Khám phá tiềm năng của Mô hình Ngôn ngữ Thị giác trong Trích xuất thông tin
Chương 1. Giới thiệu
Trong những năm gần đây, các bài toán về Computer Vision (Thị giác máy) như Image classification (Phân loại hình ảnh), Object Detection (Phát hiện đối tượng), và Semantic Segmentation (Phân đoạn ngữ nghĩa) đã chứng kiến sự phát triển đáng kể song song với sự tăng trưởng của Deep Learning (Học Sâu) và Machine Learning (Học Máy). Mặc dù các mô hình Deep Learning truyền thống đã thể hiện khả năng vượt trội trong các bài toán về Computer Vision, các phương pháp này vẫn gặp phải những hạn chế như hội tụ chậm trong quá trình huấn luyện và yêu cầu lớn về lượng dữ liệu dùng để huấn luyện.
Phương pháp tiền huấn luyện trên các tập dữ liệu lớn đã chứng minh tính hiệu quả trong các bài toán Computer Vision. Phương pháp này bao gồm ba bước chính: pretraining, finetuning và prediction. Trong quá trình tiền huấn luyện, một Mạng Nơ-ron Sâu (Deep Neural Network) được huấn luyện trên một tập dữ liệu lớn (ImageNet [31]), có thể được gán nhãn hoặc không được gán nhãn tùy thuộc vào phương pháp huấn luyện. Phương pháp này đã cho thấy hiệu suất vượt trội trong việc tăng tốc hội tụ và đạt được kết quả tốt hơn so với phương pháp truyền thống (training và prediction).
Tuy nhiên, phương pháp trên có một hạn chế đáng chú ý: nó yêu cầu một bước finetuning để điều chỉnh mô hình cho các nhiệm vụ cụ thể. Lấy cảm hứng từ sự tiến bộ vượt bậc trong các Mô hình Ngôn ngữ Lớn (Large Language Model), một phương pháp mới gọi là Mô hình Ngôn ngữ Thị giác (Vision Language Model) đã xuất hiện. Phương pháp này tập trung vào việc xử lý các cặp ảnh-văn bản bằng cách sử dụng dữ liệu quy mô lớn được thu thập từ nhiều nguồn internet khác nhau. Ưu điểm chính của phương pháp này là khả năng thực hiện dự đoán trực tiếp mà không cần tinh chỉnh cho từng nhiệm vụ cụ thể.
Bài viết này tập trung vào ứng dụng mô hình Vision Language Model, đặc biệt là mô hình Phi 3.5 Vision [18]. Thông qua thực nghiệm, Phi 3..5 Vision đã chứng minh tính hiệu quả của nó trong các nhiệm vụ hiểu tài liệu, làm nổi bật khả năng xử lý tài liệu đa dạng mà không cần finetune cho từng bài toán cụ thể.
Chương 2. Một số phương pháp liên quan
Phương pháp kết hợp OCR và Regular Expression: đây là một phương pháp khá cổ điển. Phương pháp này bao gồm hai bước chính: chuyển đổi hình ảnh sang văn bản, sau đó thực hiện lấy các giá trị cần thiết thông qua regex. Trong bước chuyển đổi hình ảnh sang văn bản, mô hình Text Detector được sử dụng nhằm trích xuất các vùng chứa chữ trong văn bản (YoloX [20], MixNet [21] , DBNet [23], TextFuseNet [22]), sau đó mô hình Text Recognition (CLIP4STR [24], SVTR [25], PARSeq [26]) nhận biết và chuyển đổi các từ trong các vùng đó sang định dạng văn bản. Nhằm tối ưu kết quả đầu ra, một số mô hình khác có thể được thêm vào nhằm tăng tính hiệu quả (giảm nhiễu, xoay ảnh) hoặc xóa các vùng không mong muốn trong ảnh (xóa watermark), v.v. Cuối cùng để có thể lấy được các thông tin mong muốn, một số biểu thức chính quy có thể được áp dụng nhằm trích lọc các thông tin cần thiết từ văn bản đầu ra của OCR.
Mặc dù phương pháp sử dụng biểu thức chính quy cung cấp một giải pháp khá đơn giản, nhanh chóng. Tuy nhiên nhược điểm lớn nhất của phương pháp này đó là độ chính xác và hạn chế trong khả năng mở rộng bài toán trích xuất thông tin so với các kỹ thuật tiên tiến hơn sử dụng Machine Learning hay Deep Learning.
Phương pháp kết hợp OCR và Key Information Extraction: để khắc phục nhược điểm của phương pháp trước đó, phương pháp này tập trung vào khả năng trích lọc thông tinh của mô hình Key Information Extraction – KIE. Tương tự như phương pháp kết hợp OCR và regex (biểu thức chính quy), phương pháp này sử dụng OCR để chuyển đổi hình ảnh thành văn bản mà máy tính có thể hiểu được. Sau đó mô hình KIE sẽ thực hiện xác định các cặp key – value trong văn bản. Các cặp key – value này đại diện cho các giá trị mà người dùng quan tâm, các trường key này có thể là: tên, địa chỉ, ngày tháng, số tiền, hoặc các dữ liệu liên quan khác mà mô hình đã được học từ dữ liệu cung cấp.
