CCTV – Tính năng ước lượng mật độ và đếm đám đông
Ước lượng mật độ và đếm đám đông
(Crowd counting and crowd density estimation)
Việc ước tính mật độ đám đông có ý nghĩa quan trọng đối với các ứng dụng như giám sát an ninh, kiểm soát đám đông đưa ra những cảnh báo bất thường sớm, hơn nữa số liệu thu được từ quá trình ước lượng đám đông có thể giúp tối ưu kinh doanh, quy hoạch không gian. Cùng với sự phát triển nhanh chóng của lĩnh vực Trí tuệ nhân tạo (Aritificial Intelligence – AI), bài toán ước lượng mật độ và đếm đám đông thu hút sự chú ý của đông đảo cộng đồng nghiên cứu Thị giác máy tính (Computer Vision – CV) bởi tính cấp thiết, nhu cầu thực tế từ khách hàng cũng như những thách thức cần lời giải trong vấn đề dữ liệu và hướng tiếp cận.
Bài viết ra đời nhằm mục đích cùng bạn đọc làm rõ thêm về bài toán và tìm hiểu một ví dụ về hướng tiếp cận hồi quy sử dụng mô hình end-to-end Transformer. Theo nhóm tác giả [1], hướng tiếp cận này không chỉ giải quyết tốt bài toán ước lượng/đếm đám đông mà còn cung cấp thêm thông tin vị trí của các đối tượng tạo tiền đề cho một số ứng dụng cao hơn như phân tích, tối ưu không gian, tài nguyên.
1. Giới thiệu bài toán
1.1 Định nghĩa

Ước lượng mật độ và đếm đám đông (sau đây gọi tắt là: ước lượng đám đông) nhận đầu vào là một hình ảnh hoặc khung hình từ video (frame) và trả ra kết quả là số lượng người xuất hiện trong bức hình như hình 1. Ngoài ra, tùy theo hướng tiếp cận mà kết quả của mô hình có thể cung cấp thông tin các box chứa đối tượng (thông thường là box khoanh vùng phần đầu do đối tượng bị che khuất nhiều), bản đồ mật độ (density map), hoặc các điểm có người xuất hiện (point-level). Đây là bài toán hẹp trong nhóm bài toán đếm đối tượng. Một số ví dụ khác của nhóm bài toán này có thể kể đến: đếm phương tiện giao thông [2], đếm đối tượng [3], đếm mô tế bào [4], …
Samsung SDS phát triển giải pháp ước lượng đám đông tập trung vào các khu vực cụ thể bao gồm khu vui chơi giải trí, trung tâm thương mại, sự kiện ngoài trời để hỗ trợ đơn vị quản lý giám sát an ninh, có các điều chỉnh hợp lý và kịp thời nhằm đảm bảo an toàn cho mọi người và cải thiện hiệu quả công việc.
1.2 Khó khăn, thách thức
Dữ liệu là thách thức đầu tiên với bài toán ước lượng đám đông. Độ phân giải của ảnh đầu vào cao có xu hướng cho kết quả dự đoán tốt hơn, thêm nữa các yếu tố mờ, nhiễu, biến dạng của bức hình tác động lớn tới kết quả dự đoán. Việc làm dữ liệu cho dạng bài toán này rất tốn kém thời gian và yêu cầu sự cẩn thận, tính ổn định cao khi gán điểm (head point) cho ảnh.
Sự đa dạng ngoại cảnh, mật độ đối tượng thay đổi lớn có thể từ vài người lên tới hàng ngàn người trong bức hình là khó khăn không nhỏ cho mô hình trong mong muốn đạt được sự hội tụ và tính tổng quát.
Nhãn negative, ‘fake’ người: Mô hình hướng tới giải quyết việc ước lượng với dự kiến là số lượng người sẽ lớn nhưng có thể xảy ra hiện tượng mô hình sai khi dự đoán bức hình không có người hoặc có người ‘fake’ qua gương, qua màn hình. Điều này là khó tránh và người phát triển mô hình nên có các giải pháp kết hợp khác nhau để giải quyết.
Kích thước ảnh đầu vào lớn, số lượng đối tượng cần dự đoán nhiều đòi hỏi tài nguyên tính toán phải tăng theo đặt ra cho người xây dựng và huấn luyện mô hình cần điều chỉnh tham số phù hợp.
