Tối ưu hóa hệ thống ghi nhật ký Loki
Hiện tại công ty mình đang triển khai và vận hành một số ứng dụng trên Kubernetes và KubeFlow. Trong quá trình vận hành hệ thống, bên mình có gặp một lỗi về logging system khá là hay ho, muốn chia sẻ lại với mọi người, để nếu có ai gặp phải lỗi này thì cũng đỡ mất công tìm hiểu nhé.
Môi trường, bối cảnh
Logging và monitoring stack bên mình sử dụng là Promtail + Loki + prometheus. Trong đó:
- Promtail version 2.0.0
- Loki version 2.2.0
- storage lưu chunks sử dụng filesystem
- index bằng boltDB-shipper
Vấn đề gặp phải
Vào 1 ngày nọ, bên mình nhận được vấn đề Loki dừng thu thập thêm log của các pod.
Kiểm tra phần log của Loki service thì liên tục báo lỗi
level=error ts=202X-XX-XXT14:31:00.379Z caller=flush.go:199 org_id=fake msg="failed to flush user" err="open /A/B/chunks/ZmFrZS82YWQ3ODRlMWU4N2VlMjMzOjEYzViZTgw: file too large"
Điều tra nguyên nhân
Bước 1:
Với message lỗi như trên, phản xạ đầu tiên là check mountpoint size chứa log của Loki bằng lệnh “df -h” và “df -i” quen thuộc
→ Cả dung lượng và số lượng inodes trên mountpoint đều ở mức chỉ vài %, không phải nguyên nhân
Bước 2:
Khoanh vùng lỗi bằng cách thử tạo 1 file trong thư mục log của Loki bằng lệnh “touch demo.txt”
→ Gặp lỗi tương tự, nhưng lần này lỗi được báo trên dòng lệnh terminal
→ Vậy vấn đề nằm ở filesystem, không phải do Loki
Bước 3:
Mountpoint này được cấu hình từ 1 volume từ NAS NetApp. Bọn mình có search đc message lỗi tương tự của NetApp NAS tại đây và tìm hiểu thêm tại đây về tham số max_dir_size.
max_dir_size là tham số của NetApp để giới hạn size của 1 directory trong 1 volume, default là 320 MB.
Bọn mình check lại directory size của Loki log dir bằng lệnh cơ bản “ls -l”
$ ls -l
-rwxr-xr-x 1 user group 98404 Nov 8 2021 application.png
drwxr-xr-x 3 user group 4096 Apr 13 2022 backup
-rw-rw-r-- 1 user group 2221823 Aug 30 2021 ems.log.0000000009.txt
-rwxr-xr-x 1 user group 1174298 Feb 12 2020 putty.log
drwxrwxr-x 4 user group 12288 Sep 17 2021 logsCột thứ năm hiển thị dung lượng được sử dụng cho mỗi tệp, tính theo byte.
hoặc dùng lệnh stat
$ stat /etc
File: /etc
Size: 12288 Blocks: 24 IO Block: 4096 directory
Device: 10301h/66305d Inode: 29491201 Links: 141
Access: (0755/drwxr-xr-x) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2023-03-13 12:25:28.004794546 +0900
Modify: 2023-03-13 12:23:23.982249160 +0900
Change: 2023-03-13 12:23:23.982249160 +0900
Birth: -Size: 12288 là directory size
Sau khi check, bên mình confirm đúng directory size của Loki logging dir ~ 320 MB (chỗ này bọn mình ko screenshot lại)
Khi bọn mình move thử 1 vài file ra khỏi directory thì có thể tạo được file mới trong directory này
→ Như vậy, bọn mình đã xác định vấn đề trực tiếp
Phiên bản loki đang sử dụng là 2.2.0 sử dụng storage là filesystem và schema config là v11
schema_config:
configs:
- from: 20YY-MM-DD
store: boltdb-shipper
object_store: filesystem
schema: v11
index:
prefix: index_
period: 24hcác file chunk được đặt trong cùng 1 folder với tên là encode base64 của đoạn mã sau:
<user>/<fingerprint>:<start>:<end>:<checksum>
VD: ZmFrZS83YTI1N2M5ZWI2YTYyMDkwOjE2OWYzMTZiODE2OjE2OWYzMTZiODYyOjdkNzMyNGQyViệc lưu file như này có thể khiến folder bị đạt giới hạn max_dir_size khi số lượng file lớn
Trong trường hợp lỗi mà bọn mình gặp phải, số lượng file xấp xỉ 2,1 triệu
Tại sao số lượng chunk file lại nhiều như vậy ?