Có thể thấy rằng phương pháp này đặc biệt hữu ích cho các tài liệu có cấu trúc, chẳng hạn như hóa đơn, biên lai, mẫu đơn và các biểu mẫu có giá trị nhất quán. Một số ưu điểm khác có thể kể đến như: nhanh chóng và chính xác, có khả năng xử lý trên nhiều định dạng và bố cục tài liệu khác nhau. Tuy nhiên, phương pháp này vẫn còn tồn tại một số hạn chế như: còn phụ thuộc vào kết quả dự đoán của mô hình OCR hay độ chính xác của mô hình KIE. Với các tài liệu có bố cục phức tạp, nhiều biến thể khác nhau hoặc một số yếu tố như nhiễu, mờ cũng có thể ảnh hưởng lớn đến kết quả trích xuất.
Để giảm thiểu các hạn chế này, đã có một vài phương pháp khác nhau nhằm cải thiện khả năng trích xuất thông tin của KIE. LayoutLMv2 [27] và LayoutLMv3 [28] thúc đẩy khả năng hiểu dữ liệu của mô hình bằng cách tích hợp các thông tin về văn bản, bố cục và hình ảnh thông qua mô hình multi-modal Transformer encoders [13] và các chiến lược huấn luyện mô hình. BROS [29] tập trung vào khả năng mã hóa cấu trúc ảnh và phương pháp area-maksed language modeling để nâng cao khả năng trích xuất thông tin từ tài liệu, trong khi đó yêu cầu ít dữ liệu đào tạo hơn.
Phương pháp kết hợp OCR và Large Language Model (Mô hình ngôn ngữ lớn): Phương pháp này tận dụng ưu thế sẵn có của Large Language Model trong việc xử lý văn bản bằng cách sử dụng mô hình OCR truyền thống như các phương pháp trước đó, sau đó sử dụng LLM để trích xuất các thông tin mong muốn có trong văn bản đầu ra của OCR. Một số mô hình ngôn ngữ lớn phổ biến có thể sử dụng để trích rút thông tin như: GPT4 [30], Phi 3.5 [18], v.v. Điểm mạnh của phương pháp này nằm ở khả năng hiểu ngữ cảnh của các mô hình ngôn ngữ lớn do đã được huấn luyện trên tập dữ liệu khổng lồ. Do vậy các mô hình này có khả năng diễn giải một cách hiệu quả văn bản đã được đọc bởi OCR, từ đó mô hình có thể trích xuất các thông tin cần thiết như tên, ngày tháng, địa chỉ, số tiền, v.v. Hơn nữa LLM còn có khả năng sửa các lỗi sai gây ra bởi quá trình đọc văn bản từ hình ảnh, hay có khả năng nội suy các thông tin có từ văn bản đó.
Tuy nhiên, phương pháp này vẫn còn tồn tại một số nhược điểm cố hữu như: mặc dù mô hình ngôn ngữ lớn rất mạnh mẽ nhưng đôi khi mô hình có thể hiểu sai văn cảnh của tài liệu dẫn đến thông tin trả về có thể bị sai hoặc không liên quan đến yêu cầu đầu vào. Tài nguyên tính toán và chi phí vận hành cũng có thể là một hạn chế lớn của phương pháp này, khi người dùng cần triển khai trên thiết bị cá nhân.
Chương 3. Tổng quan về Vision Language Model
3.1. Tổng quan về Vision Language Model
Có thể thấy rằng các bài toán về Computer Vision (Image classification, Object Detection, và Semantic Segmentation) đã có một khoảng thời gian phát triển lâu dài cùng với sự phát triển của Deep Learning nói riêng cũng như Machine Learning nói chung. Một số thành tựu nổi bật của Machine Learning và Deep Learning trong các bài toán về Computer Vision có thể kể đến như: Support Vector Machine [1], RandomForest [2], AlexNet [3], VGG [4], ResNet [5], v.v. Mặc dù không thể phủ định được khả năng tuyệt vời của các mô hình học sâu này trong các bài toán Computer Vision, các mô hình này vẫn còn một số hạn chế cố định như: khả năng hội tụ chậm trong quá trình huấn luyện hay yêu cầu một lượng dữ liệu nhất định để có thể huấn luyện mô hình,v.v.
Trong một vài năm gần đây, phương pháp tiền huấn luyện trên dữ liệu lớn đã chứng minh khả năng của mình trong các bài toán về Computer Vision [11]. Phương pháp này bao gồm ba bước: pretraining (tiền huấn luyện), finetuning (tinh chỉnh), và prediction (dự đoán). Trong bước pretraining mô hình DNN (Deep Neural Network) được huấn luyện với một bộ dữ liệu lớn, bộ dữ liệu này có thể có nhãn hoặc không có nhãn tùy thuộc vào phương thức huấn luyện của mô hình. Một số phương thức tiền huấn luyện có thể kể đến như: Image Classification (có nhãn), Image Inpainting (không nhãn), Image Generation (cả có nhãn và không nhãn), và Image Reconstruction (không nhãn). Sau khi trải qua quá trình tiền huấn luyện, mô hình DNN được tinh chỉnh lại với tập dữ liệu chính mà mô hình cần xử lý. Thay vì chỉ có hai bước như phương pháp truyền thống (tranining và prediction), phương pháp này tỏ ra vượt trội trong khả năng tăng tốc quá trình hội tụ và đạt được kết quả tốt hơn trong tất cả các bài toán Computer Vision.