Trong 2-3 năm trở lại đây, các nhà nghiên cứu [1], [5] tỏ ra quan tâm hơn nữa tới nhiệm vụ xác định vị trí của các đối tượng trong bức hình thay vì chỉ quan tâm kết quả đếm. Nhiệm vụ này thách thức hơn khi mật độ cao dễ xảy ra sự thiếu sót, nhầm lẫn, nhưng có ý nghĩa trong việc hỗ trợ phân tích hành vi, xu hướng dịch chuyển và giám sát người trong đám đông.
1.3 Phương pháp đánh giá
Chúng ta sẽ tập trung vào nhiệm vụ đếm người, ở đây phương pháp đánh giá là sử dụng sai số bao gồm Mean Absolute Error (MAE), Mean Squared Error (MSE) như hình 2a-b. Ngoài ra để dễ dàng lượng hóa và giải thích với người không chuyên về kĩ thuật chúng ta có thể cân nhắc sử dụng độ chính xác Accuracy được tính như hình 2c. Độ chính xác này được xây dựng từ việc chuẩn hóa sai số tuyệt đối nên dễ dàng giải thích cho bất kì tập dữ liệu nào. Ví dụ thay vì bạn nêu MAE của tập ShanghaiTech B là 8.5, MAE của tập ShanghaiTech A là 54.2 thì bạn dùng Accuracy mô hình đạt 90% trên tập ShanghaiTechB, 85% trên tập ShanghaiTech A tương ứng sẽ dễ hình dung hơn.
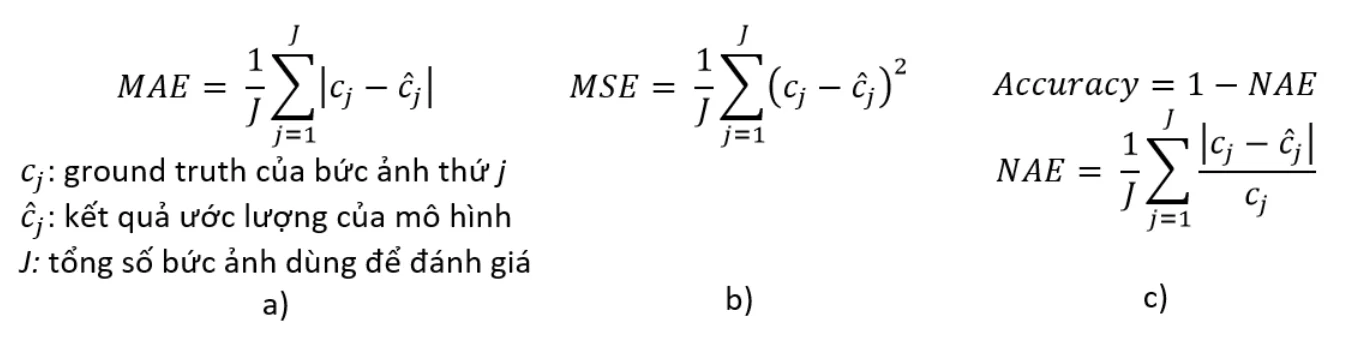
1.4 Bộ dữ liệu tham khảo
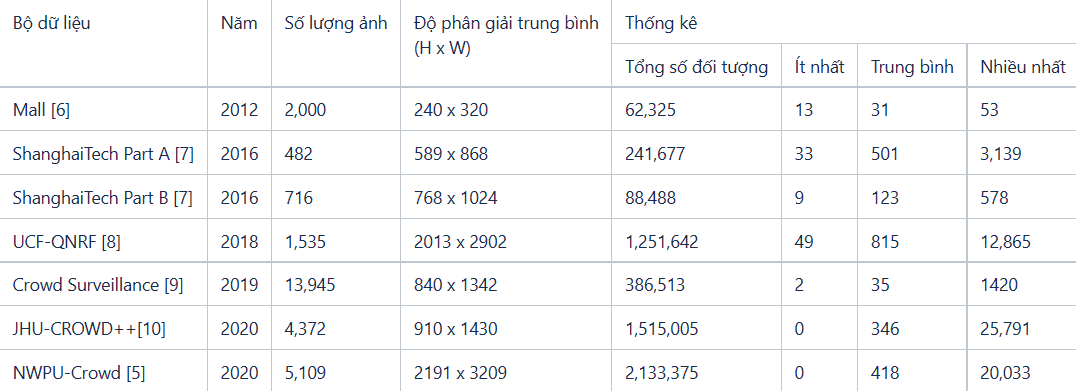
Bảng 1 tổng hợp một số bộ dữ liệu công khai được cộng đồng nghiên sử dụng để đánh giá các phương pháp của họ. Trong đó,
Tập dữ liệu Mall [6] gồm 2000 frame ảnh kích thước 240 x 320 được thu thập từ các video an ninh tại trung tâm mua sắm. Đây được xem là tập dữ liệu đa dạng và tốt tại thời điểm năm 2012 phục vụ mục đích nghiên cứu. Tuy nhiên thời điểm hiện tại do hạn chế về chất lượng hình ảnh, tập dữ liệu Mall ít được các nghiên cứu mới sử dụng.
