Từ hội thoại tới Insights: Tận dụng mô hình ngôn ngữ lớn vào chuyển đổi ngôn ngữ tự nhiên sang SQL và tự động hóa trực quan dữ liệu
Giới thiệu
Bài viết này trình bày những tiến bộ vượt bậc trong các bài toán Text2SQL và Text2Chart, nhờ vào việc ứng dụng các mô hình ngôn ngữ lớn (LLM). Những phát triển này mở ra tiềm năng lớn cho việc ứng dụng hệ thống giao diện ngôn ngữ tự nhiên hướng tới trực quan hóa dữ liệu (Visualization-oriented Natural Language Interfaces V-NLI) vào thực tế, giúp doanh nghiệp đạt được độ chính xác cao trong phân tích dữ liệu. Bài viết sẽ đề cập đến các nội dung chính sau:
- V-NLI: Ý tưởng sử dụng giao diện ngôn ngữ tự nhiên cho phân tích và trực quan hóa dữ liệu.
- Tầm quan trọng của Text2SQL và Text2Chart
- Sự phát triển của Text2SQL và các đột phá gần đây nhờ ứng dụng LLM.
- Text2Chart, tương tự Text2SQL nhưng còn nhiều khó khăn
- Tiềm năng mở rộng Text2Chart
- Các khó khăn, ứng dụng và hướng phát triển cho hệ thống V-NLI trong bối cảnh thực tiễn doanh nghiệp.
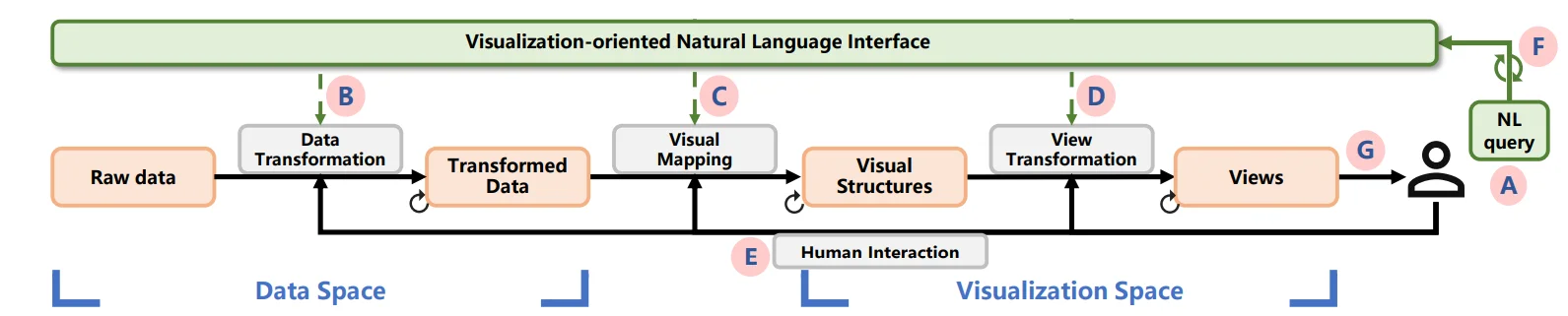
V-NLI: Ý tưởng sử dụng giao diện ngôn ngữ tự nhiên cho phân tích dữ liệu
Với sự gia tăng về độ phức tạp và khối lượng dữ liệu, truy vấn và trực quan hóa trở nên khó khăn hơn, thường đòi hỏi kỹ thuật cao như viết truy vấn SQL hoặc tinh chỉnh biểu đồ trong các phần mềm như Power BI hay Tableau. Quá trình này tốn thời gian và gây khó khăn cho người không chuyên trong việc tự cập nhật.
Ý tưởng về việc xây dựng hệ thống giao diện ngôn ngữ tự nhiên hướng tới trực quan hóa dữ liệu được lần đầu giới thiệu vào năm 2001 (Cox et al.). Cox và đồng nghiệp đã xây dựng một hệ thống giúp các chuyên gia đầu ngành dễ dàng trích xuất, biểu diễn và phân tích thông tin từ các tập dữ liệu lớn thông qua giọng nói. Hệ thống thực hiện chuyển giọng nói sang văn bản và phân tích câu hỏi của người dùng thành các thuộc tính cần thiết để tự động thực hiện truy vấn cơ sở dữ liệu và vẽ biểu đồ, giúp người dùng tập trung vào việc phân tích mà không cần tìm hiểu về cách vận hành các công cụ phức tạp. Đồng thời, nhờ giao diện đơn giản, người dùng cũng có thể dễ dàng phân tích và chia sẻ kết quả phân tích từ các thiết bị cầm tay như điện thoại thông minh hay máy tính bảng. Trong hai thập kỷ qua, đã có nhiều hệ thống V-NLI nổi bật được phát triển, bao gồm cả nghiên cứu học thuật (NL4DV) và sản phẩm thương mại (Tableau Ask Data; Power BI Q&A; Amazon QuickSight, Qlik Sense).
