn cầu đã vượt con số 770 triệu và dự kiến sẽ sớm đạt 1 tỷ camera. Với sự bùng nổ về số lượng camera giám sát và nguồn dữ liệu hình ảnh và video khổng lồ hiện nay, dẫn đến việc các giải pháp ứng dụng hình ảnh và video cũng nhận được nhiều sự quan tâm của cộng đồng nghiên cứu trong lĩnh vực trí tuệ nhân tạo và thị giác máy tính (Computer Vision).
Tìm kiếm người từ nhiều camera (multi-person search multi-camera) sau đây gọi tắt là Truy vấn người, đây là một trong những ứng dụng cơ bản và phổ biến sử dụng camera giám sát, trong đó hình ảnh từ một người được chỉ định sẽ được hệ thống nhận diện và tìm kiếm từ dữ liệu của nhiều camera, hoặc hình ảnh, video khác nhau. Nói cách khác, Truy vấn người nhằm xác định xem người cần tìm kiếm xuất hiện ở những khu vực nào, trong những khoảng thời gian nào trên cơ sở dữ liệu đã lưu trữ hoặc dữ liệu thời gian thực thu được từ các camera. Bài viết này sẽ làm rõ mục tiêu của bài toán Truy vấn người, phân tích các phương pháp tiếp cận dựa trên Học sâu, và trình bày các kết quả thực nghiệm mà nhóm nghiên cứu của chúng tôi đã đạt được.

1. Giới thiệu bài toán tìm kiếm người
Phát hiện người (Person Detection), Theo dõi người (Person Tracking) và Xác định danh tính người (Person Re-identification) là các bài toán phổ biến thuộc lĩnh vực thị giác máy tính, tập trung vào nhiệm vụ trang bị hiểu biết cho máy tính về khả năng xác định vị trí (Localization), phân loại đối tượng (Classification) dựa trên đặc trưng để từ đó triển khai nhiều giải pháp ứng dụng, tiêu biểu có thể kể đến như hệ thống quản lý, giám sát an ninh của tòa nhà văn phòng, khu đô thị, khu vui chơi. Bên cạnh các bài toán và giải pháp ứng dụng vừa nêu, bài toán Truy vấn người đang nhận được nhiều sự quan tâm trong những năm gần đây không những từ cộng đồng nghiên cứu mà còn từ nhu cầu thực tiễn của người dùng cuối/khách hàng có nhu cầu triển khai các giải pháp liên quan đến hệ thống camera giám sát. Ví dụ, người dùng/khách hàng sở hữu một lượng hình ảnh và video rất lớn từ hệ thống camera giám sát, và có nhu cầu trích xuất thông tin các đối tượng xuất hiện trong video/camera như thời gian, địa điểm. Việc trích xuất thông tin này nếu được thực hiện một cách thủ công bằng việc thuê nhân công quan sát kiểm tra từng video/camera sẽ mất rất nhiều thời gian và chi phí, từ đó mà người dùng/khách hàng có nhu cầu sở hữu một giải pháp ứng dụng công nghệ cao để cắt giảm chi phí và tiết kiệm thời gian.
Thông qua thực hiện khảo sát các nghiên cứu gần đây, có hai xu hướng chính để triển khai một giải pháp ứng dụng của bài toán Truy vấn người: một là dựa trên mô tả từ ngữ về đối tượng (text-based) và hai là dựa trên thông tin hình ảnh đối tượng (image-based). Trong phạm vi bài viết này, nhóm chúng tôi tập trung vào xu hướng tìm kiếm người từ nhiều camera dựa trên thông tin hình ảnh của đối tượng. Trước tiên, chúng tôi muốn một lần nữa cùng bạn đọc làm rõ lại một số khái niệm cơ bản về phát hiện người, theo dõi người, xác định danh tính người và truy vấn người làm cơ sở đi sâu hơn nữa vào các phần tiếp theo:
- Phát hiện người hoặc dáng người: mục tiêu chỉ xác định vị trí của người hoặc dáng người trong không gian hình ảnh, nhưng không có khả năng phân biệt danh tính giữa những người khác nhau. Mỗi người sẽ được giới hạn trọn vẹn bởi một hình khung viền hình chữ nhật (bounding box) bao quanh.
- Xác định danh tính: các giải pháp ban đầu đặt mục tiêu xác định danh tính người thông qua các đặc trưng của người đó trong cùng hoặc khác không gian hình ảnh, tuy nhiên không bao gồm tính năng xác định vị trí của người trong không gian, điều này có nghĩa các đặc trưng của người cần định danh phải được trích xuất một cách thủ công bao gồm cả tọa độ người trong không gian hình ảnh. Chính việc trích xuất thủ công đã làm cho bài toán xác định danh tính người không hiệu quả khi ứng dụng thực tế.
- Theo dõi người: có thể hiểu là sự nâng cấp của bài toán phát hiện người và xác định danh tính, ngoài xác định vị trí của người trong không gian hình ảnh, mục tiêu chính của bài toán theo dõi người là duy trì tính kết nối liên tục về thông tin của cùng một đối tượng qua một chuỗi các khung hình liên tục của video. Theo dõi người có 2 bài toán chính: theo dõi nhiều đối tượng (Multi-object Tracking) và theo dõi một đối tượng (Single object Tracking).
- Truy vấn người: tên gọi này xuất phát từ nhu cầu triển khai giải pháp Xác định danh tính vào thực tế, nhóm nghiên cứu của chúng tôi hướng đến việc giải quyết bài toán tìm kiếm người được chỉ định một cách tổng quát bằng cách kết hợp giải hai bài toán là Phát hiện dáng người với Xác định danh tính của họ.
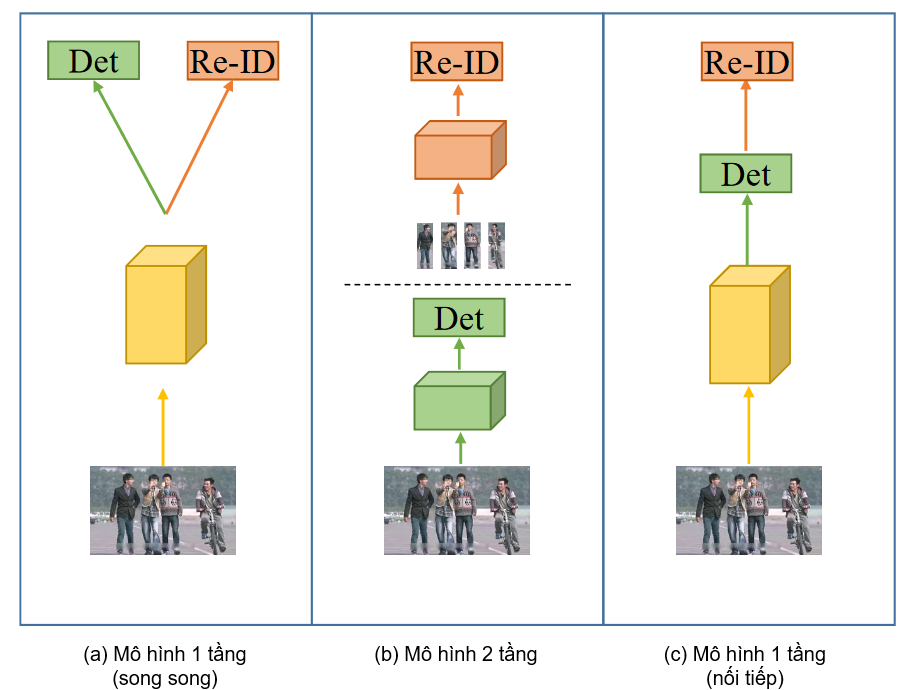
Các phương pháp tiếp cận sớm nhất để giải quyết bài toán xác định danh tính chỉ tập trung vào việc lựa chọn các đặc trưng một cách thủ công thông qua xác định dáng người [1] [2]. Tuy nhiên hướng tiếp cận này chỉ phù hợp với mục đích nghiên cứu, khi đó tập dữ liệu tìm kiếm chỉ chứa các hình ảnh dáng người được cắt ra từ các hình ảnh được gán nhãn trước đó. Điều này dẫn đến thách thức cố hữu trong việc triển khai giải pháp vào thực tế là tập dữ liệu tìm kiếm chứa rất nhiều dáng người khác nhau, điều này làm cho việc trích xuất đặc trưng thủ công là bất khả thi. Giải pháp đơn giản nhất là kết hợp cả 2 tác vụ vào cùng một bộ khung làm việc, sớm nhất có thể kể đến bài báo của Xu và đồng nghiệp [3], tuy nhiên hiệu suất của phương pháp này bị giới hạn bởi các đặc trưng được trích xuất thủ công không dựa trên Học sâu. Một trong những công trình nghiên cứu đầu tiên dựa trên Học sâu giải quyết bài toán Truy vấn người thuộc về Xiao và cộng sự [4], họ đề xuất sử dụng mộ hình Faster R-CNN [5], khi đó mô hình sẽ nhận đầu vào là hình ảnh chứa dáng người, mô hình sẽ đề xuất các vùng trong hình có khả năng chứa dáng người gọi là các vùng đề xuất (Region Proposals) hoặc RoI (Region of Interest). Các vùng đề xuất này sau khi được tạo ra sẽ được xử lý song song cho 2 tác vụ phát hiện dáng người và phân loại danh tính. Thống kê các nghiên cứu gần đây liên quan đến việc kết hợp cả 2 tác vụ dựa trên Học sâu, các tác giả [6] đã chia các cách tiếp cận hiện có thành 2 nhóm chính ở Hình 2.a và 2.b, đồng thời đề xuất một hướng tiếp cận mới ở Hình 2.c. Theo đó, nhóm các phương pháp tiếp cận thứ nhất giải quyết bài toán theo hướng tạo ra một mô hình đa tác vụ (multi-task) hay còn gọi là quy trình đầu cuối (end-to-end), ví dụ điển hình là công trình của Xiao và cộng sự [4]. Tuy nhiên điểm hạn chế của nhóm phương pháp tiếp cận quy trình đầu cuối xử lý song song này là thiếu cơ chế quản lý chất lượng của các vùng đề xuất, kéo theo độ chính xác thấp khi phân loại danh tính dựa trên đặc trưng của các vùng đề xuất. Từ hạn chế này đã dẫn đến sự ra đời của nhóm các phương pháp tiếp cận theo hướng 2 tầng (2-stages) tác vụ độc lập, nghĩa là đầu ra của mô-đun dự đoán dáng người sẽ là đầu vào của mô-đun phân loại đặc trưng, nhóm các phương pháp này nhìn chung có thể giải quyết được hạn chế về chất lượng của các dáng người dự đoán, tuy nhiên vì phải huấn luyện 2 mô hình Học sâu độc lập dẫn đến bất đồng bộ trong việc tối ưu trọng số. Nhận thấy ưu và nhược điểm của nhóm phương pháp tiếp cận đầu tiên, Li và các cộng sự [6] đã đề xuất một phương pháp tiếp cận thứ 3, phương pháp này cũng dựa trên việc huấn luyện một mô hình Học sâu đa tác vụ, nhưng khác với nhóm phương pháp tiếp cận thứ nhất, quá trình xử lý các vùng đề xuất là một chuỗi 2 tác vụ theo thứ tự phát hiện dáng người sau đó là phân loại danh tính.