Tập dữ liệu Shanghai [7] có tổng cộng 1198 hình ảnh được chia thành 2 tập part A và part B dựa theo mật độ. Tập part A là các hình ảnh thu thập từ internet và có mật độ trung bình cao tới 501 người/ hình. Trong khi part B là các hình ảnh được quay, chụp từ các con phố nhộn nhịp, sôi động của thành phố Thượng Hải. Tập dữ liệu Shanghai đảm bảo sự đa dạng về ngoại cảnh và vẫn thường được sử dụng trong các nghiên cứu gần đây, tuy nhiên số lượng hình ảnh của tập dữ liệu còn ít.
Tập dữ liệu UCF-QNRF [8] có 1535 ảnh với mật độ lớn, các hình ảnh được thu thập từ Flickr, và search web với đa dạng về mật độ, điều kiện ánh sáng, background của đám đông. Khi sử dụng bộ dữ liệu này, mọi người cần lưu ý về kích thước ảnh bởi nó tương đối lớn gây tiêu tốn bộ nhớ.
Tập dữ liệu Crowd Surveillance [9]được xây dựng từ các video an ninh tại đường phố, nhà ga, sân bay, lớp học, khu triển lãm với đa dạng ngoại cảnh trong nhà, ngoài trời. Tập dữ liệu có hai ưu điểm là độ phân giải của ảnh ở mức phù hợp và nhãn dữ liệu được bổ sung thêm thông tin các khu vực bị nhiễu, mờ.
Tập dữ liệu JHU-CROWD++[10]được thu thập trong nhiều tình huống và điều kiện môi trường khác nhau. Nhãn của dữ liệu được cung cấp đầy đủ dưới dạng điểm (point-level), hộp giới hạn (box-level) và xếp theo cả mức độ mờ. Đây là tập dữ liệu mới, khó, đem lại nhiều thách thức cho việc phát triển các mô hình có tính tổng quát.
Tập dữ liệu NWPU-Crowd [5] gồm 5109 hình ảnh với hơn 2 triệu nhãn đối tượng. Đây là tập dữ liệu có mật độ đối tượng trong hình trải rộng nhất từ 0 tới 20,033 người xuất hiện trong một hình. Tập dữ liệu cũng thêm một lượng hình ảnh không có người nhưng dễ gây nhầm lẫn cho mô hình AI, vì thế nó cũng là tập dữ liệu thách thức và thu hút nhiều sự quan tâm nghiên cứu.
2. Lĩnh vực ứng dụng
Tính năng ước lượng đám đông được ứng dụng nhiều trong hệ thống CCTV camera giám sát an ninh. Cụ thể, dựa trên tài liệu khảo sát [11], chúng tôi tóm tắt thành hai hướng ứng dụng:
2.1 Kiểm soát an ninh, cảnh báo sớm bất thường:
Do sự phát triển của xã hội, đặc biệt tại các đô thị lớn, mật độ đám đông ngày càng tăng tại các trung tâm mua sắm, nhà ga, sân bay, điểm du lịch, sân vận động và các trung tâm triển lãm, quảng trường. Các trường hợp này có nguy cơ dẫn tới các sự việc chen lấn, xô đẩy, giẫ-m đạp gây mất an toàn như sự kiện đón giao thừa tại quảng trường Chenyi tại Bến Thượng Hải ngày 31/12/2014, hay mới đây là sự kiện Halloween tại Itaewon, Seoul ngày 29/10/2022. Trong tương lai, thế giới hoàn toàn có thể tránh được những điều đáng tiếc nêu trên khi giải pháp ước lượng đám đông được triển khai và có những cảnh báo kịp thời tới các nhà quản lý. Hình 3 là một ví dụ về đám đông tập trung tại nhà ga, nơi mật độ người lui tới cao.