Tuy nhiên, phương pháp tiền huấn luyện trên dữ liệu lớn có nhược điểm đó là yêu cầu bước finetune nhằm tinh chỉnh mô hình phù hợp với bài toán đề ra. Lấy cảm hứng từ sự phát triển vượt bậc của Natural Language Model (Mô hình xử lý ngôn ngữ tự nhiên) [14], một phương pháp tiếp cận mới có tên Vision Language Model – VLM (Mô hình xử lý thị giác và ngôn ngữ tự nhiên) đã thu hút sự chú ý của giới học thuật. Trong phần này đó là phương pháp tiếp cận Vision Language Model Pretraining và Zero-shot Prediction. Phương pháp này tập trung vào khả năng xử lý hình ảnh – văn bản theo cặp và trên một lượng mẫu lớn được thu thập từ nhiều nguồn khác nhau trên internet. Từ đó mô hình có khả năng thực hiện trực tiếp bước prediction mà không cần thông qua bước finetune trên bài toán đề ra (Hình 3.1). Phụ thuộc vào cách tiếp cận khác nhau, quá trình pretranining cũng được tinh chỉnh nhằm tối ưu khả năng học tập của mô hình. Chẳng hạn như mô hình CLIP [10] tối ưu mô hình bằng cách huấn luyện mô hình sao cho vector embedding của các hình ảnh và đoạn văn cùng một cặp giống nhau nhất có thể và các hình ảnh, đoạn văn khác sẽ khác với cặp trên nhiều nhất có thể. Đồng thời cùng với lượng dữ liệu huấn luyện rất lớn được lấy từ internet, mô hình CLIP có khả năng dự đoán được đoạn văn tương ứng với một hình ảnh bất kì mà không cần thực hiện bước finetune cho từng bài toán cụ thể. Kết quả thực nghiệm đã chứng minh khả năng vượt trội của CLIP trên 36 bài toán Computer Vision khác nhau, từ các bài toán phân loại cổ điển đến phân loại hành động và nhận diện kí tự quang học,v.v.
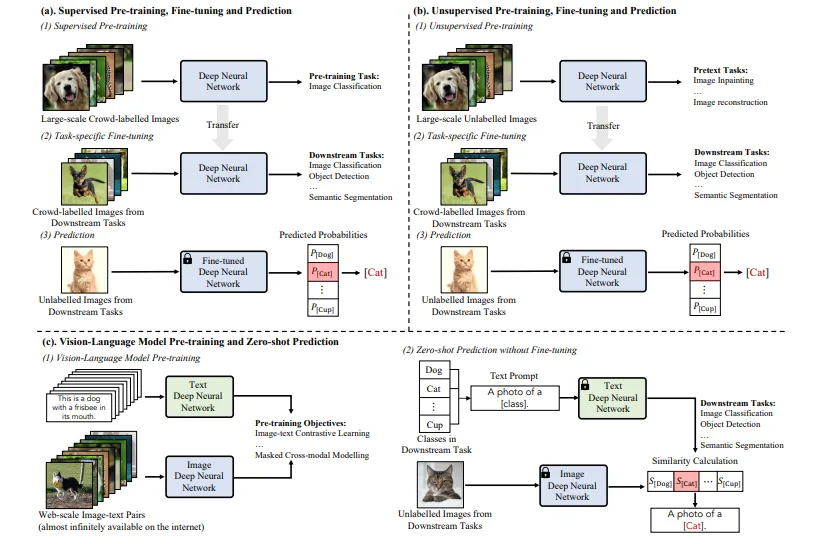
Hình 3.1: Quy trình huấn luyện phương pháp ba bước (Pretraining, Fine-tuning, và Prediction) (a, b), và phương pháp hai bước VLM (pretraining, và Zero-shot prediction) (c).
Hình 3.1 mô tả quy trình huấn luyện hai phương pháp tiền huấn luyện trên dữ liệu lớn và VLM pretraining and zero-shot prediction. Với phương pháp tiền huấn luyện trên dữ liệu lớn, mô hình được huấn luyện với một tập dữ liệu lớn có nhãn (phương pháp a) hoặc không có nhãn (phương pháp b). Sau khi mô hình học được các tri thức này, bước finetuning thực hiện quá trình tinh chỉnh mô hình trên từng bài toán cụ thể như Cat / Dog Classification, Face Detection, Anomaly Segmentation, Autonomous Driving, v.v thông qua tập dữ liệu finetune. Bước cuối cùng, người dùng có thể sử dụng mô hình để thực hiện dự đoán trên dữ liệu thực tế.
Trong khi đó, bước tiền huấn luyện của phương pháp VLM pretraining and zero-shot prediction tùy thuộc vào phương pháp tiếp cận, mô hình sẽ được huấn luyện theo cách khác nhau. Các phương pháp này bao gồm: Pretraining with Constrative Objects, Pretraining with Generative Objectives, và Pretraining with Aligment Objectives [6]). Ngay sau bước pretraining, mô hình lúc này có thể thực hiện prediction mà không yêu cầu thực hiện bước finetuning như phương pháp đầu.