Như đã đề cập, mục tiêu của bài toán Truy vấn người là triển khai giải pháp của bài toán Xác định danh tính vào thực tế. Để bạn đọc có một cái nhìn tổng quát, chúng tôi đã mô hình hóa các bước xử lý và các thành phần cơ bản ở Hình 1:
- Khi có yêu cầu từ người dùng, một đối tượng tìm kiếm sẽ được định vị tọa độ trong không gian hình ảnh. Hình ảnh ở đây có thể thu được trực tiếp từ hệ thống camera giám sát hoặc gián tiếp từ một thiết bị ghi hình khác.
- Dữ liệu hình ảnh từ hệ thống camera giám sát sẽ tự động trích xuất thông tin đặc trưng của tất cả các dáng người có thể tìm thấy trong không gian hình ảnh để tạo thành bộ sưu tập.
- Một hệ thống tìm kiếm thực hiện đối sánh đặc trưng của đối tượng được chỉ định và các đối tượng tìm thấy trong bộ sưu tập để thu về kết quả là hình ảnh tương tự với người được chỉ định tìm kiếm, từ đó có thể xác định các thông tin liên quan ví dụ như: địa điểm và thời gian đối tượng xuất hiện.
Dựa trên các thành phần cơ bản để giải quyết bài toán Xác định danh tính, nhóm nghiên cứu của Ye và cộng sự [7] đã chỉ ra 2 xu hướng của các phương pháp tiếp cận được trình bày ở Bảng 1, bao gồm: Môi trường đóng và Môi trường mở.
| Môi trường | Dữ liệu | Nhiệm vụ phát hiện dáng người | Nhãn dữ liệu | Phương thức đánh giá |
|---|---|---|---|---|
| Môi trường đóng | Dữ liệu đơn phương thức chỉ gồm hình ảnh tự nhiên và video. | Vị trí dáng người trong không gian hình ảnh được gán nhãn thủ công. Các nhà nghiên cứu giả định rằng họ đã sở hữu một mô-đun hoàn hảo để phát hiện dáng người một cách chính xác nhất. Do đó họ chỉ tập trung nghiên cứu giải quyết bài toán Xác định danh tính dựa trên các dáng người đã khoanh vùng trước đó. | Yêu cầu một lượng dữ liệu đủ để huấn luyện các mô hình học có giám sát. | Các nhà nghiên cứu giả định rằng đối tượng tìm kiếm phải xuất hiện trong bộ sưu tập cơ sở dữ liệu. Do đó có đánh giá tự động dựa trên các tham số về độ chính xác, ví dụ độ chính xác top-k hoặc mAP (chi tiết về các tham số đánh giá sẽ được trình bày ở phần sau). |
| Môi trường mở | Dữ liệu đa phương thức, bên cạnh hình ảnh tự nhiên và video có thể gồm: ảnh hồng ngoại, ảnh tranh vẽ, ảnh độ sâu, và cả văn bản. | Yêu cầu một hệ thống quy trình đầu cuối có thể đề xuất các vị trí dáng người trong không gian hình ảnh, từ đó làm cơ sở trích xuất đặc trưng và đối sánh sự tương tự để giải quyết bài toán Xác định danh tính. | Yêu cầu về chi phí và thời gian để gán nhãn dữ liệu để thực hiện huấn luyện mô hình. | Trên thực tế, đối tượng chỉ định tìm kiếm có thể xuất hiện hoặc không xuất hiện trong bộ sưu tập cơ sở dữ liệu. Do đó chưa có một tham số tổng quát nào để thực hiện đánh giá tự động. |
Dựa trên so sánh ở Bảng 1, chúng tôi chỉ ra các yêu cầu cơ bản của bài toán Truy vấn người, đồng thời giới hạn phạm vi nghiên cứu của bài viết này:
- Dữ liệu: Dữ liệu chỉ bao gồm hình ảnh và video từ các camera giám sát.
- Tác vụ Phát hiện dáng người: Tích hợp mô-đun đề xuất các vị trí dáng người trong không gian hình ảnh.
- Nhãn dữ liệu: Yêu cầu một lượng dữ liệu đủ để huấn luyện mô hình học có giám sát.
- Phương thức đánh giá: Trong quá trình thực nghiệm, chúng tôi xem xét sử dụng 2 bộ dữ liệu công khai là PRW [8] và CUHK-SYSU [9] với giả định rằng đối tượng được chỉ định tìm kiếm phải xuất hiện trong bộ sưu tập.
Những năm gần đây, với sự đóng góp dữ liệu có nhãn từ cộng đồng nghiên cứu, hiệu suất phân loại danh tính người ngày càng được cải thiện. Tuy nhiên, tồn tại một thách thức cố hữu là xung đột tự nhiên khi huấn luyện mô hình đa tác vụ, trong đó mô hình Phát hiện dáng người tập trung vào việc tìm ra điểm chung của các dáng người khác nhau được xem là cận cảnh (foreground), để phân biệt với vùng không chứa người trong không gian hình ảnh gọi là hậu cảnh (background). Trong khi đó, tác vụ Xác định danh tính cố gắng phân biệt những điểm khác nhau giữa các dáng người nhằm mục đích phân loại danh tính. Thách thức làm cho việc huấn luyện mô hình đa tác vụ không được hiệu quả, tuy nhiên như đã đề cập trước đó, các cách tiếp cận theo phương pháp huấn luyện mô hình đa tác vụ lại có ưu thế khi phát hiện dáng người và việc cập nhật trọng số cho mô hình cũng dễ dàng hơn so với các kiến trúc 2 tầng. Như vậy, đòi hỏi các nhà nghiên cứu phải cân nhắc lựa chọn kiến trúc phù hợp để giải quyết bài toán một cách tối ưu nhất.
| Kiến trúc | Mô tả | Ưu điểm | Nhược điểm | Bài báo nổi bật |
|---|---|---|---|---|
| 2 tầng (2-stages) | Chuỗi tác vụ được thực hiện độc lập với nhau, ngõ ra của mô-đun Phát hiện dáng người là ngõ vào của mô-đun Xác định danh tính. | Tránh được sự xung đột tự nhiên khi huấn luyện mô hình đa tác vụ. | Do huấn luyện 2 mô hình học sâu độc lập nên thiếu cơ chế tối ưu một cách đồng bộ. | TCTS (2020) [10] |
| 1 tầng (one-stage) hay quy trình đầu cuối (end-to-end) | Huấn luyện một mô hình duy nhất cho cả 2 tác vụ Phát hiện dáng người và Xác định danh tính. | Sử dụng chung một mạng xương sống để trích xuất đặc trưng cho cả tác vụ Phát hiện dáng người và Xác định danh tính, do đó dễ dàng tối ưu trọng số mô hình và có thể tận dụng thông tin bối cảnh xung quanh dáng người để cải thiện hiệu suất phân loại danh tính. | Bỏ qua sự xung đột tự nhiên giữa 2 tác vụ. | SeqNet (2021) [11]; SeqNeXt+GFN (2022) [12]. |
Dựa trên phân tích ưu và nhược điểm của 2 kiến trúc ở Bảng 2, chúng tôi đã tiến hành thực nghiệm theo hướng kiến trúc 1 tầng là SeqNeXt+GFN được công bố vào năm 2022 bởi Jaffe và cộng sự [12], đây là phương pháp tiên tiến nhất tính đến thời điểm bài viết này được thực hiện. Đặc biệt, các thử nghiệm của chúng tôi đạt được hiệu suất vượt trội hơn hiệu suất được công bố của tác giả trên tập dữ liệu điểm chuẩn công khai là PRW [8], điểm mấu chốt là do tác giả chỉ tập trung vào việc phát triển mô hình Học sâu mà bỏ qua các bước kiểm tra chất lượng dữ liệu đầu vào. Trong quá trình nghiệm thu kết quả, chúng tôi đã tiến hành chấm điểm lại kết quả quá trình suy luận trên tập đánh giá, sau cùng thu được hiệu suất vượt trội hơn xấp xỉ 2% khi sử dụng cùng một cấu hình huấn luyện.