2.2 Phân tích, tối ưu không gian, tài nguyên kinh doanh

Các trung tâm thương mại, khu vui chơi giải trí có thể dùng các số liệu phân tích mật độ khách hàng theo khung giờ, khu vực, theo mùa để đánh giá mức độ quan tâm của khách hàng đối với một sản phẩm, khu vực nào đó. Từ đó, đơn vị quản lý có thể tối ưu hóa việc phân bố nguồn lực, phân bố nhân viên phục vụ và hàng hóa, đồng thời cải thiện chất lượng dịch vụ, phát triển các chiến lược tiếp thị hiệu quả. Hình 4 là ảnh chụp một trung tâm thương mại ngày cuối tuần.
2.3 Kiến tạo, quy hoạch đô thị thông minh
Xu hướng phát triển chung là ứng dụng công nghệ vào đời sống, hỗ trợ con người trong việc cải thiện hiệu suất lao động. Ví dụ, trước đây nhân viên bảo vệ phải thường xuyên quan sát, theo dõi nhiều màn hình camera an ninh thì giờ đây công nghệ thông minh sử dụng trí tuệ nhân tạo sẽ dần thay thế phần việc nhàm chán và tốn thời gian này, con người giữ vai trò nhận thông tin và ra quyết định. Tính năng ước lượng đám đông có thể triển khai tại khu công viên, khu vui chơi của đô thị nhằm đảm bảo sự vận hành hiểu quả, tạo môi trường sống thoải mái, tiện ích hơn.
3. Một số phương pháp tiếp cận
Có 4 hướng tiếp cận chính đối với bài toán ước lượng đám đông: phương pháp dựa vào phát hiện đối tượng, phương pháp dựa vào hồi quy, phương pháp ước lượng bản đồ mật độ, phương pháp
ứng dụng transformer. Bản thân mỗi phương pháp có ưu điểm, nhược điểm riêng và hoàn toàn có thể kết hợp linh hoạt các phương pháp để giải bài toán, cụ thể:
3.1 Phương pháp dựa vào phát hiện đối tượng:

Phương pháp này được sử dụng khá sớm để giải các bài toán đếm đối tượng rồi phát triển lên cho bài toán đếm số lượng người trong đám đông [12], [13]. Phương pháp này tỏ ra đơn giản và hiệu quả trong các trường hợp mật độ đối tượng thấp bởi nó sử dụng mô hình phát hiện vật thể kết hợp quá trình post-processing để tìm ra các hộp giới hạn chứa người hoặc phần đầu của người như hình 5.
Khi mật độ đối tượng xuất hiện trong ảnh đầu vào tăng lên tới con số hàng trăm, thậm chí hàng ngàn, hướng tiếp cận dựa vào phát hiện đối tượng bộc lộ một số nhược điểm như đếm sót đối tượng do hiện tượng che khuất, các đối tượng quá nhỏ dẫn tới hiệu quả của mô hình giảm xuống nhanh chóng.
3.2 Phương pháp ước lượng dựa vào bản đồ mật độ:

Sử dụng bản đồ mật độ (density map) là phương pháp chính kéo dài xuyên suốt giai đoạn 2010 tới nay với một số công trình nổi bật [14], [15]. Ý tưởng của phương pháp này là dựa vào các nhãn head point của dữ liệu sinh ra một bản đồ mật độ đặc trưng cho bức hình. Bản đồ mật độ này chứa thông tin sự phân bố của các đối tượng trong không gian, dựa vào nó thành phần kiến trúc tiếp theo sẽ làm nhiệm vụ đếm ra số lượng đối tượng trong bản đồ mật độ.