3.2. Kiến trúc mô hình Vision Language Model
Trong quá trình tiền huấn luyện, mô hình VLM được huấn luyện để học các đặc trưng về cả hình ảnh và văn bản từ N cặp hình ảnh – văn bản trong bộ dữ liệu pretraining. Mạng DNN (Deep Neural Netrwork) sẽ có nhiệm vụ mã hóa thông tin của từng cặp hình ảnh và văn bản tương ứng, sau đó đẩy các thông tin này vào embedding space. Tùy thuộc vào kiến trúc mạng và phương thức mã hóa khác nhau, ta sẽ có các vector embedding khác nhau. Trong phần này, kiến trúc của mô hình Image Encoder và Text Encoder sẽ được giới thiệu cho người đọc cái nhìn tổng quát về kiến trúc của VLM.
3.2.1. Kiến trúc mạng Image Encoder
Với mạng Image Encoder, có hai loại kiến trúc được sử dụng phổ biến để trích xuất đặc trưng từ hình ảnh. Đó là kiến trúc Convolutional Neural Network và kiến trúc Transformer.
Convolutional Neural Network
Cùng với sự phát triển của Deep Learning đầu những năm 2000, mạng CNN đã có một sự tiến bộ vượt bậc nhờ vào sự ra đời của MLP (Multilayer Perceptron). Một số mô hình nổi bật có thể kể đến như VGG [4], Resnet [5], hay EfficientNet [12] đã được chứng minh tính hiệu quả trong các bài toán thị giác máy tính. Mặc dù ra đời đã lâu, Resnet vẫn chứng tỏ khả năng hiệu quả của mình nhờ kiến trúc Skip connections trong việc giảm thiểu cả vanishing gradient và explosion gradient, đồng thời cho phép người dùng có thể thiết kết mô hình với kiến trúc nhiều lớp mà không lo về vấn đề vanishing gradient.
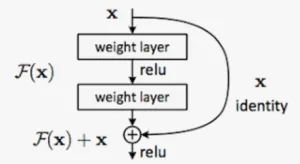
Hình 3.2: Kiến trúc Skip connections.
Để tối ưu khả năng trích xuất đặc trưng của mô hình Resnes, một số cải biến đã được sử dụng như: kết hợp Average pooling với Skip connections trong quá trình Downsampling hay trong lớp Convolution 7×7 sử dụng stride 1 – ResNet-D [7], sử dụng thêm “cardinality dimension” nhằm mở rộng kiến trúc mạng – ResNetXT [8], Tăng số lượng channel trong Residual Block – Wide ResNet [9], v.v.
Transformer
Transformer [13] đã mở ra một kỷ nguyên mới của mạng RNN (Recurrent Neural Network) do nó đã cải thiện được hầu hết các nhược điểm cố hữu của cấc mô hình RNN bấy giờ như: Vanishing Gradient, xử lý tuần tự, khó khăn trong việc nắm bắt phụ thuộc hài hạn, và khả năng diễn giải kém. Do sự thành công vượt trội của mình cho các bài toán xử lý ngôn ngữ tự nhiên, Transformer cũng đã được áp dụng để giải quyết bài toán xử lý hình ảnh, ban đầu là Vision Transformer. Tương tự như kiến trúc Transfomer thông thường, ViT [15] sử dụng một loạt các khối Transformer Encoder liền nhau, mỗi khối chứa một lớp multi-head self-attention và mạng feed forward. Điều đặc biệt của ViT đó là phương pháp này chia hình ảnh đầu vào thành các mảng có kích thước cố định, sau đó sử dụng linear projection và position embedding. Lúc này dữ liệu đã có thể truyền trực tiếp vào khối Transformer như thông thường. Để cải tiến ViT, CLIP [10] đã thêm một lớp chuẩn hóa phía trước kiến trúc encoder.
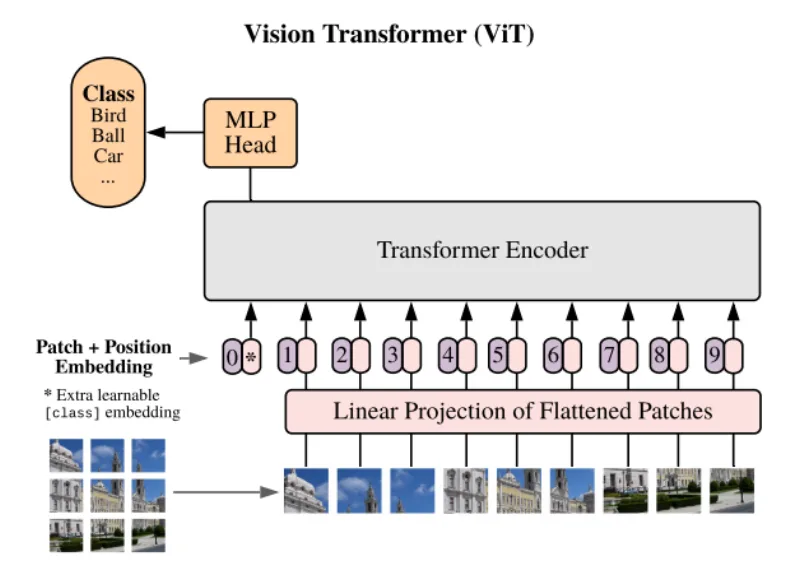
Hình 3.3: Kiến trúc mô hình Vision Transformer.