2. Ứng dụng tìm kiếm người từ hệ thống CCTV
Ứng dụng triển khai giải pháp bài toán Truy vấn người vào thực tế sau khi được tích hợp hoàn chỉnh vào hệ thống CCTV sẽ cung cấp một số tính năng cụ thể cho người dùng/khách hàng. Một trong những tính năng cơ bản nhất là tối ưu về thời gian thời gian tìm kiếm đối tượng được chỉ định và giảm chi phí vận hành so với việc duy trì một đội ngũ nhân viên an ninh. Một kết quả tìm kiếm người là hệ thống có thể đưa ra những đề xuất hình ảnh tương tự với đối tượng được chỉ định, thời gian và địa điểm mà đối tượng xuất hiện. Một tính năng khác của hệ thống yêu cầu có sự tương tác nhiều hơn từ người dùng là cần chỉ định khoảng thời gian cụ thể để giới hạn phạm vi tìm kiếm đồng thời nâng cao độ chính xác của kết quả tìm kiếm. Dựa trên mục đích sử dụng của người dùng/khách hàng và địa điểm cần giám sát, chúng tôi đã đề xuất một số kịch bản có thể triển khai hệ thống Truy vấn người như: khu vực công cộng, khu vực riêng tư, và các khu vực yêu cầu có mức độ an ninh cao:
- Trung tâm thương mại và các cửa hàng là các khu vực công cộng do đó thường rất đông đúc và tập trung nhiều người dẫn đến tiềm ẩn nguy cơ không được đảm bảo an ninh. Các công viên hoặc khu vui chơi thường xuất hiện rất nhiều trẻ em, đây là đối tượng rất dễ bị tổn thương. Ngoài mục đích an ninh, các cửa hàng còn có nhu phân tích hành vi người tiêu dùng thông qua một hệ thống giám sát nhằm hỗ trợ nâng cao trải nghiệm khách hàng, mặt khác có thể quản lý nhân viên về thời gian, vị trí làm việc.
- Hiện nay hầu hết các khu đô thị, khu dân cư hiện đại đều được trang bị (hoặc tự trang bị) các camera an ninh cả trong nhà và ngoài trời. Dữ liệu video ghi lại từ các camera này có thể lưu trữ lên tới hàng tuần, tuy nhiên việc muốn trích xuất lịch sử camera, tìm kiếm người, tìm kiếm bằng chứng của một vi phạm nào đó thủ công sẽ mất nhiều thời gian và chi phí nhân công. Tương tự với trẻ em tại các khu vui chơi, người già tại các khu dân cư cũng là đối tượng dễ bị tổn thương nên cần đặc biệt quan tâm.
- Với các khu vực cần đảm bảo an ninh, bảo mật cao, việc ngăn chặn các đối tượng không được cấp phép hoặc có biện pháp giải quyết sự cố đột nhập là yêu cầu bắt buộc. Cụ thể khi phát hiện đối tượng vô tình hoặc cố ý xuất hiện ở khu vực cấm thông qua camera, nhân viên an ninh cần nhanh chóng truy vết để tìm ra vị trí hiện tại của họ để kịp thời xử lý tránh gây hậu quả nghiêm trọng.
Có thể thấy tính năng cơ bản khi tích hợp giải pháp Truy vấn người vào hệ thống CCTV là truy vết đối tượng được chỉ định tìm kiếm thông qua dữ liệu video/camera, một kết quả tìm kiếm là hệ thống sẽ đề xuất các hình ảnh tương tự và các thông tin thời gian, địa điểm mà đối tượng đã xuất hiện. Tính năng cơ bản này cũng là yêu cầu chung của 3 kịch bản tại 3 khu vực đề xuất gồm: khu vực công cộng, khu vực riêng tư và khu vực an ninh/bảo mật cao.
3. Một số phương pháp tiếp cận
Mặc dù mục tiêu của 2 bài toán Truy vấn người và Xác định danh tính có thể khác nhau, nhưng về cơ bản đều tuân thủ 4 giai đoạn như sau:
- Chuẩn bị và thu thập dữ liệu: dữ liệu đầu vào là video từ các camera an ninh, sau khi thu thập có thể thực hiện bước tiền xử lý để tách video thành các hình ảnh độc lập thuận tiện cho quá trình gán nhãn.
- Gán nhãn dữ liệu: nhãn là yếu tố quan trọng nhất trong bất kì bài toán huấn luyện mô hình học có giám sát nào. Nếu các bạn đã quen thuộc hoặc ít nhất đã từng nghe đến bài toán Phát hiện đối tượng, thì có thể đã quen với khái niệm nhãn dữ liệu, nhãn ở đây tức là khung viền hình chữ nhật bao quanh vật thể đang được quan tâm. Trong bài toán Phát hiện dáng người, việc gán nhãn sẽ vẽ một khung viền bao quanh dáng người, sau đó nhãn sẽ được lưu trữ dưới dạng thông tin tọa độ của khung viền hình chữ nhật đó. Với bài toán Xác định danh tính và Truy vấn người, nhãn dữ liệu ngoài khung viền thể hiện vị trí đối tượng trong không gian, còn đi kèm với danh tính của người đó. Ví dụ nhãn của một đối tượng sẽ được lưu trữ dưới dạng: [3,6,20,90,1], khi đó các con số [3,6,20,90] ở đây đại diện cho thông tin tọa độ khung viền trong không gian 2 chiều gồm chiều dài và chiều rộng, giá trị cuối cùng trong chuỗi số đại diện cho danh tính của người đang được gán nhãn là “1”.
- Huấn luyện mô hình: ở bước huấn luyện mô hình học sâu sẽ có sự khác nhau giữa các phương pháp tiếp cận, việc huấn luyện nhằm cập nhật trọng số cho mô hình dựa trên dữ liệu đã được gán nhãn và một mục tiêu cụ thể.
- Suy luận kết quả tìm kiếm: đây là bước cuối cùng để trình bày kết quả cho bài toán được minh họa ở Hình 3. Trong đó, dữ liệu hình ảnh từ hệ thống camera sẽ được mô-đun Phát hiện dáng người suy luận và tạo ra các vùng đề xuất gọi là Bộ sưu tập. Tiếp theo, hình ảnh người chỉ định tìm kiếm và các hình ảnh trong bộ sưu tập đi qua mô-đun Trích xuất đại diện đặc trưng để tạo ra các véc-tơ nhúng. Lần lượt từng véc-tơ trong được tạo ra từ bộ sưu tập sẽ được đối sánh với véc-tơ nhúng của đối tượng cần truy vấn để tính hệ số tương tự. Các hệ số tương tự này được sắp xếp lại theo thứ tự từ cao xuống thấp với ý nghĩa những hình ảnh trong bộ sưu tập thuộc về cùng một danh tính với đối tượng truy vấn sẽ có điểm tương tự cao hơn.

Các công trình nghiên cứu gần đây thường sử dụng một mạng cơ bản (base network) còn gọi là mạng xương sống (backbone) để thực hiện các tác vụ Phát hiện dáng người hoặc Trích xuất đặc trưng. Có nhiều mô hình Học sâu hiện đại có thể sử dụng như một mạng cơ bản, tuy nhiên hầu hết các nghiên cứu liên quan đến bài toán Xác định danh tính và Truy vấn người đều sử dụng mô hình Faster R-CNN [5] thay vì các mạng nơ-ron vượt trội hơn. Mặc dù các mô hình hiện đại như YOLO và các biến thể dựa trên YOLO cho hiệu suất Phát hiện vật thể vượt trội hơn Faster-RCNN [5], nhưng đối với bài toán Xác định danh tính, điểm mấu chốt là đề xuất và trích xuất đại diện đặc trưng của các vùng tiềm năng trong hình ảnh đầu vào. Quá trình trên được thực hiện thông qua một vài khối tích chập đầu tiên trong kiến trúc của Faster-RCNN.
a. Kiến trúc 1 tầng tiêu biểu TCTS – 2020 [10]
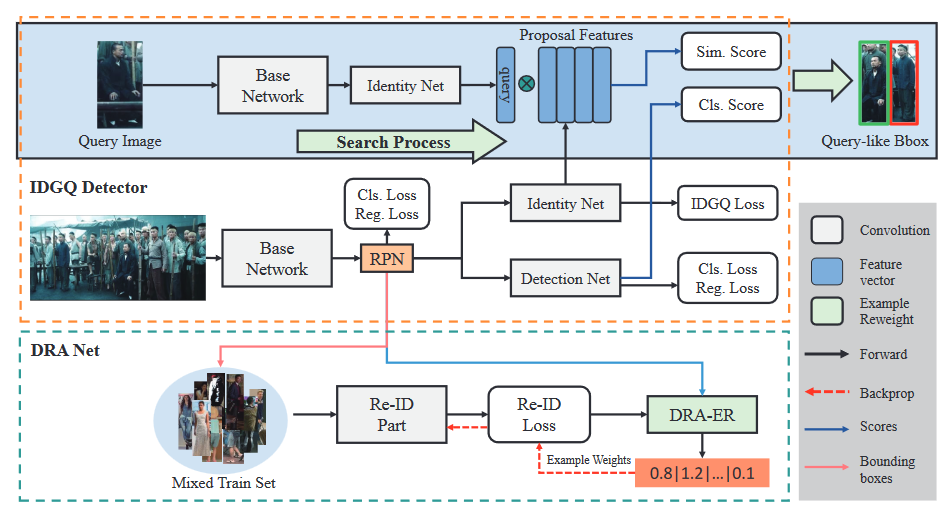
Hầu hết các nhà nghiên cứu tham gia giải quyết bài toán Xác định danh tính chỉ quan tâm đến độ chính xác và khả năng tối ưu tham số cho mô hình Học sâu mà bỏ qua sự xung đột tự nhiên giữa các tác vụ khi xây dựng mô hình đa tác vụ. Nhóm tác giả Wang và cộng sự [10] hướng đến việc giải quyết xung đột này bằng cách đề xuất một bộ khung 2 tầng gọi là TCTS. Hình 4, trình bày giai đoạn (3) Huấn luyện mô hình và (4) Suy luận kết quả tìm kiếm trong 4 giai đoạn cơ bản vừa trình bày bên trên:
- Suy luận kết quả tìm kiếm: nằm trong khối màu xanh, từ một hình ảnh chứa người được chỉ định tìm kiếm cho trước được cho đi qua một loạt các lớp tính toán trích xuất đại diện đặc trưng. Đại diện đặc trưng này sẽ được dùng để tính điểm số tương tự với từng đại diện đặc trưng dáng người trong bộ sưu tập (ngõ ra của khối Identity Net), đầu ra là điểm tương tự “Sim. Score”.
