Bài toán trích rút thông tin từ hóa đơn giá trị gia tăng
I. Tổng quan
Hóa đơn là một loại giấy tờ thiết yếu được sử dụng trong các giao dịch tài chính, nhằm mục đích cung cấp hồ sơ về hàng hóa hoặc dịch vụ được trao đổi cùng với các chi phí liên quan. Chính vì thế, việc nhập liệu và số hóa các hóa đơn có thể giúp doanh nghiệp theo dõi phân tích và ra quyết định, chẳng hạn như xác định xu hướng chi phí, giám sát hoạt động của nhà cung cấp và tối ưu hóa quy trình mua – bán. Tuy nhiên, nhập liệu bằng phương pháp thủ công không chỉ gây lãng phí về nguồn lực nhân sự của doanh nghiệp mà còn dễ gây ra lỗi, điều này có thể dẫn đến những sai lầm tốn kém và sự chậm trễ trong hoạt động kinh doanh. Tự động hóa quy trình trích rút thông tin chính từ hóa đơn có thể cải thiện đáng kể hiệu quả của hoạt động kinh doanh và giảm thiểu những rủi ro không đáng có.
Với sự phát triển ngày càng mạnh mẽ của các mô hình máy học, việc tự động trích rút thông tin chính từ hóa đơn đạt được hiệu năng và độ ổn định cực kì ấn tượng. Trích rút thông tin tự động bao gồm quá trình xác định vị trí và nội dung của các phần khác nhau trong văn bản, sau đó phân loại văn bản thành các trường thông tin được định nghĩa từ trước như số hóa đơn, ngày, tổng số tiền và chi tiết nhà cung cấp.
Trong bài viết này, chúng ta cùng tìm hiểu về ứng dụng của mô hình LayoutLM [1] để trích rút thông tin chính từ dữ liệu hóa đơn. LayoutLM là mô hình học sâu mạnh mẽ và dẫn đầu trong việc kết hợp cả dữ liệu văn bản và dữ liệu hình ảnh để tối ưu hiệu năng. Hiện nay, LayoutLM được ứng dụng trong nhiều bài toán xử lí văn bản lớn như Phân loại ảnh văn bản, Trích rút thông tin từ giấy tờ tùy thân.
II. Đặc thù của bài toán trích rút thông tin từ hóa đơn
Khác với bài toán Trích rút thông tin từ giấy tờ tùy thân, trích rút thông tin hóa đơn đối mặt với nhiều thách thức lớn.
- Đầu tiên, hóa đơn có nhiều định dạng và bố cục khác nhau, khiến việc chuẩn hóa quy trình trích rút trên tất cả các hóa đơn trở nên khó khăn. Bố c
- ục của các hóa đơn có thể khác nhau tùy thuộc vào nhà cung cấp, quốc gia hoặc ngành, khiến việc tạo một mô hình trích rút duy nhất hoạt động cho tất cả các hóa đơn trở nên khó khăn.
- Thứ hai, hóa đơn có thể dài, chứa nhiều trang thông tin, điều này có thể làm phức tạp thêm quá trình trích rút. Thông tin liên quan có thể được trải rộng trên nhiều trang hoặc nhiều phần của hóa đơn, khiến việc xác định và trích rút tất cả thông tin cần thiết trở nên khó khăn.
- Thứ ba, một số trường thông tin trong hóa đơn có thể gây nhầm lẫn ngay cả đối với con người. Chẳng hạn, hóa đơn thường chứa các trường thông tin có đặc trưng tương tự và dễ gây nhầm lẫn như “tên người bán” và “tên người mua” dẫn đến nhầm lẫn, sai sót trong quá trình trích rút.
- Cuối cùng, hóa đơn cũng có thể chứa lỗi hoặc thiếu thông tin, khiến việc trích rút chính xác tất cả thông tin cần thiết trở nên khó khăn. Ví dụ: hóa đơn có thể không có thông tin liên hệ của nhà cung cấp hoặc số tiền trên hóa đơn có thể không chính xác.
Nhìn chung, sự thay đổi trong các định dạng hóa đơn, độ dài của mỗi tài liệu, khả năng thông tin được trải rộng trên nhiều trang và khả năng nhầm lẫn hoặc sai sót đều góp phần gây ra những thách thức trong việc trích rút thông tin từ hóa đơn. Những thách thức này nhấn mạnh tầm quan trọng của việc phát triển các kỹ thuật phức tạp để trích rút thông tin từ hóa đơn nhằm giảm sai sót và nâng cao hiệu quả hoạt động kinh doanh.