Phương pháp này được mô tả tóm lược như hình 6. Mục đích của các biến thể, cải tiến về sau là thiết kế mô hình mạng học sâu sao cho có thể học cách tạo ra được một bản đồ mật độ chất lượng cao phục vụ việc đếm đối tượng. Phương pháp này tỏ ra hiệu quả hơn phương pháp dựa vào phát hiện đối tượng đối với các hình ảnh có mật độ đối tượng lớn. Tuy nhiên, phương pháp này rất khó chỉ ra chính xác vị trí của từng đối tượng, nó chỉ cung cấp bản đồ thông tin mật độ, nghĩa là cho biết khu vực nào có đông, khu vực nào có thưa đối tượng. Ngoài ra phương pháp này có thể bị đánh lừa khi trong ảnh có các vật thể như cây cối, tán cây che khuất khu vực đối tượng khiến mô hình dự đoán nhầm mật độ.
3.3 Phương pháp dựa vào hồi quy
Ban đầu, phương pháp này xử lý, trích xuất thông tin ảnh đầu vào tạo ra các đặc trưng cục bộ (local feature) rồi trực tiếp học cách dự đoán số lượng đối tượng có trong các local feature [6].
Đặc điểm mô hình chỉ trả ra kết quả là một con số ước lượng dẫn tới nhiệm vụ này còn có tên gọi khác là weakly-supervised, nghĩa là người xây dựng kiến trúc chỉ quan tâm tới cấp độ đếm ra số lượng, không quan tâm tới nhãn point trong đầu ra của dự đoán. Nhược điểm chính của phương pháp này là các mô hình CNN được áp dụng gặp những giới hạn về cách nắm bắt sự tương quan giữa các vùng thông tin (receptive field) với ngữ cảnh (context) bởi một bức hình có mật độ đối tượng rất đa dạng về ngoại cảnh và càng không thể bỏ qua tính đặc trưng của từng phần trong bức hình.
Năm 2021, nhóm tác giả Qingyu Song [16] đề xuất giải pháp dựa trên hồi quy, trực tiếp dự đoán ra một tập hợp các điểm tiềm năng chứa tâm của các box giới hạn của người (phần đầu người) và một nhánh phân loại trả ra độ tự tin tương ứng cho các điểm, nhiệm vụ tiếp theo là matching hợp lý các điểm tiềm năng với nhãn ground truth theo chiến lược matching 1-vs-1. Phương pháp này đạt được kết quả top-1 trên tập dữ liệu Shanghai Tech A, nó phù hợp cả với yêu cầu xác định vị trí của đối tượng trong bức hình.
3.4 Phương pháp ứng dụng transformer
Kiến trúc transformer đã được ứng dụng sang lĩnh vực xử lý ảnh sau những thành công vượt trội trong các nhiệm vụ xử lý ngôn ngữ tự nhiên [17]. Bài toán ước lượng đám đông đã có một số nghiên cứu theo hướng ứng dụng transformer, cụ thể [18] biến bức hình đầu vào thành một chuỗi các phần hình ảnh nhỏ hơn và không chồng chập, rồi đề xuất sử dụng kiến trúc transformer làm bộ mã hóa (encoder) thông tin trước khi sử dụng thành phần hồi quy để đếm số lượng đối tượng có trong hình.
Thông tin chi tiết hơn về kiến trúc transformer, bạn đọc có thể tham khảo bài viết Phân loại ảnh văn bản – Document image classification đã được nhóm tác giả của SDSRV công bố trước đó.
Phần tiếp theo của bài viết sẽ đi giới thiệu mô hình ước lượng đám đông sử dụng phương pháp dựa vào hồi quy kết hợp với kiến trúc transformer.