- Huấn luyện mô hình: gồm 2 mô-đun IDGQ và DRA được huấn luyện độc lập theo phương pháp 2 tầng, trong đó mô-đun IDGQ có nhiệm vụ tạo ra các vùng đề xuất có khả năng chứa dáng người, các vùng đề xuất này là đầu vào của mô-đun DRA có nhiệm vụ phân loại danh tính.
Đánh giá hiệu suất phân loại danh tính, bộ khung TCTS [10] đạt độ chính xác top-1 95.1% trên tập CUHK-SYSU [9] và 87.5% trên tập PRW [8]. Mặc dù đạt được các kết quả khả quan, tuy nhiên bộ khung được đề xuất huấn luyện các mô hình Học sâu độc lập, do đó thiếu cơ chế đồng bộ việc tối ưu tham số cho các mô hình.
b. Kiến trúc 2 tầng tiêu biểu Sequential End-to-End Network
SeqNet – 2021 [11]
Như đã đề cập ở Bảng 2, với nhóm các phương pháp quy trình đầu cuối có thể chia thành 2 nhóm phụ là cách tiếp cận theo kiểu song song và kiểu chuỗi, điểm khác nhau cơ bản giữa chúng là thời điểm xử lý tác vụ Phát hiện dáng người và Xác định danh tính, ở đó mô hình song song sẽ xử lý 2 tác vụ đồng thời. Tuy nhiên cách tiếp cận song song có nhược điểm là thiếu cơ chế quản lý chất lượng các dáng người dự đoán và việc trích xuất đặc trưng. Nhóm tác giả Zhengjia và cộng sự [11] đã chứng minh luận điểm này bằng việc so sánh hiệu suất phân loại danh tính giữa mô hình song song và chuỗi từ đó họ đề xuất tiếp cận theo hướng mô hình chuỗi dựa trên một kiến trúc phân tầng cho mô hình Faster R-CNN [5] cơ bản. Điểm đặc biệt ở công việc đề xuất này là tác vụ hồi quy tọa độ dáng người được tính toán lặp lại thêm một lần nữa với mục đích tinh chỉnh từ các tọa độ dự đoán ở lần đầu, điều này giúp nâng cao chất lượng các dáng người dự đoán, đây cũng chính là nhược điểm của mô hình xử lý song song. Sau khi tinh chỉnh, các dáng người được trích xuất thành các đại diện đặc trưng và bắt đầu phân loại danh tính. Tuy nhóm nghiên cứu gọi đây là cách tiếp cận phân tầng luồng xử lý, nhưng không giống với bộ khung TCTS [10], ở SeqNet [11] việc cập nhật các trọng số cho mô hình học sâu đồng thời cho cả tác vụ Phát hiện dáng người và Xác định danh tính thay vì cập nhật từng mô hình một như bộ khung TCTS [10]. Cũng trong công trình này, nhóm tác giả đã đề xuất một thuật toán hậu xử lý gọi là CBGM được áp dụng trong giai đoạn kiểm tra, thuật toán có chức năng tích hợp thông tin bối cảnh từ hình ảnh gốc vào quá trình so khớp các đại diện đặc trưng. Tiến hành thực nghiệm trên 2 tập dữ liệu điểm chuẩn công khai là CUHK-SYSU [9] và PRW [8], mô hình SeqNet [11] đạt độ chính xác top-1 cho tác vụ phân loại danh tính lần lượt là 95.7% và 87.6%.
SeqNeXt+GFN – 2022 [12]
Gần đây, nhóm tác giả Jaffe và Zakhor [12] vừa công bố công trình nghiên cứu về bài toán Truy vấn người, họ chỉ ra rằng một trong những thách thức của hầu hết các bài toán truy vấn thông tin là độ phức tạp của phép toán tìm kiếm sẽ tăng lên khi kích cỡ của không gian tìm kiếm tăng, do đó nhóm nghiên cứu đề xuất kết hợp một mô-đun gọi là GFN vào mô hình SeqNet [11] với mục tiêu làm giảm không gian hình ảnh tìm kiếm bằng cách loại bỏ cách hình ảnh ít liên quan hoặc ít có khả năng xuất hiện người được chỉ định tìm kiếm. Theo đó, mô-đun GFN thực hiện tính toán điểm số ưu tiên giữa hình ảnh người được chỉ định tìm kiếm với từng ảnh trong bộ sưu tập, từ đó quyết định những hình ảnh tìm năng trong bộ sưu tập sẽ được đưa vào bộ phát hiện dáng người. Hình 6 trình bày đường ống cho quá trình suy luận mô hình SeqNeXt+GFN [12] bao gồm hai giai đoạn: 1) Quá trình xử lý của mô-đun GFN, khi đó các hình ảnh có khả năng không chứa đối tượng cần truy vấn sẽ được loại bỏ. 2) Một quy trình truy vấn người cơ bản gồm các bước: Phát hiện dáng người trong bộ sưu tập, Tính toán đại diện đặc trưng cho từng dáng người, Tính toán đại diện đặc trưng cho hình ảnh người được chỉ định tìm kiếm, cuối cùng là Tính toán mức độ tương tự. Ngoài ra, tác giả còn thực hiện điều chỉnh kiến trúc của SeqNet [11] và thay đổi mạng nơ-ron xương sống của mô hình Faster R-CNN [5] từ ResNet-50 [13] thành ConvNeXt [14] nhằm tăng hiệu suất trích xuất đặc trưng. Tuy nhiên, để có cái nhìn khách quan và công bằng giữa SeqNeXt+GFN [12] với các công trình khác, chúng tôi chỉ phân tích kết quả được thực nghiệm với mạng xương sống cơ bản là ResNet-50 [13]. Giống với các công trình trước đó, SeqNeXt+GFN [8] cũng thực nghiệm trên 2 bộ dữ liệu công khai là CUHK-SYSU [9] và PRW [8] đạt độ chính xác phân loại danh tính top-1 lần lượt là 95.3% và 90.6%, với kết quả này SeqNeXt+GFN [12] đang là mô hình tiên tiến nhất hiện nay để giải quyết bài toán Truy vấn người. Như đã đề cập ở trên, mô-đun GFN được thực hiện bên ngoài tác vụ Phát hiện dáng người và Xác định danh tính, do đó GFN được xem như một tác vụ tiền xử lý và có thể tận dụng cho bất kì phương pháp tiếp cận khác của bài toán Truy vấn người.
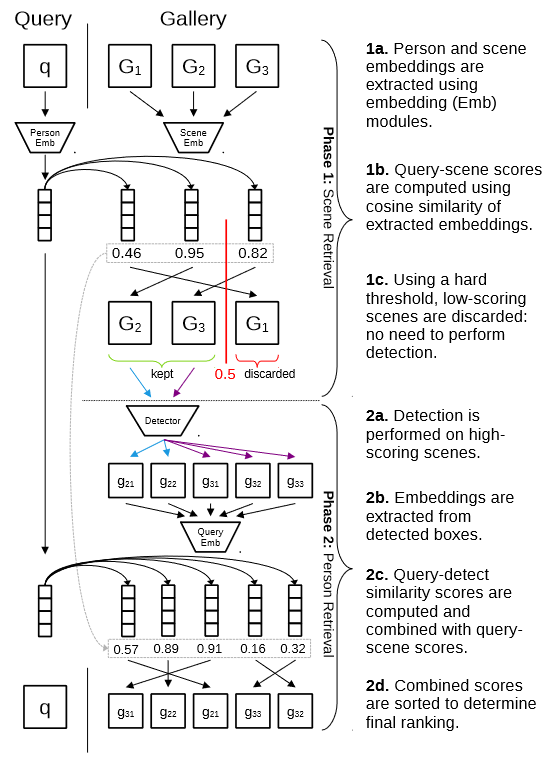
4. Tập dữ liệu và phương pháp đánh giá
Thông thường các tập dữ liệu liên quan đến bài toán Xác định danh tính được chia thành 2 nhóm dựa trên số lượng camera ghi hình: đơn camera (single-camera) và đa camera (multi-camera). Đơn camera nói cách khác là các tập dữ liệu này được thu chỉ với một góc nhìn do đó không có nhiều thách thức nên thường ít được cộng đồng nghiên cứu quan tâm. Mặt khác, các tập dữ liệu được thu từ đa camera hay đa góc nhìn được nhiều sự quan tâm từ cộng đồng do độ phức tạp cao và rất gần với các dữ liệu thực tế, do đó các nhà nghiên cứu tin rằng nếu các phương pháp đề xuất của họ đạt được hiệu suất cao trên các tập dữ liệu này thì rất khả thi để triển khai thành các giải pháp thực tế. Nếu chỉ xét đến bài toán Xác định danh tính, có nhiều tập dữ liệu điểm chuẩn trong những năm gần đây như VIPeR [15], CUHK01 [16],… tuy nhiên hầu các tập dữ liệu này chỉ cung cấp hình ảnh dáng người đã được gán nhãn và cắt ra từ ảnh gốc, do đó không phù hợp với mục tiêu bài toán Truy vấn người như đã đề cập ở phần đầu bài viết. Trong phạm vi nghiên cứu, chúng tôi xem xét 2 tập dữ liệu phù hợp với bài toán Truy vấn người và có nhiều điểm chuẩn đánh giá nhất hiện nay là PRW [8] và CUHK-SYSU [9].