Hình 1. a) Một loại hóa đơn giá trị gia tăng tiêu biểu được sử dụng rộng rãi tại Việt Nam. b) Trường hợp hóa đơn cần trích rút và tổng hợp thông tin từ nhiều trang.
Lưu ý: hóa đơn trên chỉ mang tính chất giả định và không có thật.
III. LayoutLM cho bài toán trích rút thông tin từ hóa đơn
LayoutLM là một mô hình học sâu dựa trên ý tưởng của BERT [4] (mô hình ngôn ngữ sử dụng kiến trúc Transformers [2]), được tiền huấn luyện trên lượng lớn dữ liệu văn bản và nhờ đó có tính tổng quát cao trên cả các đặc trưng về hình ảnh và ngữ nghĩa của nhiều loại tài liệu khác nhau. Ứng dụng vào bài toán trích rút thông tin hóa đơn tiếng Việt, ta sử dụng một biến thể của LayoutLM được gọi là LayoutXLM [3] để trích rút thông tin chính từ hóa đơn. LayoutXLM là một mô hình được tinh chỉnh trên nhiều ngôn ngữ, bao gồm cả tiếng Việt. Mô hình sử dụng kết hợp các thông tin về nội dung văn bản từ OCR (Nhận dạng ký tự quang học) và phát hiện đối tượng để định vị và trích rút các trường thông tin cần thiết như số hóa đơn, ngày tháng, tổng số tiền và chi tiết nhà cung cấp.
Như đã đề cập, hóa đơn là loại tài liệu phức tạp và có nhiều thách thức trong việc trích rút thông tin. Với LayoutXLM, ta có thể xử lý hóa đơn tiếng Việt một cách hiệu quả và trích rút thông tin liên quan một cách chính xác. Bài toán trích rút thông tin được mô hình lại thành bài toán phân loại token (Token classification), trong đó LayoutXLM có nhiệm vụ phân biệt các token (đặc trưng cho nội dung và vị trí của các từ trong văn bản) thuộc về các trường thông tin nào. Mô hình được tinh chỉnh trên tập dữ liệu hóa đơn tiếng Việt được gán nhãn về vị trí, nội dung và trường thông tin của từng từ. Điều này cho phép mô hình hiểu được bố cục của hóa đơn và trích rút chính xác thông tin cần thiết.
1. Xử lý dữ liệu
Xử lý dữ liệu là quá trình chuyển đổi hình ảnh hóa đơn thành định dạng mà mô hình có thể hiểu được. Trong bài toán trích rút thông tin, ta chuyển đổi hình ảnh hóa đơn thành một bộ token theo đúng định dạng mà mô hình LayoutXLM đã được tiền huấn luyện bằng cách sử dụng mô hình OCR.
Đầu vào của mô hình bao gồm một tập hợp các tokens, mỗi token đại diện cho nội dung và vị trí của một từ hoặc từ phụ trong văn bản hóa đơn. Các tokens này được tạo bằng cách sử dụng WordPiece, phân tách các từ thành các từ phụ nhỏ hơn dựa trên từ vựng được xác định trước. Một ví dụ đơn giản là từ hóa đơn có thể được phân tách thành các tokens là {h, óa, đ, ơn}. Quá trình phân tách token tạo một chuỗi token đại diện cho văn bản hóa đơn và bao gồm các token đặc biệt như [CLS] (phân loại), [SEP] (dấu phân cách) và [PAD] (phần đệm). Dưới đây là một đoạn code xử lí dữ liệu đơn giản sử dụng trình phân tách token (tokenizer) đi kèm với mô hình LaytoutXLM được tích hợp trong thư viện transformers của Huggingface:
features = Features({
'image': Array3D(dtype="int64", shape=image_shape),
'input_ids': Sequence(feature=Value(dtype='int64')),
'attention_mask': Sequence(Value(dtype='int64')),
'bbox': Array2D(dtype="int64", shape=(max_seq_len, 4)),
'labels': Sequence(ClassLabel(names=kie_labels))
})
tokenizer = LayoutXLMTokenizer.from_pretrained(
pretrained_processor, model_max_length=max_seq_len)
feature_extractor = LayoutLMv2FeatureExtractor(apply_ocr=False)
processor = LayoutXLMProcessor(feature_extractor, tokenizer)
# Process examples
encoded_inputs = processor(
images, padding="max_length", truncation=True, text=words,
boxes=normalized_word_boxes, word_labels=word_labels,
max_length=max_seq_length
)Ngoài ra, để mô hình LayoutLM có thể ổn định hơn với các sai sót của mô hình OCR, chúng ta có thể làm nhiễu dữ liệu đầu ra OCR trong quá trình huấn luyện. Điều này sẽ tạo ra một tập dữ liệu đào tạo đa dạng và tổng quát hơn cho mô hình LayoutLM ngay cả khi phân phối đầu ra OCR. Điều này có thể giúp ngăn tình trạng giảm hiệu suất của mô hình LayoutLM do sự phân bổ đầu ra OCR thay đổi theo thời gian.