3.2.2. Kiến trúc mạng Text Encoder
So sánh với kiến trúc mạng Image Encoder, kiến trúc của Text Encoder khá đơn giản. Trong hầu hết các nghiên cứu, kiến trúc truyền thống của mô hình Transformer [13] đều được áp dụng [10], [13]. Một số nghiên cứu như GPT2 [16] thay vì sử dụng pretrained model có sẵn thì mô hình này thực hiện train lại toàn bộ từ đầu trên dữ liệu của họ.
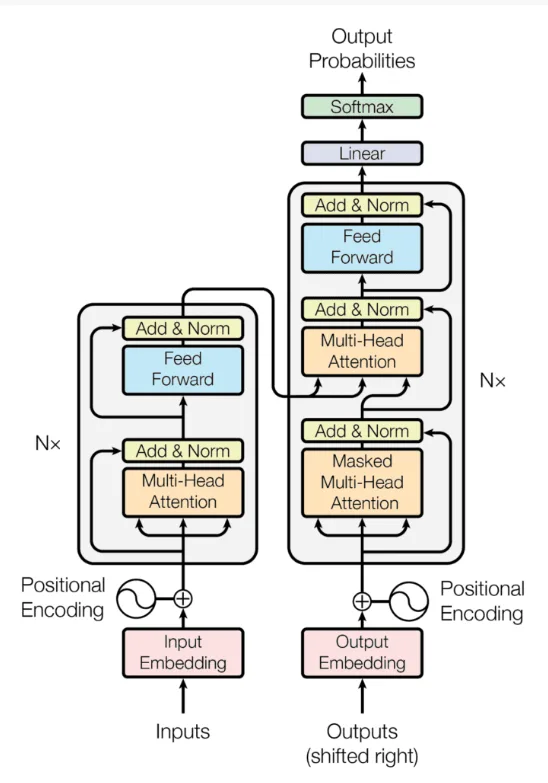
Hình 3.4: Kiến trúc Transformer truyền thống.
3.2.3. Kiến trúc mô hình Vision Language Model
Có ba kiến trúc phổ biến hiện hay cho mô hình Vision Language Model đó là: Two-tower Framework, Two-leg Framework, và One-tower Framework [6]. (Hình 3.5)
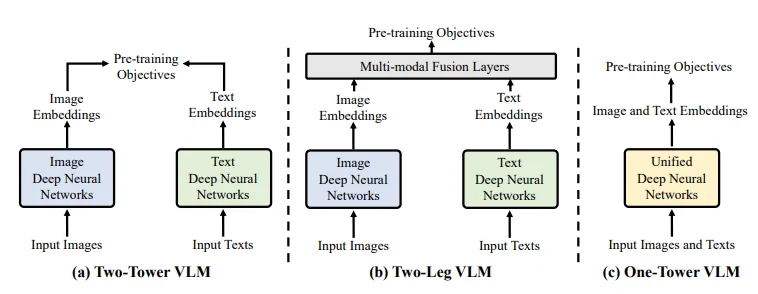
Hình 3.5: Ba kiến trúc mô hình VLM phổ biến hiện nay.
Phương pháp Two-tower Framework sử dụng hai bộ mã hóa riêng biệt cho hình ảnh và văn bản. Mỗi bộ mã hóa sẽ xử lý đầu vào tương ứng một cách động lập, trong đó bộ mã hóa hình ảnh sẽ trích xuât các đặc trưng thị giác và bộ mã hóa văn bản sẽ xử lý dữ liệu ngôn ngữ. Sau đó kết quả được kết hợp lại thông qua bước post-processing. Sự tách biệt này cho phép mỗi bộ mã hóa sẽ chuyên môn hóa quá trình xử lý và trích xuất đặc trưng. Tuy nhiên việc xử lý độc lập đôi khi có thể hạn chế sự tương quan giữa các đặc trưng thị giác và văn bản.
Để khắc phục nhược điểm của phương pháp Two-tower Framework, phương pháp Two-leg Framework thêm một lớp multi-modal Fusion Layer sau quá trình trích xuất đặc trưng của hai bộ mã hóa hình ảnh và văn bản. Phương pháp này giúp liên kết và tích hợp các đặc trưng từ cả hai mô hình giúp nâng cao khả năng hiểu mối quan hệ giữa văn bản và hình ảnh của VLM, làm tăng tính hiệu quả trong các bài toán đòi hỏi sự hiểu biết sâu sắc về các loại thông tin khác nhau.
Phương pháp One-tower Framework sử dụng cách tiếp cận khác với hai phương pháp còn lại. Phương pháp này sử dụng một bộ encoder duy nhất cho cả hình ảnh và văn bản, nó cho phép mô hình có thể giao tiếp và tương tác hiệu quả giữa các đặc trưng về hình ảnh và văn bản ngay từ đầu. Phương pháp này còn một số ưu điểm khác như: giảm thiểu lượng tài nguyên cần dùng và chi phí để tính toán, phù hợp cho các bài toán yêu cầu sự tích hợp chặt chẽ về thông tin thị giác và văn bản,v.v.
Chương 4: Thực nghiệm
4.1. Mô hình Phi 3.5 Vision
Hiện nay, ta không thể phủ nhận sự phát triển mạnh mẽ của các mô hình ngôn ngữ lớn trong các ứng dụng đời sống như: hỏi đáp, trích xuất thông tin, viết code, sinh ảnh, v.v. Tuy nhiên các mô hình này vẫn còn tồn tại nhược điểm cố hữu: khó có thể triển khai rộng rãi do kích thước và yêu cầu tài nguyên của chúng. Điều này đã thúc đẩy sự ra đời của các mô hình ngôn ngữ “nhỏ”, các mô hình này có khả năng hoạt động gần như tương đương với các mô hình “lớn” trong khi vẫn có thể hoạt động tốt trên các thiết bị có tài nguyên hạn chế.