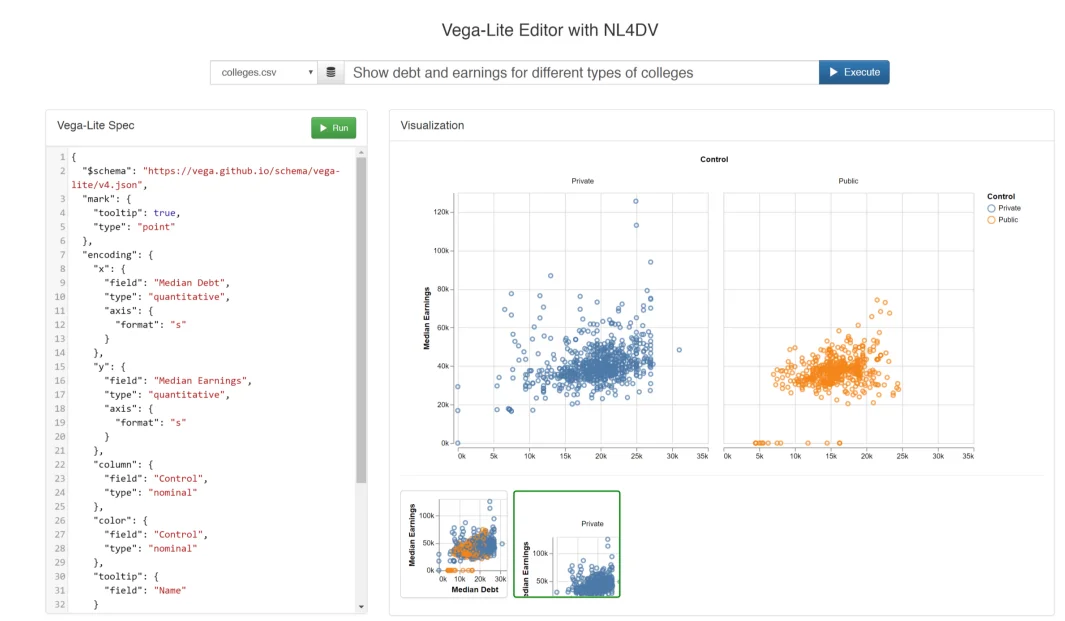
Hình 1: Sản phẩm NL4DV. Tự động đề xuất và sinh các biểu đồ phù hợp để trả lời câu hỏi. Chương trình sinh ra một json object theo ngữ pháp trực quan (grammar of graphics) của Vega-Lite. Giao diện đơn giản cho phép người dùng tùy chỉnh dễ dàng, tuy nhiên vẫn chưa hỗ trợ tùy chỉnh bằng "ngôn ngữ tự nhiên" và cần người dùng phải hiểu về cấu trúc Vega-Lite. 
Tầm quan trọng của Text2SQL và NL2Vis
Khi v-NLI lần đầu được giới thiệu, Cox và đồng nghiệp đã kết hợp Text2SQL và NL2Vis trong framework InfoStill bằng cách tách câu hỏi thành các thuộc tính gồm: cột, điều kiện, loại biểu đồ để điền vào các template SQL và hệ thống trực quan có sẵn. Tuy nhiên, bài toán Text2SQL thu hút nhiều sự quan tâm nghiên cứu hơn NL2Vis nhờ vào tính ứng dụng cao hơn. Cộng đồng v-NLI sau đó đã chia hệ thống v-NLI thành 3 bài toán lớn (Arjun, 2017):
- Trực quan dữ liệu tự động và có tính giải thích theo yêu cầu (NL2Vis)
- Tổng hợp dữ liệu từ hệ thống đầu vào theo yêu cầu (Text2SQL)
- Xây dựng một giao diện tương tác người-máy (human-centered interface)
Tự động hóa Text2SQL và NL2Vis không chỉ giúp giảm thiểu đáng kể tài nguyên cần thiết để xây dựng và duy trì các hệ thống v-NLI, mà còn mở ra tiềm năng lớn cho việc mở rộng hệ thống. Việc tối ưu hóa hai bài toán này cho phép tăng độ phức tạp của câu hỏi và dữ liệu, đồng thời bổ sung các tính năng tương tác, cập nhật, và diễn giải biểu đồ. Nghiên cứu về bài toán Text2SQL đang trở thành một hướng đi tiềm năng và phát triển mạnh mẽ, đặc biệt là sau sự ra đời của các mô hình ngôn ngữ lớn (LLM). Những tiến bộ đột phá trong lĩnh vực này đang biến việc truy cập cơ sở dữ liệu trở nên dễ dàng hơn đối cả với với những người dùng không chuyên.