def perturbate_character(words: list):
for word in words:
word = append_random_char_to_the_left(word)
word = append_random_char_to_the_right(word)
word = another_random_char_at_middle(word)
word = delete_char_at_current_position(word)
return wordsĐầu ra của mô hình là một tập hợp các tokens đã được phân loại thành các lớp, mỗi lớp đại diện cho một loại trường thông tin cụ thể như số hóa đơn, ngày hoặc chi tiết nhà cung cấp. Mô hình xuất ra một nhãn cho mỗi mã thông báo trong chuỗi, cho biết loại trường mà mã thông báo thuộc về. Ví dụ: mã thông báo có thể được gắn nhãn là “số hóa đơn” hoặc “tổng số tiền”. Định dạng đầu ra này cho phép chúng tôi dễ dàng trích rút các trường thông tin có liên quan từ hóa đơn và sử dụng chúng cho các ứng dụng tiếp theo như tài khoản phải trả hoặc phân tích dữ liệu.
2. Huấn luyện mô hình
Trong quá trình đào tạo, mô hình được học dữ liệu được gắn nhãn theo từng trường thông tin sẽ được trích rút từ hóa đơn. Mô hình được đào tạo để phân loại từng token đầu vào thành các danh mục khác nhau, chẳng hạn như ngày, số hóa đơn và tổng số tiền.
def train_one_epoch(self, dataloader):
self.model.train()
running_loss = 0.0
total, correct = 0, 0
for batch in tqdm(dataloader):
# forward pass
outputs = self.model(**batch)
loss = outputs.loss
running_loss += loss.item()
predictions = outputs.logits.argmax(dim=2)
valid_samples = (batch['labels'] != -100)
predictions = predictions[valid_samples]
batch_labels = batch['labels'][valid_samples]
correct += (predictions == batch_labels).float().sum()
total += predictions.numel()
# backward pass to get the gradients
loss.backward()
# update
self.optimizer.step()
self.optimizer.zero_grad()Sau khi mô hình được đào tạo, nó có thể được sử dụng để trích rút thông tin chính từ hóa đơn mới.
3. Đánh giá mô hình
Sau khi huấn luyện LayoutXLM, ta cần đánh giá hiệu suất của nó trên tập dữ liệu thử nghiệm. Tập dữ liệu thử nghiệm phải bao gồm các hóa đơn khác với hóa đơn trong tập dữ liệu huấn luyện. Điều này sẽ giúp chúng tôi đánh giá hiệu suất tổng quát hóa của mô hình.
Để đánh giá LayoutXLM, ta sử dụng các thang đo là độ chính xác (accuracy) và điểm F1 (F1-score). Độ chính xác đo tỷ lệ các nhãn dương tính được dự đoán là chính xác còn điểm F1 đặc trưng cho giá trị trung bình hài hòa của độ chuẩnxác (precision) và khả năng thu hồi (recall).
Chúng ta có thể sử dụng các kỹ thuật như ma trận nhầm lẫn (confusion matrix) để trực quan hóa hiệu suất của mô hình và xác định các khu vực cần cải thiện.
def val_one_epoch(self, dataloader):
self.model.eval()
total, correct = 0, 0
preds, truths = [], []
for batch in tqdm(dataloader):
with torch.no_grad():
outputs = self.model(**batch)
predictions = outputs.logits.argmax(dim=2)
valid_samples = (batch['labels'] != -100)
predictions = predictions[valid_samples]
batch_labels = batch['labels'][valid_samples]
preds.extend(predictions.detach().cpu().numpy().tolist())
truths.extend(batch_labels.detach().cpu().numpy().tolist())
correct += (predictions == batch_labels).float().sum()
total += predictions.numel()
accuracy = 100 * correct / total
p, r, f1, support = precision_recall_fscore_support(truths, preds)
return accuracy, f1IV. Kết quả thực nghiệm
Tiến hành thực nghiệp trên tập dữ liệu tự tổng hợp gồm 2000 ảnh hóa đơn, trong đó 1500 ảnh được sử dụng để huấn luyện và 500 ảnh được sử dụng để đánh giá. Kết quả thực nghiệm cho thấy mô hình LayoutXLM đạt độ chính xác là 99,36% và điểm F1 là 98,01% ở tác vụ phân loại token. Đây là một hiệu suất ấn tượng và chỉ ra rằng mô hình có thể nhận dạng và phân loại chính xác các trường khác nhau có trong hóa đơn.