a. Tập dữ liệu
PRW (Person Re-identification in the Wild) [8]
Tập dữ liệu PRW được gán nhãn trên các video từ tập dữ liệu Market-1501, trong đó dữ liệu video được ghi hình từ năm 2014 với 6 camera khác nhau tại trường Đại học Thanh Hoa-Trung Quốc. Về chất lượng video, tất cả các camera đều ghi hình ở tốc độc 25 khung hình/giây, tuy nhiên về độ phân giải hình ảnh không được đồng bộ, trong đó có 5 camera thu hình với độ phân giải HD 1080 x 1920 và 1 camera có độ phân giải HD 576 x 720. Tổng cộng có 11,816 khung hình ảnh được trích xuất và gán nhãn thủ công, trong đó có 34,304 dáng người được vẽ khung tọa độ tương ứng thuộc về 932 danh tính người duy nhất. Như đã đề cập, đây là tập dữ liệu rất gần với các dữ liệu thực tế, điều này có nghĩa sẽ có những dáng người rất khó xác định danh tính vì đứng ở một vị trí không thuận lợi để ghi hình. Với những trường hợp không rõ danh tính, dáng người sẽ được gán nhãn -2, trong khi các danh tính rõ ràng sẽ được gán nhãn từ 1 đến 932. Có thể thấy trong Hình 7, những dáng người rõ danh tính (phía bên trái) theo từng cột sẽ thuộc về cùng một người, những hình ảnh này thu được từ những góc nhìn khác nhau.

CUHK-SYSU [9]
Tập dữ liệu CUHK-SYSU được thu thập và gán nhãn bởi nhóm nghiên cứu thuộc trường Đại học Trung Văn HongKong (CUHK), các hình ảnh trong tập dữ liệu đến từ 2 nguồn chủ yếu là: các khoảnh khắc đường phố và phim. Trong đó các khoảnh khắc đường phố được chụp bằng camera cầm tay bao gồm 12,490 ảnh được gán nhãn tương ứng với 6,057 người có thể xác định danh tính, tuy nhiên số lượng ảnh thuộc về cùng một người không đa dạng, nhưng vẫn đảm bảo tối thiểu 2 ảnh có góc quan sát khác nhau để phục vụ quá trình đánh giá. Nguồn dữ liệu khác đến từ phim ảnh, lý do chính tác giả sử dụng nguồn phim ảnh là vì tính đa dạng góc nhìn mà video phim mang lại, tổng cộng có 5,594 hình ảnh được gãn nhãn tương ứng 2,375 người. Khi thực hiện gán nhãn dữ liệu, nhóm nghiên cứu giả định rằng các dáng người có chiều cao lớn hơn 50 pixels mới được xem xét là đủ chất lượng để tiến hành gán nhãn. Tổng cộng cả 2 nguồn dữ liệu, có tất cả 99,809 dáng người được gán nhãn tương ứng với 8,432 danh tính trong tập dữ liệu CUHK-SYSU [9], một số ví dụ được thể hiện trong Hình 7, ở đó hình ảnh dáng người đầu tiên ở mỗi hàng là người được chỉ định tìm kiếm, và các hình ảnh dáng người bên trong khung viền màu đỏ ở mỗi hàng là người được tìm thấy tương ứng trong bộ sưu tập.

Để người đọc có cái nhìn tổng quan về các tập dữ liệu đã đề cập ở trên, chúng tôi tóm tắt lại ở Bảng 3.
| Tập dữ liệu | Năm công bố | Số lượng danh tính | Số lượng dáng người trung bình/danh tính | Số lượng camera | Số lượng nghiên cứu đã thực hiện trong năm 2021 | Số lượng nghiên cứu đã thực hiện trong năm 2022 |
|---|---|---|---|---|---|---|
| PRW [8] | 2017 | 932 | 36.81 | 6 | 19 | 13 |
| CUHK-SYSU [9] | 2017 | 8,432 | 2.77 | – | 23 | 23 |
b. Tham số đánh giá
Như đã mô tả về cách một hệ thống Truy vấn người hoạt động ở Hình 3, có 2 mô-đun xử lý tính toán cơ bản là: Phát hiện dáng người, và Xác định danh tính người. Trong đó, mỗi mô-đun sẽ có các tham số đánh giá hiệu suất khác nhau:
- Phát hiện dáng người: đây là một tác vụ thuộc về bài toán Phát hiện vật thể nên cộng đồng nghiên cứu thường sử dụng hệ số AP (Average Precision) và Recall để đánh giá.
- Xác định danh tính: đây là một tác vụ thuộc về bài toán Truy hồi thông tin (Information Retrieval), do đó có 2 hệ số mAP (mean Average Precision) và độ chính xác top-k có thể đại diện cho hiệu suất phân loại danh tính.
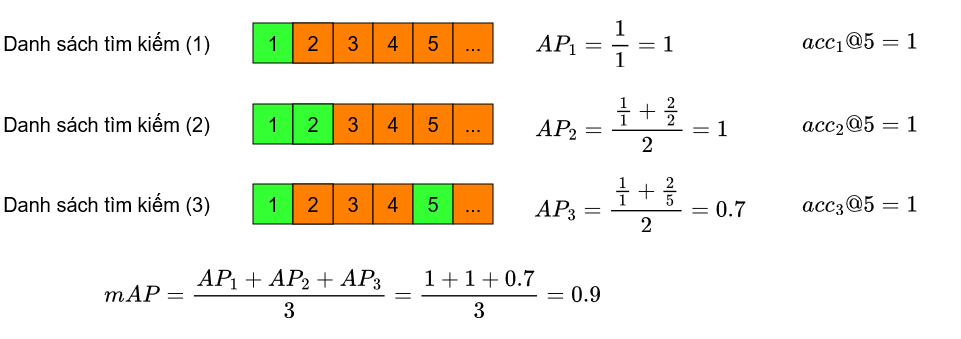
Với bài toán Truy vấn người, hiệu suất đánh giá sau cùng dựa trên độ chính xác tìm ra được các dáng người tương tự với người được chỉ định tìm kiếm từ bộ sưu tập nên chúng tôi chỉ trình bày chi tiết cách tính các hệ số hiệu suất ở tác vụ Xác định danh tính. Hình 9 trình bày một ví dụ đơn giản đánh giá hiệu suất bài toán Truy hồi thông tin, sau khi đối sánh điểm số tương tự giữa mẫu cần truy vấn với các mẫu có trong cơ sở dữ liệu, phép toán sắp xếp được thực hiện để xếp lại các mẫu có điểm số đối sánh cao sẽ được xếp lên trên các mẫu có điểm đối sánh thấp tạo thành một danh sách kết quả tìm kiếm. Các ví dụ ở Hình 9 minh họa với 5 mẫu có điểm số đối sánh cao nhất, với các ô màu xanh là các mẫu thông tin sự thật (ground truth) được tìm thấy trong bộ sưu tập hay còn gọi là các mẫu dương tính (positive), còn các ô màu cam là các mẫu thông tin sai hay còn gọi là các mẫu âm tính (negative). Bên trong mỗi ô được đánh số từ 1 đến 5 để chỉ mức độ ưu tiên trong danh sách, nói cách khác thứ tự ưu tiên dựa vào kết quả dự đoán điểm tương đồng (similarity score), các ô kết quả được sắp xếp theo thứ từ 1 đến 5 (top-5) giảm dần theo điểm tương đồng.
Độ chính xác top-k (acc@k)
Nếu có ít nhất 1 mẫu tìm thấy thuộc về thông tin sự thật trong “k” mẫu thông tin có điểm số tương tự cao nhất thì chuỗi thông tin tìm thấy đó được tính là đúng. Trong Hình 9, ví dụ đang xem xét với 5 mẫu thông tin có điểm tương tự cao nhất, trong đó cả 3 chuỗi (1), (2) và (3) đều có mẫu thông tin dương tính xuất hiện, do đó có thể nói rằng độ chính xác top-5 của 3 chuỗi đều bằng 1.
Hệ số độ chính xác top-k không phản ánh được số lượng và thứ tự của các mẫu thuộc về thông tin sự thật trong chuỗi truy vấn nhưng phù hợp dùng để giải thích cho khách hàng về kết quả dự đoán của hệ thống.
AP (Average Precision) và mAP (mean Average Precision)
Hệ số AP thường được sử dụng để đo lường hiệu suất truy hồi thông tin dựa trên thứ tự, khi có nhiều hơn một thông tin sự thật (ground truth) trong bộ cơ sở dữ liệu tìm kiếm. Đối với bài toán Truy vấn người, đối tượng hoàn toàn có thể xuất hiện tại nhiều vị trí camera tại các thời điểm khác nhau nên việc có nhiều hơn một thông tin sự thật nghĩa là có nhiều hơn một hình ảnh dáng người tương tự với người được chỉ định tìm kiếm trong bộ sưu tập là hoàn toàn hợp lý.
Hình 9 trình bày một ví dụ về cách tính các hệ số độ chính xác (precision), độ chính xác trung bình AP, và giá trị trung bình độ chính xác của nhiều chuỗi mAP:
- Độ chính xác: là một phép chia có tử số là phép cộng tích lũy của các mẫu được tìm thấy là mẫu dương tính và mẫu số là phép cộng tích lũy số lượng mẫu đã duyệt qua. \(P_{i} = \frac{\sum_{1}^{i} S_{positive}}{i}\) . Trong đó i là index của của mẫu đang được xét và Spositive chỉ những mẫu dương tính đã xuất hiện.