Sự ra đời của Phi (được đề xuất bởi Microsoft [17]) đã chứng minh cho tính khả thi của các mô hình này. Một trong những mô hình nổi bật trong dòng Phi series là Phi-3.5-mini [18] và Phi-3.5-MoE [18]. Thông qua các bài kiểm nghiệm thực tế, các mô hình này đạt được hiệu suất đáng kể trong các tác vụ đa ngôn ngữ, đa phương thức mặc cho sự hạn chế về kích thước của chúng. Một mô hình đáng chú ý khác trong dòng Phi series đó là Phi-3.5-vision [18]. Mô hình này được thiết kế để có thể xử lý cả hình ảnh và văn bản, biến nó trở thành mô hình đa phương thức thực sự. Trong nghiên cứu này, Phi 3.5 Vision [18] đã được sử dụng để áp dụng cho bài toán Document Understanding.
Nghiên cứu này sẽ tập trung trình bày một số thông tin hữu ích của mô hình Phi 3.5 Vision đến với người đọc. Để có thể hiểu rõ hơn về Phi series, dưới đây là một số bài báo hữu ích : [17], [18], [19].
4.1.1. Kiến trúc mô hình
Mô hình Phi 3.5 Vision chứa 4.2 tỷ tham số, là mô hình đa phương thức được thiết kế để có thể xử lý một hoặc nhiều hình ảnh cùng với một văn bản làm đầu vào. Sau đó mô hình sẽ sinh ra đoạn văn bản phù hợp với yêu cầu. Cũng tương tự như các mô hình Vision Language Model khác, Phi 3.5 Vision gồm hai thành phần chính: một mạng Image encoder và một mạng text encoder. Trong đó mô hình CLIP ViT-L/14 [10] được sử dụng để mã hóa hình ảnh, và Phi 3.5 mini được sử dụng để mã hóa văn bản. Sự tích hợp này cho phép Phi 3.5 Vision có thể xử lý các tác vụ liên quan đến một hoặc nhiều hình ảnh cùng với văn bản cho sẵn, mang lại cảm giác liền mạch cho người dùng khi sử dụng hai loại dữ liệu này.
Để có thể xử lý hình ảnh với độ phân giải cao và hình ảnh với nhiều tỷ lệ khác nhau, thuật toán Dynamic Cropping Strategy [18] được sử dụng để chia hình ảnh đầu vào thành các khối trong mảng 2 chiều, mỗi khối sẽ biểu diễn một phần khác nhau của hình ảnh.
4.1.2. Chiến lược huấn luyện
Ta có thể chia quá trình huấn luyện mô hình Phi 3.5 Vision thành 3 giai đoạn: Pretraining, Supervised Fine-tuning (SFT), và Direct Preference Optimization (DPO). Trong giai đoạn pretraining, mô hình tập trung vào việc học các đặc trưng có trong cả hai dữ liệu hình ảnh và văn bản. Giai đoạn này mô hình sử dụng một lượng dữ liệu khổng lồ bao gồm các cặp dữ liệu hình ảnh – văn bản từ nhiều nguồn khác nhau như LAION [32, 33], FLD-5B [34]; dữ liệu tổng hợp từ OCR từ các file PDF để tăng cường khả năng trích xuất băn bản và hiểu bố cục của tài liệu; hay các tập dữ liệu dành cho việc hiểu biểu đồ, bảng biểu; và cuối cùng là dữ liệu văn bản để huấn luyện mô hình ngôn ngữ.
Sau khi hoàn tất quá trình Pretraining, Supervised Fine-tuning được sử dụng để tinh chỉnh mô hình cho các bài toán cụ thể và cải thiện khả năng của mô hình. Giai đoạn này mô hình sử dụng các tập dữ liệu chỉ bao gồm băn bản, các tập dữ liệu tinh chỉnh mô hình đa ngôn ngữ đã được công khai, và tập dữ liệu đa phương thức độc quyền của Microsoft đa dạng lĩnh vực và bài toán như hiểu hình ảnh, hiểu và đưa ra lập luận về biểu đồ, bảng, sơ đồ, tóm tắt video,v.v.
Cuối cùng, để kết thúc quá trình huấn luyện, mô hình trải qua quá trình Direct Preference Optimization nhằm huấn luyện mô hình đưa ra các câu trả lời phù hợp với thị hiếu của con người, đồng thời quá trình này sẽ cải thiện chất lượng và sự hữu ích của câu trả lời. Giai đoạn này tập trung vào sử dụng bộ dữ liệu đa phương thức nhỏ hơn so với các giai đoạn trước đó.
Trong suốt quá trình Supervised Fine-Tuning và Direct Preference Optimization mô hình lần lượt được huấn luyện đồng thời các nhiệm vụ đa phương thức và tinh chỉnh chất lượng của câu trả lời. Cách huấn luyện này giúp mô hình có khả năng hiểu dữ liệu đầu vào tốt hơn trên nhiều định dạng khác nhau, đồng thời mô hình vẫn có khả năng đưa ra lập luận tốt và đưa ra phản hồi hợp lý.