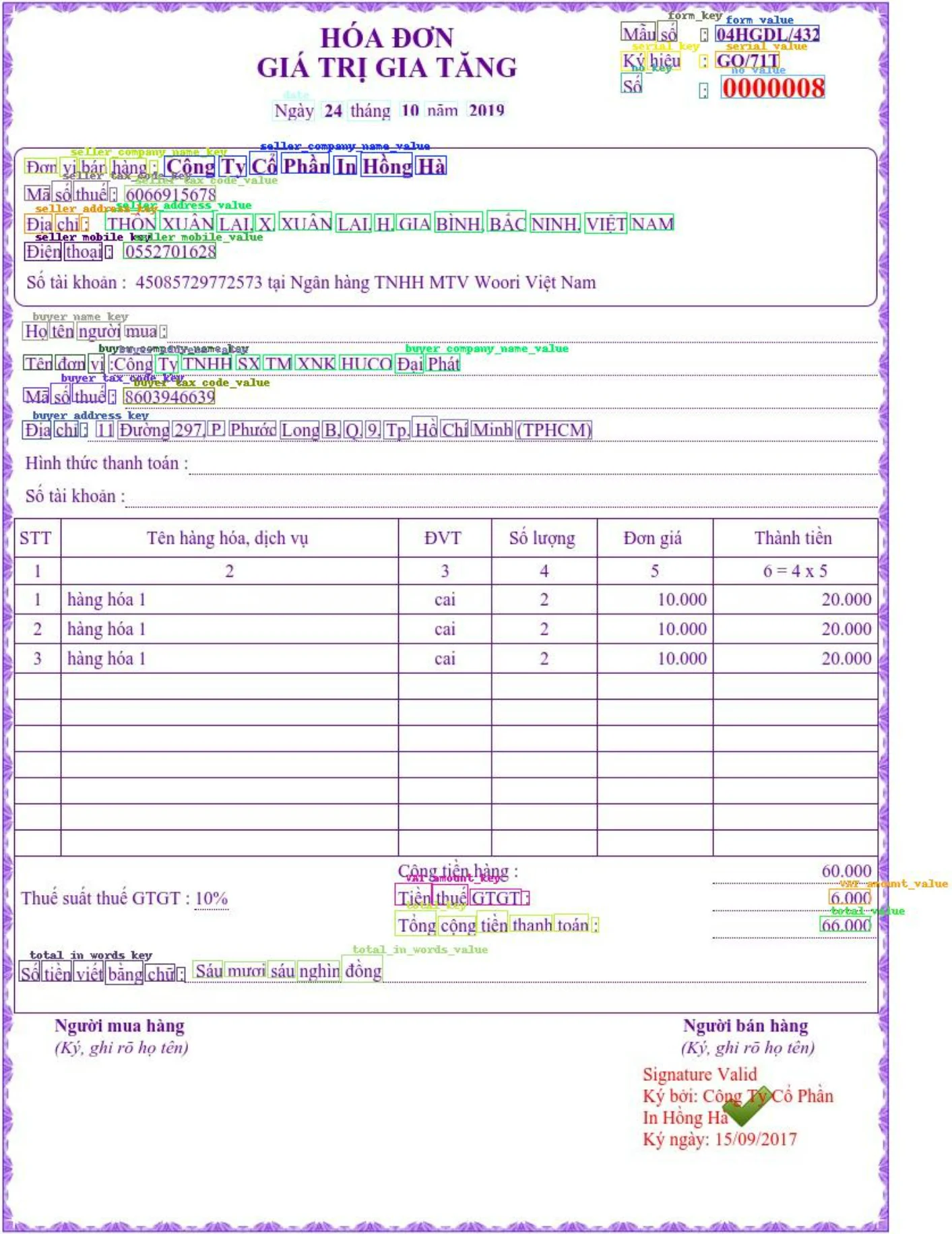
Hình 2. Kết quả trích rút thông tin sử dụng mô hình LayoutXLM
Lưu ý: hóa đơn trên chỉ mang tính chất giả định và không có thật.