- Độ chính xác trung bình AP: là giá trị trung bình cộng các độ chính xác đo được tại các mẫu tìm thấy mẫu dương tính. \(AP = \frac{1}{N_{pos}} \sum_{i \in {pos}}^{} P_{i}\). Trong đó i là index của những mẫu dương tính; P là độ chính xác của mỗi mẫu dương tính; và N là tổng số mẫu dương tính.
- Giá trị trung bình độ chính xác mAP: là giá trị trung bình AP của tất cả các danh sách đang được đánh giá.
Xét danh sách tìm kiếm (2) trên Hình 9, có 2 mẫu dương tính trong tập dữ liệu tìm kiếm lần lượt ở các vị trí 1 và 2 trong 5 mẫu có điểm tương đồng cao nhất. Lần lượt tính độ chính xác cho từng mẫu ta có:
\(P_{1} = \frac{\sum_{1}^{1} S_{positive}}{1} = \frac{1}{1}\)
\(P_{2} = \frac{\sum_{1}^{2} S_{positive}}{2} = \frac{2}{2}\)
Sau khi đã tính được độ chính xác của mỗi mẫu dương tính, độ chính xác trung bình cho tất cả mẫu dương tính trong danh sách tìm kiếm là:
\(AP_{2} = \frac{1}{2} \sum_{[1,2]}^{} P_i = \frac{P_1 + P_2}{2} = \frac{\frac{1}{1}+\frac{2}{2}}{2} = 1 \)
c. Phương thức đánh giá
Như đã đề cập ở các phần trên về sự ra đời của cách tiếp cận SeqNeXt+GFN [12] nhằm mục đích tối ưu luồng xử lý trong giai đoạn suy luận của mô hình tìm kiếm vì lượng thông tin hình ảnh trong cơ sở dữ liệu là vô cùng lớn và chứa rất nhiều thông tin dư thừa dẫn đến lãng phí tài nguyên phần cứng và mất nhiều thời gian tính toán. Nói cách khác, không gian tìm kiếm cũng là một trong những nguyên nhân làm giảm hiệu suất của tác vụ Xác định danh tính. Hình 10 minh họa luồng dữ liệu cơ bản cho bài toán Truy vấn người, từ một tập dữ liệu ban đầu, việc chia dữ liệu thành tập huấn luyện và tập đánh giá là cần thiết với bất kì bài toán nào liên quan đến học máy. Điều đặc biệt với bài toán Truy vấn người nằm ở luồng đánh giá mô hình AI, khi đó tập dữ liệu đánh giá được chia thành tập truy vấn và bô sưu tập tương ứng với cột bên trái và cột bên phải ở Hình 8.
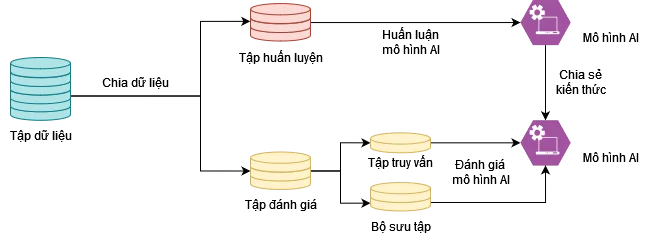
Tính đến trước khi tập dữ liệu CUHK-SYSU [9] được công bố, các công trình nghiên cứu trước đây với bài toán Truy vấn người không phân biệt giữa tập đánh giá và bộ sưu tập. Nói cách khác, không gian tìm kiếm với mỗi mẫu trong tập truy vấn lúc này là toàn bộ tập đánh giá. Tác giả Xiao và cộng sự [9] đã định nghĩa về cách xây dựng bộ sưu tập nhằm xem xét ảnh hưởng của kích thước bộ sưu tập đến quá trình suy luận của mô hình AI, theo các bước sau:
- Chia tập dữ liệu thành tập huấn luyện và tập đánh giá với điều kiện không có hình ảnh hoặc danh tính người bị trùng lặp giữa 2 tập.
- Chia tập đánh giá thành tập truy vấn và bộ sưu tập, với mỗi mẫu trong tập truy vấn được xem như một dáng người được chỉ định tìm kiếm, khi đó mỗi mẫu truy vấn sẽ có một bộ sưu tập tương ứng và phân biệt. Bộ sưu tập phải chứa ít nhất một dáng người cùng danh tính với mẫu truy vấn gọi là mẫu dương tính, các hình ảnh còn lại trong bộ sưu tập không chứa dáng người cùng danh tính với mẫu truy vấn gọi là các mẫu âm tính được chọn ngẫu nhiên từ tập đánh giá.
Từ 2 bước cơ bản như trên, nhóm nghiên cứu [9] thực hiện chia dữ liệu và tạo các môi trường đánh giá khác nhau tương ứng với bộ sưu tập có nhiều kích cỡ 50, 100, 500, 1000, 2000, và 4000 ảnh. Lấy ví dụ với bộ sưu tập có 50 hình ảnh trong đó có 5 hình ảnh chưa mẫu dương tính và phần còn lại là các mẫu âm tính, giả sử ở mỗi hình ảnh có thể phát hiện được 5 dáng người, tổng không gian tìm kiếm lúc này là 50 x 5 = 250 dáng người. Lúc này mô-đun tìm kiếm sẽ thực hiện đối sánh mẫu truy vấn trong tổng số 250 mẫu để tìm ra được 5 mẫu dương tính. Kết hợp với 2 hệ số đánh giá đã trình bày ở trên là AP và độ chính xác top-k với k = 5 thì chỉ cần 1 trong 5 mẫu dương tính này có điểm tương tự với mẫu truy vấn nằm trong top 5 điểm số cao nhất thì độ chính xác của trường hợp truy vấn này là 1.0, còn với hệ số mAP cần phải xem xét thêm yếu tố có bao nhiêu mẫu dương tính được tìm thấy và thứ tự của chúng để tính được điểm AP chính xác.
5. Thực nghiệm mô hình SeqNeXt+GFN
Dựa trên việc phân tích ưu và nhược điểm của công trình liên quan, nhóm chúng tôi quyết định chọn phương pháp tiếp cận cho kết quả tiên tiến nhất hiện nay là SeqNeXt+GFN [12], phần tiếp theo của bài viết sẽ đi sâu vào phân tích chức năng các khối trong mô hình, đặc biệt là mô-đun GFN. Như đã đề cập ở phần trước, mô hình SeqNeXt+GFN [12] kế thừa lại kiến trúc của mô hình SeqNet [11], do đó chúng tôi cũng sẽ phân tích ngắn gọn về SeqNet [11].
a. Sequential End-to-End Network (SeqNet)
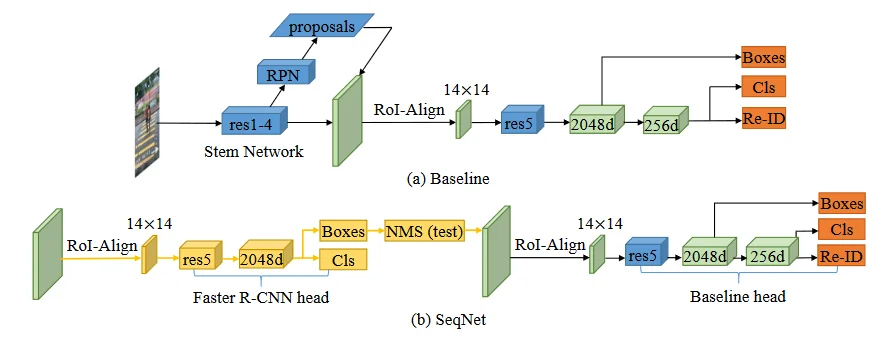
Mạng nơ-ron xương sống của mô hình SeqNet [11] là mô hình phát hiện vật thể Faster R-CNN [5]. Ở đây tác giả sử dụng các lớp tích chập của Faster R-CNN để trích xuất đặc trưng từ hình ảnh đầu vào, cụ thể tác giả chỉ sử dụng 4 khối tích chập đầu tiên, lưu ý: khối tích chập là tập hợp của nhiều lớp tích chập, và ngõ ra là một véc-tơ đặc trưng đại diện có kích thước là 1024 chiều. Một mạng đề xuất khu vực RPN (Region Proposal Network) được đặt nối tiếp sau các khối tích chập để nhận các véc-tơ đặc trưng vào và tạo ra các khu vực đề xuất. Trực quan hóa của các khu vực đề xuất chính là tọa độ các vùng trong ảnh có khả năng chứa vật thể đang được quan tâm, như vậy có thể thấy từ một hình ảnh đầu vào sẽ được mạng RPN tạo ra rất nhiều các khu vực đề xuất có thể trùng lặp với nhau hoặc không chứa đối tượng dẫn đến dư thừa thông tin. Do đó, cần một thuật toán loại bỏ những khu vực đề xuất bị trùng lặp, phổ biến nhất là NMS (Non Maximum Suppression), trong thiết lập mô hình SeqNet [11] chỉ giữ lại tối đa 128 khu vực đề xuất, các khu vực đề xuất này sau đó sẽ được căn chỉnh về cùng kích thước không gian 2 chiều. Tiếp theo, các khu vực đề xuất sẽ đi qua khối tích chập thứ 5 để trích xuất thành các véc-tơ đại diện đặc trưng có 2048 chiều, và cuối cùng được ánh xạ về còn 256 chiều. Với các đại diện đặc trưng 2048 chiều được khai thác sử dụng cho việc hồi quy định vị tọa độ đối tượng trong không gian hình ảnh, còn các đại diện đặc trưng 256 chiều được sử dụng cho tác vụ phân loại danh tính. Với các mô hình quy trình đầu cuối, thì đến đây có thể thu kết quả ngõ ra của mô hình, tuy nhiên với SeqNet [11], các khối xử lý liên quan đến khu vực đề xuất sẽ được lặp lại thêm một lần nữa với mục đích tinh chỉnh. Chi tiết xem lại Hình 5.