4. Mô hình end to end transformer giải bài toán ước lượng đám đông
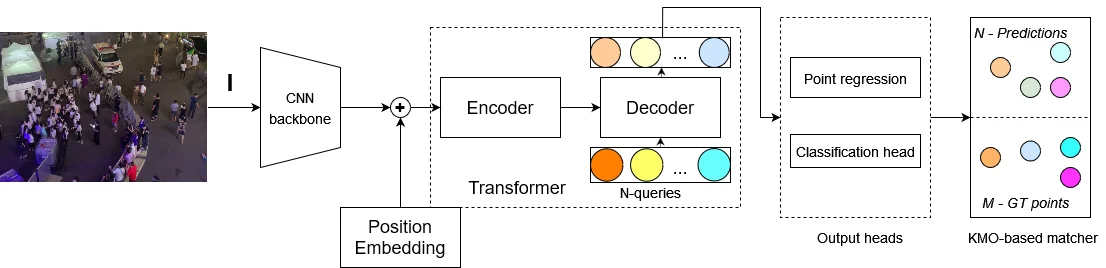
Hình 7 mô tả kiến trúc tổng quan của mô hình end-to-end transformer sử dụng cho bài toán ước lượng đám đông và cung cấp thông tin vị trí của các đối tượng.
Kiến trúc end-to-end transformer trực tiếp dự đoán ra các vị trí có đối tượng và điểm tự tin tương ứng. Các thành phần chính của kiến trúc bao gồm: một mạng thần kinh tích chập CNN backbone, mô hình transformer (gồm encoder và decoder), và bộ matching đối tượng dùng k-nearest neighbors (kNN).
Bức hình đầu vào I có kích thước H x W x 3 được đưa qua backbone để trích xuất đặc trưng F. Đặc trưng F có kích thước  với C là số lượng channel của F. Backbone gốc mà nhóm tác giả sử dụng là ResNet50 [19]. Các bức hình đầu vào có kích thước lớn sẽ được resize giữ nguyên tỉ lệ và cố định kích thước tối đa một chiều rộng/cao không vượt quá 2048 rồi được crop thành các hình kích thước 256 x 256 nhỏ hơn trước khi đưa qua backbone.
với C là số lượng channel của F. Backbone gốc mà nhóm tác giả sử dụng là ResNet50 [19]. Các bức hình đầu vào có kích thước lớn sẽ được resize giữ nguyên tỉ lệ và cố định kích thước tối đa một chiều rộng/cao không vượt quá 2048 rồi được crop thành các hình kích thước 256 x 256 nhỏ hơn trước khi đưa qua backbone.
Đặc trưng F được duỗi thẳng thành chuỗi 1D, làm giảm số channel từ C xuống c = 256 và có thông tin vị trí (position embedding) tương ứng. Đặc trưng mới F_p có kích thước  được dùng làm đầu vào cho thành phần transformer encoder gồm 6 layers.
được dùng làm đầu vào cho thành phần transformer encoder gồm 6 layers.
Nhánh transformer decoder cũng gồm 6 layers nhận đầu ra của encoder và N queries truy vấn để tương tác và tính toán thông qua cơ chế attention sinh ra decoded embedding.
Đầu ra decoded embedding của thành phần transformer được sử dụng để tính hai trường thông tin là điểm (vị trí của các head point), và thông tin phân loại điểm head point có độ tự tin tương ứng là bao nhiêu.
Khối ghép cặp 1-vs-1
Trong quá trình huấn luyện, nhóm tác giả [1] đề xuất chiến lược matching 1-vs-1 với hàm ý:
Quá trình dự đoán sẽ sinh ra N điểm tiềm năng chứa đối tượng (dựa vào N truy vấn của thành phần transformer decoder), thông thường N = 500 và lớn hơn M điểm ground truth thực sự có đối tượng. Vấn đề nảy sinh là cần kết hợp, ghép cặp N điểm tiềm năng với M điểm ground truth sao cho hợp lý. Một cách trực tiếp có thể xem xét kết hợp các điểm gần nhau và có độ tin cậy cao vào một cặp. Đây là dạng bài toán phân công công việc, thuật toán Hungarian nhận đầu vào là ma trận chi phí giữa N điểm tiềm năng với M điểm ground truth được xây dựng theo hình dưới [1] sẽ cho lời giải ghép cặp 1-vs-1 phù hợp.