Tuy nhiên, hiệu năng trên chỉ thể hiện khả năng phân loại của mô hình LayoutXLM. Trong một hệ thống trích rút thông tin, độ chính xác của trường thông tin trích rút được còn phụ thuộc vào mô hình OCR và các thuật toán tiền-hậu xử lí. Do đó, để đánh giá hiệu suất đầu-cuối (end-to-end), ta sử dụng thang đo khoảng cách chỉnh sửa chuẩn hóa (Normalized edit distance – NED) [5], còn được gọi là khoảng cách Levenshtein chuẩn hóa (Normalized Levenshtein distance), cho từng trường thông tin. NED đo lường số lần chèn (insert), xóa (delete) hoặc thay thế (replace) trung bình cần thiết để chuyển đổi văn bản trường thông tin trích rút được thành văn bản trường thông tin gốc. NED thường được đo ở cấp độ từng chữ (character level), tuy nhiên có thể được tùy chỉnh để đo ở các cấp độ cao hơn như từng từ (word-level). Hiệu năng của mô hình càng cao khi NED càng thấp, chính vì vậy, ta có thể sử dụng độ đo 1-NED để ước lượng chính xác số lượng kí từ hoặc từ mà hệ thống trích rút thông tin đã trích rút thành công.
| class_name | 1-NED | 1-NED_word | #samples |
| no_value | 0.9883 | 0.9841 | 298 |
| form_value | 0.9975 | 0.9926 | 294 |
| serial_value | 0.9786 | 0.9773 | 294 |
| date | 0.9689 | 0.9627 | 292 |
| VAT_amount_value | 0.9606 | 0.9506 | 258 |
| total_value | 0.9807 | 0.9713 | 287 |
| avg_all | 0.9791 | 0.9731 | 1723 |
Nhìn vào kết quả, chúng ta có thể thấy rằng hệ thống trích rút thông tin đạt được hiệu năng ấn tượng và ổn định trên nhiều trường dữ liệu khác nhau, đồng thời đạt được hiệu năng tổng thể là 97.31% với thang đo NED theo từ. Xem xét việc kết quả được thực nghiệm trên một tập dữ liệu tương đối nhỏ là 2000 mẫu, hiệu năng này được đánh giá là triển vọng và có tiềm năng phát triển mạnh mẽ.
Tóm lại, LayoutXLM là một mô hình ngôn ngữ được đào tạo trước mạnh mẽ có thể được tinh chỉnh để thực hiện trích rút thông tin chính từ hóa đơn. Kết quả thực nghiệm cho thấy rằng LayoutXLM đạt được độ chính xác cao và điểm F1 trên một bộ dữ liệu gồm 2000 tài liệu. Ngoài ra, hiệu năng đầu-cuối sử dụng thang đo khoảng cách chỉnh sửa được chuẩn hóa cho từng trường thông tin và đạt được kết quả khả quan, cho thấy khả năng khái quát hóa tốt dữ liệu mới của mô hình.
V. Kết luận
Việc sử dụng LayoutXLM để trích rút thông tin chính trong hóa đơn mang lại nhiều lợi ích. Khả năng xử lý vấn đề tài liệu dài đặc biệt hữu ích để trích rút thông tin từ các hóa đơn dài. Ngoài ra, mô hình này có thể trích rút thông tin từ hóa đơn bằng nhiều ngôn ngữ, rất hữu ích cho các doanh nghiệp hoạt động trên phạm vi quốc tế. Nhìn chung, thử nghiệm của chúng tôi chứng minh tính hiệu quả của LayoutXLM đối với việc trích rút thông tin chính của hóa đơn và tiềm năng sử dụng của nó trong các tác vụ xử lý tài liệu tương tự khác.
Cần lưu ý rằng các số liệu thực nghiệm trong phạm vi bài viết chỉ mang tính chất minh họa trên một tập dữ liệu tự tổng hợp và tương đối nhỏ. Trong hệ thống thực tế, hiệu năng tổng thể có thể được nâng cấp nhiều lần bằng cách tăng cường số lượng mẫu cũng như hiệu suất xử lí dữ liệu, đồng thời kết hợp với việc tùy chỉnh và các cải tiến trong quá trình huấn luyện mô hình. Ngoài điều kiện cần là kiến thức chuyên môn, đội ngũ phát triển hệ thống còn cần có đủ kinh nghiệm và lượng lớn thời gian thử nghiệm các phương pháp khác nhau để có thể tối ưu hóa cả về hiệu năng lẫn tốc độ của hệ thống. Một phiên bản thương mại của hệ thống trích rút thông tin với hóa đơn (với lượng lớn mẫu dữ liệu huấn luyện trên nhiều định dạng hóa đơn khác nhau) đã được chúng tôi triển khai trên nền tảng COPE2N. Bạn đọc có thể truy cập, đăng kí tài khoản và dùng thử miễn phí để có cái nhìn trực quan hơn về cách hoạt động cũng như hiệu năng của hệ thống trích rút thông tin cho hóa đơn.