4.2. Dữ liệu thực nghiệm
Để có thể đánh giá mô hình Phi 3.5 Vision với bài toán trích xuất thông tin văn bản, chúng tôi đã thu thập 100 bức ảnh hóa đơn mua hàng từ nhiều nguồn khác nhau: trên Kaggle và trên website internet. Dưới đây là một số hình ảnh ví dụ:

Hình 4.1: Dữ liệu hóa đơn mua hàng dùng để đánh giá kết quả mô hình.
Câu prompt được sử dụng để lấy thông tin là:
”What is the [feature] of the invoice? Answer short, no sentences! If the information is not available, return None.”
Trong đó, [feature] đại diện các trường thông tin cần lấy. Các trường này bao gồm “Retailer Name”, “Purchase Date”
Với các trường “Total Amount”, “Cash”, và “Change” câu prompt được sửa lại để tăng khả năng trích xuất các trường này:
“What is the Total Amount, Cash, and Change of the invoice? Answer short, no sentences! If the information is not available, return None”
Dưới đây là một mẫu ví dụ các trường thông tin cần lấy cho Hình 4.1 a:
{
“Retailer Name”: “MOMI & TOY’S”,
“Purchase Date”: “26/01/2015”,
“Total Amount”: 175,000,
“Cash”: 200,000,
“Change”: 25,000
}
4.3. Kết quả thực nghiệm
Bảng 4.1: Minh họa kết quả trích xuất thông tin của mô hình Phi 3.5 Vision với các ảnh hóa đơn mua hàng
| IMAGE | PROMPT | RESPONSE |
 | What is the Retailer Name of the invoice? Answer short, no sentences! If the information is not available, return None | WinCo FOODS |
| What is the Purchase Date of the invoice? Answer short, no sentences! If the information is not available, return None | 09/08/14 | |
| What is the Total Amount, Cash, and Change of the invoice? Answer short and follow this template: “x, y, z”, no sentences! If the information is not available, return None | 121.92, 0.00, 0.00 | |
 | What is the Retailer Name of the invoice? Answer short, no sentences! If the information is not available, return None | Walmart |
| What is the Purchase Date of the invoice? Answer short, no sentences! If the information is not available, return None | 22 July 2016 | |
| What is the Total Amount, Cash, and Change of the invoice? Answer short and follow this template: “x, y, z”, no sentences! If the information is not available, return None | 12.58, 12.58, 0.00 |
Dưới đây là kết quả trích xuất thông tin của mô hình Phi 3.5 Vision với độ chính xác trên năm trường dữ liệu yêu cầu:
Bảng 4.2: Kết quả đánh giá mô hình Phi 3.5 Vision trên năm trường dữ liệu trong hóa đơn mua hàng
| Feature | Retailer name | Purchase Date | Total Amount | Cash | Change |
| Độ chính xác | 99.13% | 89.31% | 82.37% | 67.21% | 87.54% |
Nhìn vào Bảng 4.1 và 4.2, chúng ta có thể thấy mô hình thể hiện khả năng xuất sắc trong việc xác định trường Retailer Name: độ chính xác lên đến 99.13%. Đối với các trường Purchase Date, Total Amount và Change, mô hình cũng đạt hiệu suất khả quan. Điều này cho thấy khả năng nắm bắt thông tin tương đối chính xác của Phi 3.5 Vision. Tuy nhiên, mô hình này vẫn còn tồn tại một số hạn chế cần lưu ý như: đôi khi nhầm lẫn giữa trường Total Amount và Cash, dẫn đến độ chính xác của trường Cash chỉ đạt 67.21%.
Về trường Change, mô hình thể hiện sự linh hoạt khi xử lý các trường hợp không có thông tin bằng cách trả về “None” hoặc “0.00”.
Nhìn chung, Phi 3.5 Vision chứng tỏ tiềm năng đáng kể trong việc giải quyết bài toán hiểu văn bản và trích xuất thông tin từ hình ảnh hóa đơn. Mặc dù việc tinh chỉnh mô hình có thể gặp khó khăn do yêu cầu lượng tài nguyên lớn và đôi khi xuất hiện kết quả không mong muốn, nhưng ưu điểm nổi bật của phương pháp này là không yêu cầu dữ liệu huấn luyện. Điều này cho phép áp dụng linh hoạt Phi 3.5 Vision trong nhiều bài toán khác nhau.
Chương 5: Kết luận
Nghiên cứu này cho thấy Vision Language Model là một hướng phát triển đầy tiềm năng trong bài toán trích xuất thông tin văn bản. Ưu điểm nổi bật của phương pháp này là khả năng thực hiện các tác vụ hỏi đáp từ hình ảnh ngay lập tức mà không cần bước finetuning. Phương pháp này còn có khả năng xử lý đa dạng tài liệu: từ hóa đơn, biên lai đến các văn bản quy phạm và cả các biểu mẫu viết tay. Ngoài ra, phương pháp này có thể kết hợp thông tin từ nhiều hình ảnh, từ đó nâng cao độ chính xác trong các bài toán trích xuất thông tin.