Theo nhóm tác giả [1] việc sử dụng chỉ khoảng cách L1 có thể bỏ sót thông tin của bối cảnh xung quanh, đặc biệt là khi các điểm dự đoán rất gần nhau. Thông tin chứa khoảng cách trung bình của k điểm xung quanh được thêm vào như một giải pháp bổ sung thông tin bối cảnh (thường k = 4). Công thức được viết lại như hình dưới [1]:

5. Kết quả thực nghiệm
Chúng tôi kết hợp việc lựa chọn và làm sạch các bộ dữ liệu NWPU, Crowd Surveillance với dữ liệu tự thu thập để phục vụ huấn luyện mô hình, cụ thể 5013 hình huấn luyện, 1392 hình đánh giá. Hình 8a-b cung cấp kết quả ước lượng đám đông tại trung tâm thương mại, và phố đi bộ khi có sự kiện tập trung nhiều người. Hình 8c-d thể hiện sự thay đổi trong điều kiện ánh sáng ban ngày và ban đêm, mô hình vẫn dự đoán hiệu quả.
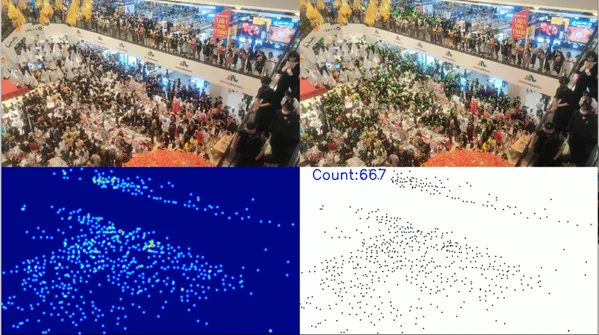



Hình 8 a-d – Kết quả dự đoán của mô hình tại sự kiện trong nhà, ngoài trời, dưới điều kiện ánh sáng ban ngày, buổi tối tương ứng.
TÀI LIỆU THAM KHẢO
[1] Dingkang Liang et al, “An End-to-End Transformer Model for Crowd Localization”, ECCV 2022.
[2] Meng-Ru Hsieh et al, “Drone-based Object Counting by Spatially Regularized Regional ProposalNetwork”, ICCV 2017.
[3] Viresh Ranjan et al, “Learning To Count Everything”, CVPR 2021.
[4] Mark Marsden et al, “People, Penguins and Petri Dishes: Adapting Object Counting Models To New Visual Domains And Object Types Without Forgetting”, CVPR 2018.
[5] Qi Wang et al, “NWPU-Crowd: A Large-Scale Benchmark for Crowd Counting and Localization”, IEEE Transactions on Pattern Analysis and Machine Intelligence, Volume: 43, Issue: 6, 01 June 2021, page 2141 – 2149.
[6] Ke Chen et al, “Feature mining for localised crowd counting”, BMVC 2012.
[7] Y. Zhang et al, “Single-image crowd counting via multi-column convolutional neural network,” in CVPR 2016.
[8] H. Idrees et al, “Composition loss for counting, density map estimation and localization in dense crowds,” in ECCV 2018.
[9] Z. Yan, Y. Yuan, W. Zuo, T. Xiao, Y. Wang, S. Wen, and E. Ding, “Perspective-guided convolution networks for crowd counting,” in ICCV 2019.
[10] Sindagi et al, “JHU-CROWD++: Large-Scale Crowd Counting Dataset and A Benchmark Method” Technical Report, Link: http://www.crowd-counting.com/
[11] Zizhu Fan et al, “A survey of crowd counting and density estimation based on convolutional neural network”, Neurocomputing, Volume 472, Feb 2022, Page 224-251.
[12] Rabaud, V., Belongie, S., “Counting crowded moving objects”, CVPR 2006.
[13] Li, M., Zhang, Z., Huang, K., Tan, T., “Estimating the number of people in crowded scenes by mid based foreground segmentation and head-shoulder detection”, ICPR 2008.
[14] Victor Lempitsky et al, “Learning To Count Objects in Images”, NIPS 2010.
[15] Cong Zhang, Hongsheng Li, Xiaogang Wang, and Xiaokang Yang, “Cross-scene crowd counting via deep convolutional neural networks”, CVPR 2015.
[16] Qingyu Song et al, “Rethinking Counting and Localization in Crowds: A Purely Point-Based Framework”, ICCV 2021.
[17] Alexey Dosovitskiy et al, “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale”, ICLR 2021.
[18] Dingkang Liang et al, “Transcrowd: weakly-supervised crowd counting with transformers”, Science China Information Sciences 2022.
[19] He, K., Zhang, X., Ren, S., Sun, J., “Deep residual learning for image recognition”, CVPR 2016.