b. Gallery Filter Network (GFN)
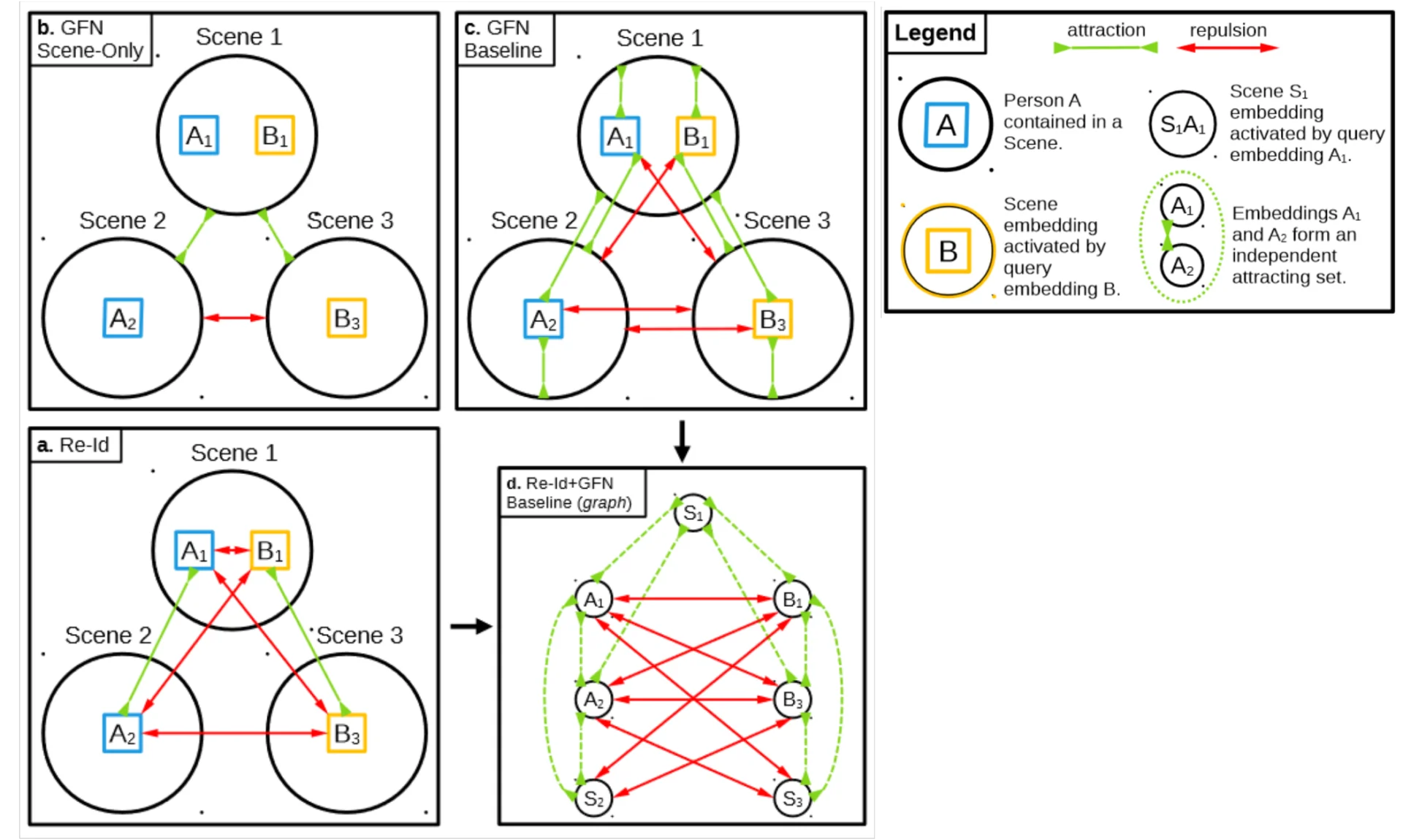
Điểm mấu chốt giúp cho mô hình đề xuất SeqNeXt+GFN [12] đang là mô hình tiên tiến nhất hiện nay để giải quyết bài toán Truy vấn người chính là khối tiền xử lý GFN với chức năng chính là giảm không gian hình ảnh tìm kiếm trong bộ sưu tập. Thuật toán GFN thực hiện véc-tơ hóa hình ảnh cần truy vấn và các hình ảnh trong bộ sưu tập thành các véc-tơ nhúng (embedding), từ đó làm cơ sở để kéo véc-tơ nhúng của các hình ảnh chứa dáng người thuộc về danh tính của người cần truy vấn lại gần với véc-tơ nhúng của mẫu truy vấn, đồng thời đẩy các véc-tơ nhúng của các hình ảnh còn lại ra xa. Có hai khái niệm cần được quan tâm khi phân tích thuật toán GFN:
- Các cặp dương tính (Positive pairs): để chỉ những dáng người thuộc cùng một danh tính ở những ảnh khác nhau, các cặp này cần được kéo lại gần nhau trong quá trình huấn luyện.
- Các cặp âm tính (Negative pairs): để chỉ những dáng người khác danh tính có thể trong cùng hoặc khác ảnh, các cặp này cần được đẩy ra xa nhau trong quá trình huấn luyện.
Trong quá trình huấn luyện, môt hàm mất mát để thực hiện kéo và đẩy các véc-tơ nhúng là một hàm phân loại cơ bản cross-entropy. Chi tiết về các cặp dương tính và âm tính được trình bày ở Hình 11, trong đó các vòng tròn thể hiện các hình ảnh gốc có thể chứa một hoặc nhiều dáng người có danh tính khác nhau, trong ví dụ này đang có 2 danh tính phân biệt nhau là A và B. Từ bảng ghi chú có thể thấy các đường màu xanh lá đang kết nối các véc-tơ nhúng thuộc cùng danh tính và có xu hướng kéo lại gần nhau, trong khi các đường màu đỏ đang kết nối các véc-tơ nhúng khác danh tính và có xu hướng bị đẩy ra xa nhau. Hình 11.a thể hiện quá trình huấn luyện mô hình AI dựa trên mục tiêu phân loại các dáng người với nhau, trong khi mục tiêu phân loại của hình 11.b là giữa các hình ảnh gốc với nhau, đây là trường hợp đặc biệt, đường kết nối màu đỏ chỉ xuất hiện nếu giữa hai ảnh chứa toàn danh tính khác nhau, nếu có ít nhất một danh tính chung giữa hai ảnh thì mục tiêu huấn luyện phải là kéo chúng lại gần nhau. Hình 11.c minh họa một mục tiêu huấn luyện dựa trên GFN cơ bản, khi đó các véc-tơ nhúng không phân biệt là ảnh gốc hay ảnh cắt dáng người, sẽ được xem xét mối quan hệ với nhau từng đôi một tương tự các trường hợp trên. Cuối cùng, kết hợp giữa một hàm huấn luyện dựa trên mục tiêu phân loại dáng người cơ bản với mục tiêu GFN sẽ cho ra kết quả như Hình 11.d.
c. Hàm mất mát
Bất kì tác vụ huấn luyện mô hình AI nào cũng cần phải có mục tiêu huấn luyện, mục tiêu ở đây được hiểu là nếu mô hình cho ra kết quả đúng với nhãn dữ liệu thì sẽ được “thưởng” và ngược lại mô hình sẽ bị “phạt”, đó là cơ sở lý thuyết của hàm mất mát. Xét về bản chất bài toán Xác định danh tính được xem xét như một tác vụ phân loại tương tự với các bài toán phân loại chó-mèo (phân loại 2 lớp), khi đó số lớp của bài toán phân loại danh tính dựa trên số lượng danh tính được gán nhãn. Các phương pháp tiếp cận ban đầu sử dụng hàm mất mát cross-entropy để phân loại, tuy nhiên những nghiên cứu gần đây đạt được hiệu suất vượt trội đã sử dụng một hàm mất mát mới có tên là OIM (Online Instance Matching). Ý tưởng cơ bản của hàm mất mát OIM dựa trên một bảng tìm kiếm (lookup table), ở đó bảng tìm kiếm sẽ lưu trữ véc-tơ nhúng của hình ảnh gốc và hình ảnh cắt dáng người được tạo ra từ vòng lặp huấn luyện trước đó, các véc-tơ nhúng này sẽ được cập nhật vào bảng tìm kiếm sau mỗi vòng huấn luyện. Về mặt toán học, hàm mất mát OIM vẫn dựa trên ý tưởng từ cross-entropy, do đó bạn đọc có thể thấy công thức giữa OIM và cross-entropy khá giống nhau, tuy nhiên OIM là một hàm phi tham số (non-parametric). Hạn chế của hàm cross-entropy khi giải quyết bài toán Xác định danh tính là khi số lượng danh tính trong tập dữ liệu tăng lên, nhưng số lượng hình ảnh của mỗi danh tính không đủ nhiều, lúc này mô hình Học sâu không đủ khả năng để học một lượng lớn các đặc trưng phân biệt đồng thời, ngoài ra bộ phân loại của mô hình phải đối mặt với phương sai độ dốc (variance of gradients) lớn, kết quả là việc huấn luyện mô hình không hiệu quả.
d. Thiết lập thực nghiệm
Như đã đề cập ở phần trên, để đánh giá các phương pháp tiếp cận khác nhau một cách công bằng, chúng tôi quyết định chỉ thử nghiệm mạng nơ-ron xương sống là ResNet-50 [13] trong mô hình Phát hiện dáng người Faster R-CNN [5]. Cảm ơn tác giả [12] đã công bố kho mã nguồn cho công trình SeqNeXt+GFN [12], dựa trên đó nhóm chúng tôi thực hiện cấu hình các siêu tham số như sau:
| Mô tả siêu tham số | Giá trị |
|---|---|
| Hàm tối ưu | SGD |
| Tốc độ học khởi tạo | 3e-3 |
| Số vòng lặp huấn luyện | 30 |
| Số lượng mẫu đi vào mô hình tại một thời điểm | 8 |
| Kích thước véc-tơ nhúng | 2048 |
| Độ phân giải của ảnh sau khi chuẩn hóa | 512 x 512 |
Chi tiết về sự suy giảm hàm mất mát cho tác vụ phân loại danh tính trên tập huấn luyện của bộ dữ liệu PRW [8] được thể hiện ở Hình 12. Chúng tôi chỉ trực quan hóa các giá trị của hàm mất mát cho tác vụ phân loại danh tính trên tập huấn luyện để xác nhận mô hình Học sâu đang học được các đặc trưng ảnh dẫn đến các giá trị của hàm mất mát sẽ giảm dần qua các vòng lặp của quá trình huấn luyện.