Sự phát triển của Text2SQL
Text2SQL là một công nghệ đột phá trong ứng dụng AI tới người dùng, phép người dùng truy vấn cơ sở dữ liệu bằng ngôn ngữ tự nhiên thay vì cú pháp SQL truyền thống. Framework truyền thống cho Text2SQL sẽ gồm các tác vụ như dưới đây.
- Hiểu ngôn ngữ tự nhiên (Natural Language Understanding): Hệ thống trước tiên xử lý văn bản đầu vào để hiểu ý định của người dùng và trích xuất thông tin liên quan, như đối tượng, loại tác vụ và các điều kiện cho truy vấn tiếp theo.
- Phân tích ngữ nghĩa (Attribute Inference): Thông tin trích xuất sau đó được ánh xạ vào các phần tử trong lược đồ có sẵn; như tên bảng, tên cột trong SQL hay tên biểu đồ, tên các chiều dữ liệu trong Chart.
- Tạo mã nguồn (Task Inference): Dựa trên biểu diễn ngữ nghĩa, hệ thống tạo ra truy vấn đến cơ sở dữ liệu hoặc tới trình vẽ biểu đồ tương ứng.
- Thực Thi (Execute): Truy vấn SQL và lệnh được thực thi trên cơ sở dữ liệu và kết quả được trả về cho người dùng.
Ban đầu, các phương pháp truyền thống như template-based hay rule-based được sử dụng (Zelle và Mooney, 1996; Li and Jagadish, 2014; ). Cách tiếp cận này đòi hỏi việc xây dựng các mẫu (template) cho từng trường hợp câu hỏi cụ thể, tuy có tính giải thích cao và chất lượng hứa hẹn nhưng lại cần nhiều nguồn lực để xây dựng, chỉnh sửa và rất khó để mở rộng.
Với sự tiến bộ nhanh chóng của học sâu, các phương pháp Seq2Seq (Sutskever et al., 2014; Luo et al., 2018) đã đem lại nhiều kết quả vượt trội và trở thành hướng nghiên cứu tiềm năng. Các phương pháp này tập trung vào việc mã hóa đồng thời câu hỏi cùng với lược đồ dữ liệu và giải mã để dự đoán câu lệnh mã nguồn đích, tương tự bài toán dịch máy, với ngôn ngữ nguồn là ngôn ngữ tự nhiên, ngôn ngữ đích là SQL hay ngôn ngữ trực quan phù hợp. Phương pháp này có thể hỗ trợ ánh xạ trực tiếp, loại bỏ các bước trung gian như đã liệt kê ở trên và tạo ra một hệ thống đầu cuối hoàn chỉnh. Cho tới trước năm 2022, các mô hình ngôn ngữ huấn luyện sẵn (mô hình ngôn ngữ dạng Seq2Seq) vẫn đem lại kết quả vượt trội, điển hình là CatSQL, PICARD hay SmBoP.
Một số bộ dữ liệu lớn để sử dụng làm benchmark cũng đã được phát triển cho việc nghiên cứu:
Các phương pháp áp dụng LLM vào Text2SQL
Từ khi các mô hình ngôn ngữ lớn xuất hiện, đã có nhiều nỗ lực ứng dụng phương pháp này vào cả 2 bài toán Text2SQL và NL2Vis (Maddigan P. 2023). Các mô hình ngôn ngữ lớn gần đây như ChatGPT, GPT4 (Openai), LLAMA (Facebook), Gemini (Google)…đã thể hiện khả năng vượt trội trong việc giao tiếp giống con người và khả năng suy luận, hiểu những truy vấn phức tạp ngay cả khi không sử dụng trực tiếp dữ liệu huấn luyện của bài toán. Giống như phương pháp sử dụng Seq2Seq, các phương pháp sử dụng LLM xây dựng luồng ánh xạ trực tiếp từ ngôn ngữ tự nhiên. Cho tới năm 2023 thì LLM đã trở thành phương pháp cho kết quả vượt trội hơn hẳn những phương pháp Seq2Seq vốn đang là SOTA (Hình 3).