Bên cạnh những ưu điểm trên, VLM cũng tồn tại một số hạn chế. Thứ nhất, các mô hình VLM yêu cầu một lượng tài nguyên đáng kể để triển khai trên diện rộng. Để khắc phục điều này, một số mô hình siêu nhẹ [17], [18], [19] đã được phát triển nhằm nhúng các mô hình này trên các thiết bị nhỏ gọn. Thứ hai, hiệu quả của mô hình phụ thuộc nhiều vào chất lượng các câu prompt. Nếu prompt không tốt, mô hình có thể hiểu sai và đưa ra kết quả không chính xác.
Tóm lại, mặc dù Vision Language Model còn một số hạn chế về tài nguyên và phụ thuộc vào chất lượng prompt, đây vẫn là một hướng tiếp cận đầy hứa hẹn cho bài toán trích xuất thông tin văn bản với những ưu điểm nổi bật về khả năng xử lý đa dạng tài liệu.
Tài liệu tham khảo
[1]: ZHANG, Ziming; WARRELL, Jonathan; TORR, Philip HS. Proposal generation for object detection using cascaded ranking svms. In: CVPR 2011. IEEE, 2011. p. 1497-1504.
[2]: DU, Shuze; CHEN, Shifeng. Salient object detection via random forest. IEEE Signal Processing Letters, 2013, 21.1: 51-54.
[3]: KRIZHEVSKY, Alex; SUTSKEVER, Ilya; HINTON, Geoffrey E. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 2012, 25.
[4]: SIMONYAN, Karen. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
[5]: HE, Kaiming, et al. Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2016. p. 770-778.
[6]: ZHANG, Jingyi, et al. Vision-language models for vision tasks: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024.
[7]: HE, Tong, et al. Bag of tricks for image classification with convolutional neural networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019. p. 558-567.
[8]: XIE, Saining, et al. Aggregated residual transformations for deep neural networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2017. p. 1492-1500.
[9]: ZAGORUYKO, Sergey. Wide residual networks. arXiv preprint arXiv:1605.07146, 2016.
[10]: A. Radford et al. Learning transferable visual models from natural language supervision. In ICML, pp. 8748–8763. PMLR, 2021.
[11]: R. Girshick. Fast r-cnn. In ICCV, pp. 1440–1448, 2015.
[12]: M. Tan and Q. Le. Efficientnet: Rethinking model scaling for convolutional neural networks. In ICML, pp. 6105–6114. PMLR, 2019.
[13]: VASWANI, A. Attention is all you need. Advances in Neural Information Processing Systems, 2017.
[14]: J. Devlin et al. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
[15]: DOSOVITSKIY, Alexey. An image is worth 16×16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
[16]: A. Radford et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
[17]: LI, Yuanzhi, et al. Textbooks are all you need ii: phi-1.5 technical report. arXiv preprint arXiv:2309.05463, 2023.
[18]: ABDIN, Marah, et al. Phi-3 technical report: A highly capable language model locally on your phone. arXiv preprint arXiv:2404.14219, 2024.
[19]: JAVAHERIPI, Mojan, et al. Phi-2: The surprising power of small language models. Microsoft Research Blog, 2023, 1: 3.
[20]: GE, Z. Yolox: Exceeding yolo series in 2021. arXiv preprint arXiv:2107.08430, 2021.
[21]: ZENG, Yu-Xiang, et al. MixNet: toward accurate detection of challenging scene text in the wild. arXiv preprint arXiv:2308.12817, 2023.
[22]: YE, Jian, et al. TextFuseNet: Scene Text Detection with Richer Fused Features. In: IJCAI. 2020. p. 516-522.
[23]: LIAO, Minghui, et al. Real-time scene text detection with differentiable binarization. In: Proceedings of the AAAI conference on artificial intelligence. 2020. p. 11474-11481.
[24]: RANG, Miao, et al. An Empirical Study of Scaling Law for OCR. arXiv e-prints, 2023, arXiv: 2401.00028.
[25]: DU, Yongkun, et al. Svtr: Scene text recognition with a single visual model. arXiv preprint arXiv:2205.00159, 2022.
[26]: BAUTISTA, Darwin; ATIENZA, Rowel. Scene text recognition with permuted autoregressive sequence models. In: European conference on computer vision. Cham: Springer Nature Switzerland, 2022. p. 178-196.
[27]: XU, Yang, et al. Layoutlmv2: Multi-modal pre-training for visually-rich document understanding. arXiv preprint arXiv:2012.14740, 2020.
[28]: HUANG, Yupan, et al. Layoutlmv3: Pre-training for document ai with unified text and image masking. In: Proceedings of the 30th ACM International Conference on Multimedia. 2022. p. 4083-4091.
[29]: HONG, Teakgyu, et al. Bros: A pre-trained language model focusing on text and layout for better key information extraction from documents. In: Proceedings of the AAAI Conference on Artificial Intelligence. 2022. p. 10767-10775.
[30]: ACHIAM, Josh, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
[31]: DENG, Jia, et al. Imagenet: A large-scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009. p. 248-255.
[32]: SCHUHMANN, Christoph, et al. Laion-5b: An open large-scale dataset for training next generation image-text models. Advances in Neural Information Processing Systems, 2022, 35: 25278-25294.
[33]: SCHUHMANN, Christoph, et al. Laion-400m: Open dataset of clip-filtered 400 million image-text pairs. arXiv preprint arXiv:2111.02114, 2021.
[34]: XIAO, Bin, et al. Florence-2: Advancing a unified representation for a variety of vision tasks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024. p. 4818-4829.