Phân tích một số kết quả tìm kiếm dựa trên các mẫu phân loại có điểm tương tự cao nhất so với mẫu truy vấn (top-1) được trực quan hóa ở Hình 13 trên 2 tập dữ liệu CUHK-SYSU [9] (bên trái) và PRW [8] (bên phải). Trong đó, đối tượng truy vấn được minh họa bởi khung viền màu vàng, những mẫu phân loại sai danh tính (khung viền màu đỏ) được suy luận khi không sử dụng mô-đun GFN, trong khi các mẫu phân loại đúng danh tính (khung viền màu xanh) là kết quả suy luận khi kết hợp mô-đun GFN. Có thể kết luận rằng kiến trúc SeqNeXt+GFN [12] tốt hơn so với khi không sử dụng mô-đun GFN.
Sau quá trình huấn luyện, chúng tôi tiến hành đánh giá mô hình SeqNeXt+GFN [12] trên tập dữ liệu PRW [8] và đạt được hiệu suất Xác định danh tính tương tự với kết quả được công bố. Tuy nhiên, sau khi trực quan hóa kết quả như Hình 14, chúng tôi nhận ra hầu hết các trường hợp không tìm thấy các dáng người tương tự với mẫu người được chỉ định tìm kiếm trong bộ sưu tập không hẳn là do mô hình không thể phân biệt mà đến từ 2 nguyên nhân chính:
- Dáng người bị gán nhãn thiếu: người gán nhãn không vẽ khung viền và không gán danh tính một số dáng người. Với trường hợp bị thiếu gán nhãn dáng người và danh tính như Hình 14.1, ở đó đối tượng tượng được tìm thấy trong bộ sưu tập (b) và đối tượng truy vấn (a) thuộc về cùng một người, tuy nhiên khi kiểm tra nhãn sự thật (c) thì dáng người này không được người gán nhãn vẽ khung và đương nhiên cũng không gán danh tính. Điều này có thể lý giải với lý do người gán nhãn cho rằng đối tượng này đang bị che khuất bởi một đối tượng khác, cho nên dáng người này không đủ chất lượng để gán nhãn.
- Bất đồng bộ trong việc gán danh tính: những dáng người thuộc về cùng một người nhưng lại được gán nhiều danh tính khác nhau, hoặc những dáng người thuộc những người khác nhau lại bị gán nhầm về cùng một danh tính. Ở Hình 14.2, đối tượng được tìm thấy (b) và đối tượng truy vấn (a) cũng thuộc về cùng một người, tuy nhiên khi kiểm tra nhãn sự thật (c) thì dáng người này lại được gán danh tính (ID) là 691 không khớp với danh tính (ID) 784 của người được chỉ định tìm kiếm. Đây cũng là một nguyên nhân có thể dự đoán từ trước, việc gán nhãn các tập dữ liệu được ghi hình từ đa góc nhìn hay còn gọi là đa camera mất rất nhiều thời gian và chi phí, cho nên việc gán nhầm danh tính là có thể xảy ra.
Từ đó, chúng tôi kết luận rằng tập dữ liệu công khai PRW [8] tồn tại rất nhiều nhiễu và cần được làm sạch, tuy nhiên do hạn chế về nhân lực và thời gian, chúng tôi chỉ tiến hành làm sạch dữ liệu trên tập đánh giá và tiến hành đánh giá lại. Kết quả đánh giá của chúng tôi đạt độ chính xác top-1 là 92.4%, kết quả này vượt trội hơn con số được công bố của tác giả [8] là 90.6%.

Lời kết
Thông qua bài viết này, chúng tôi đã làm rõ mục tiêu khi triển khai bài toán Xác định danh tính vào thực tế bằng cách thay đổi tên gọi một cách chính xác và đầy đủ hơn là Tìm kiếm người từ nhiều camera hay Truy vấn người. Dựa trên các tài liệu tham khảo, chúng tôi đã chỉ ra 4 giai đoạn cơ bản khi giải quyết một bài toán Truy vấn người: Chuẩn bị và thu thập dữ liệu, Gán nhãn dữ liệu, Huấn luyện mô hình, cuối cùng là Suy luận kết quả tìm kiếm. Đặc biệt, khi đánh giá hiệu suất của các phương pháp tiếp cận, chúng tôi đã phân tích ảnh hưởng của việc cần xây dựng một tập truy vấn và bộ sưu tập dựa trên tập đánh giá. Ở quá trình thực nghiệm, chúng tôi đã tái hiện thành công kho mã nguồn của phương pháp tiên tiến nhất hiện nay là SeqNeXt+GFN [12] trên 2 bộ dữ liệu PRW [8] và CUHK-SYSU [9]. Thông qua thực nghiệm, các nhà nghiên cứu [12] chỉ ra rằng sự gia tăng kích thước không gian tìm kiếm là nguyên nhân chính dẫn đến suy giảm hiệu suất với mọi bài toán truy hồi thông tin, từ đó họ đề xuất một mô-đun gọi là GFN với chức năng loại bỏ những hình ảnh có khả năng không chứa đối tượng cần truy vấn giúp làm giảm số lượng dáng người được đề xuất, dẫn đến giảm kích thước của không gian tìm kiếm. Đáng chú ý, trong quá trình nghiệm thu kết quả, chúng tôi phát hiện bộ dữ liệu PRW bị nhiễu nhãn dữ liệu trên tập đánh giá. Sau khi tiến hành chấm điểm lại kết quả truy vấn, độ chính xác của tác vụ phân loại danh tính vượt trội hơn con số được công bố xấp xỉ 2%.
Tài liệu tham khảo
[1] Gray, D., Tao, H. (2008). Viewpoint Invariant Pedestrian Recognition with an Ensemble of Localized Features. In: Forsyth, D., Torr, P., Zisserman, A. (eds) Computer Vision – ECCV 2008
[2] M. Farenzena, L. Bazzani, A. Perina, V. Murino and M. Cristani, “Person re-identification by symmetry-driven accumulation of local features,” 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 2010, pp. 2360-2367
[3] Xu, Y., Ma, B., Huang, R., & Lin, L. (2014). Person Search in a Scene by Jointly Modeling People Commonness and Person Uniqueness. Proceedings of the 22nd ACM international conference on Multimedia.
[4] Xiao, Tong & Li, Shuang & Wang, Bochao & Lin, Liang & Wang, Xiaogang. (2017). Joint Detection and Identification Feature Learning for Person Search. 3376-3385. 10.1109/CVPR.2017.360.
[5] S. Ren, K. He, R. Girshick and J. Sun, “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks,” in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, no. 6, pp. 1137-1149, 1 June 2017, doi: 10.1109/TPAMI.2016.2577031.
[6] Li, Zhengjia and Duoqian Miao. “Sequential End-to-end Network for Efficient Person Search.” AAAI Conference on Artificial Intelligence (2021).
[7] Ye, Mang & Shen, Jianbing & Lin, Gaojie & Xiang, Tao & Shao, Ling & Hoi, Steven. (2021). Deep Learning for Person Re-Identification: A Survey and Outlook. IEEE Transactions on Pattern Analysis and Machine Intelligence. PP. 1-1. 10.1109/TPAMI.2021.3054775.
[8] L. Zheng, H. Zhang, S. Sun, M. Chandraker, Y. Yang and Q. Tian, “Person Re-identification in the Wild,” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 2017, pp. 3346-3355, doi: 10.1109/CVPR.2017.357.
[9] Xiao, Tong et al. “End-to-End Deep Learning for Person Search.” ArXiv abs/1604.01850 (2016).
[10] C. Wang, B. Ma, H. Chang, S. Shan and X. Chen, “TCTS: A Task-Consistent Two-Stage Framework for Person Search,” 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
[11] L. Zhengjia and D. Miao, “Sequential End-to-end Network for Efficient Person Search,” AAAI Conference on Artificial Intelligence, 2021.
[12] L. Jaffe and A. Zakhor, “Gallery Filter Network for Person Search”, arXiv preprint arXiv: 2210.12903, 2022.
[13] K. He, X. Zhang, S. Ren and J. Sun, “Deep Residual Learning for Image Recognition,” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 2016, pp. 770-778, doi: 10.1109/CVPR.2016.90.
[14] Liu, Zhuang & Mao, Hanzi & Wu, Chao-Yuan & Feichtenhofer, Christoph & Darrell, Trevor & Xie, Saining. (2022). A ConvNet for the 2020s.
[15] Gray, Douglas & Tao, Hai. (2014). Viewpoint Invariant Pedestrian Recognition (VIPeR) Dataset v1.0.
[16] Li et al. Human Reidentification with Transferred Metric Learning. ACCV 2012.