Analyze-labels
Promtail thu thập các log từ các pod, đồng thời thu thập metadata từ các pod này để tạo thành các label set, và dùng label set như 1 dạng multi-part index để query nội dung của các log.
Với mỗi 1 tập giá trị của label set, Loki sẽ tạo ra 1 log stream, và tương ứng mỗi log stream sẽ sinh ra *ít nhất* 1 chunk file trong logging dir.
Kể cả nếu pod chứa ít label key, nhưng value của label key có quá nhiều (high cardinality) thì Loki vẫn sẽ sinh ra rất nhiều log stream → log chunk files.
Vì vậy, đầu tiên bọn mình sử dụng tool logcli để tìm hiểu xem label nào sinh ra nhiều stream nhất.
logcli series {} --analyze-labels --since 400h
Total Streams: 74600
Unique Labels: 39
Label Name Unique Values Found In Streams
filename 54845 74600
pod 1305 74600
job_name 752 2026
pod_template_hash 135 72522
namespace 131 74600
container 108 74600
AAA_app 83 62712
app 20 9855
service_istio_io_canonical_name 13 555
replica_index 7 2026
controller_revision_hash 6 50
statefulset_kubernetes_io_pod_name 4 18
pod_template_generation 2 32
....Ta để ý thấy label “filename” góp mặt trong đa phần các stream được sinh ra. Như vậy, nếu ta bỏ được label “filename” thì có thể sẽ giảm được số chunk file đáng kể
“filename” ở đây là tên (full path) của file log trên node đó. (vd: /var/log/pod/aabb/1.log)
Tuy nhiên, đến đây ta chưa thể xác định được về mặt số lượng thì liệu apply hot fix bỏ “filename” thì sẽ giảm đc bao nhiêu % số chunk file.
Vì vậy, bọn mình đã lèm thêm 1 bước tiếp theo
Chunks label inspection
Chúng ta cần phải xem xét kỹ hơn thông tin về label set của các file chunks, dung lượng, số dòng log và thời gian tạo của các file này
Loki đã có sẵn 1 tool dùng để decode các thông tin này: chunks-inspect nhưng tool mới chỉ chạy trên từng file và output đang hơi thừa.
Chỉnh sửa lại tool này một chút để quét toàn bộ file trong folder và xuất ra các thông tin dạng CSV: chunks-folder-inspect
Cách chạy
go build .
./chunks-inspect YOUR_FOLDER > output.csvKết quả sau khi chạy: trung bình trong 1 tháng số lượng file sinh ra là 900 ngàn, trong đó số lượng file chỉ có duy nhất 1 dòng log là 800 ngàn
với các file này sự khác biệt giữa các label set chỉ là khác nhau về “filename”
Bắt tay vào xử lý
Lý do khiến cho label “filename” xuất hiện trong labelset của các dòng log vì đoạn config trong promtail
scrape_configs:
- job_name: abcxyz
pipeline_stages:
- docker: {}
kubernetes_sd_configs:
- role: pod
relabel_configs:
- replacement: /var/log/pods/*$1/*.log
separator: /
source_labels:
- __meta_kubernetes_pod_uid
- __meta_kubernetes_pod_container_name
target_label: __path__Với config này:
+ Promtail sẽ discover các pods trong k8s và tạo ra các target tương ứng cho phần relabel_configs
+ Trong phần relabel, Promtail sẽ ghép value của các label uid và container_name lại và assign “/var/log/pods/*<uid_value>/<container_name_value>/*.log” vào biến “__path__”
+ Biến “__path__” là 1 biến đặc biệt trong promtail, phần pipeline_stages docker sẽ sử dụng biến này để tìm đến các log file với format của Docker để parse. Sau đó, nó sẽ relabel biến này thành “filename”
Bọn mình ko cần label ở mức “filename”, do vậy có thể loại bỏ label “filename” khỏi promtail để gom các stream của cùng 1 pod lại thành 1 stream duy nhất bằng cách chỉnh sửa config
pipeline_stages:
- docker: {}
- labeldrop: [filename]Sau khi apply config này số lượng các file 1 dòng vẫn còn khá nhiều. Kiểm tra mốc thời gian tạo file chunks của cùng 1 label set
Ta có thông số như hình dưới:
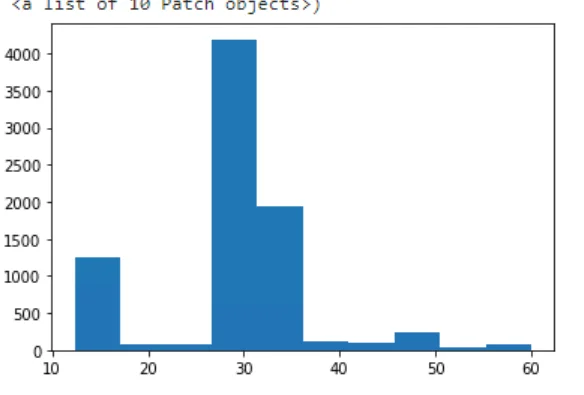
Hiện tại config về chunk_idle_period của loki đang là 15 phút do vậy các file sẽ có thời gian tạo cách nhau > 15 phút.
Nhưng phần lớn các pod sau khoảng 30 phút mới đẩy về log do vậy cần setup lại chunk_idle_period
Tính toán cho thấy nếu set thành 40 phút sẽ cover được 87% các pod.
config:
auth_enabled: false
ingester:
chunk_idle_period: 40mKết quả
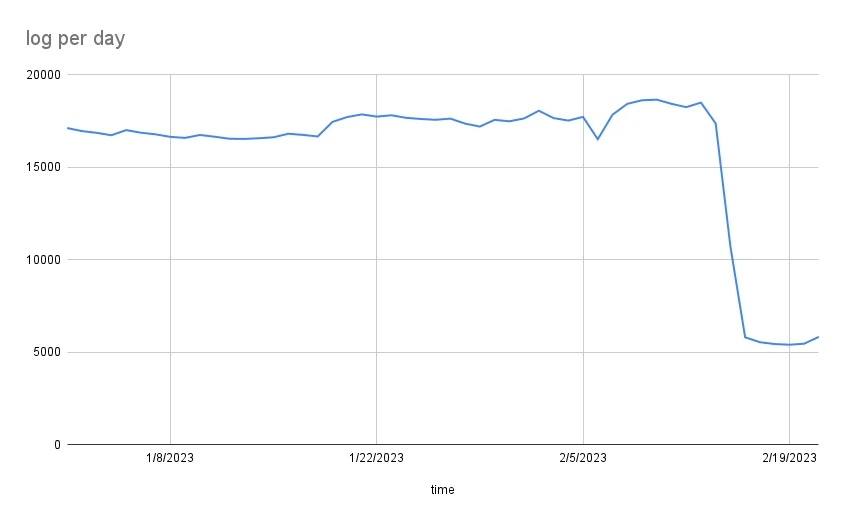
Sau khi chỉnh sửa các setup của promtail và loki số lượng file sinh ra mỗi ngày giảm từ ~20K xuống ~5k
Key takeaways:
- Monitor số lượng chunk file của Loki (vd bằng prometheus) để phát hiện / cảnh báo trước khi lỗi
- Trong trường hợp số lượng log file vượt quá dự kiến, phân tích theo 2 chiều:
- Cardinality của label set: sử dụng logcli, tìm kiếm label có cardinality cao nhất, xem xét có cần thiết sử dụng label đó ko (trong câu lệnh query)
## clone from github và chạy
git clone https://github.com/grafana/loki.git
cd loki
make logcli
## copy file build vào thư mục /usr/local...
cp cmd/logcli/logcli /usr/local/bin/logcliNếu sử dụng loki instance thì phải khai báo địa chỉ loki ví dụ
export LOKI_ADDR=http://localhost:3100
- Với 1 label set, phân tích số lượng chunk file theo chunk_idle_period để tìm ra ngưỡng set tham số phù hợp (tool đọc chunk file → label set: https://github.com/piggy2303/chunks-folder-inspect)