Trong bài sẽ đề cập tới 2 cách ứng dụng LLM đang cho kết quả với độ chính xác tốt nhất là:
- prompt engineering: kỹ thuật tinh chỉnh câu lệnh prompt, giúp “Ra lệnh” cho LLM một cách hiệu quả, giúp tạo ra câu SQL với độ chính xác cao nhất
- fine-tuning: quá trình tinh chỉnh mô hình ngôn ngữ lớn đã được tiền huấn luyện bằng cách sử dụng bộ dữ liệu mới (chất lượng cao) giúp cải thiện chất lượng mô hình trên một nhiệm vụ cụ thể.
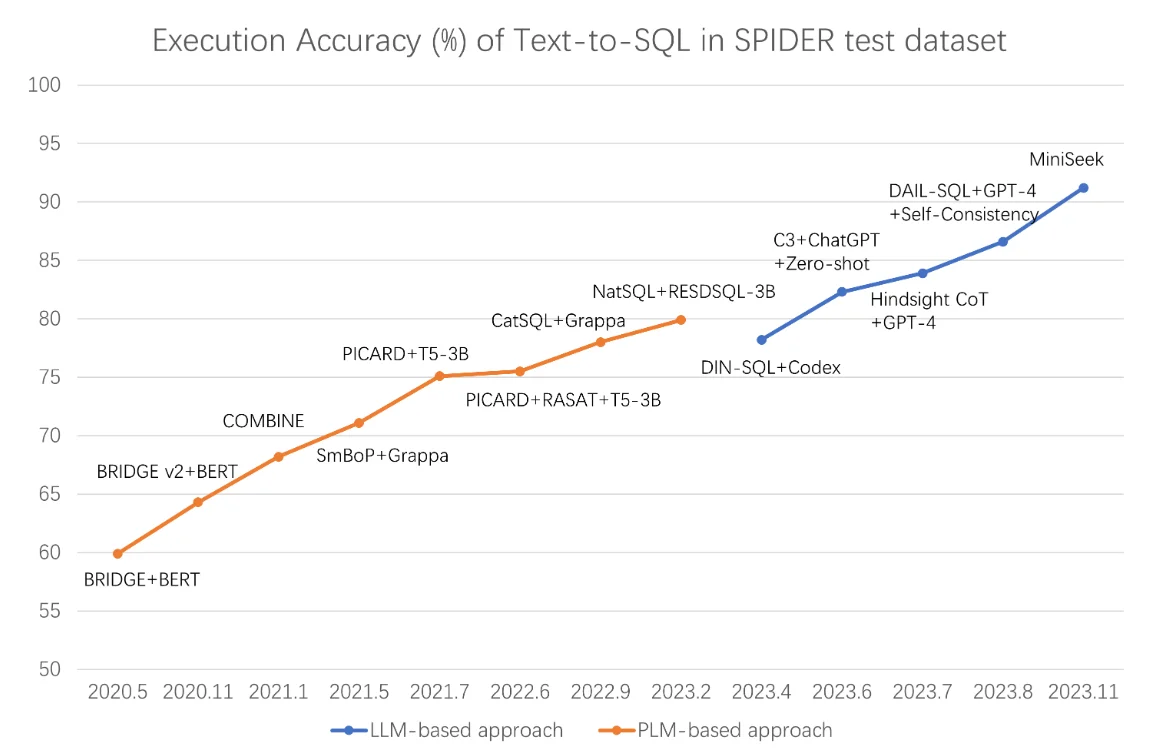
Hình 4: So sánh kết quả của các phương pháp học sâu hoặc phương pháp LLM qua các năm trên bộ dữ liệu Spider.
Prompt engineering
Prompt-engineering không đòi hỏi xây dựng bộ dữ liệu huấn luyện hay phần cứng để huần luyện mô hình. Các phương pháp sử dụng prompt engineering tập trung vào việc cung cấp cho LLM ngữ cảnh đầy đủ về cơ sử dữ liệu, prompt với cấu trúc rõ ràng, cung cấp ví dụ mẫu hay một số kỹ thuật prompt engineering khác (tham khảo Prompt Engineering Guide | Prompt Engineering Guide (promptingguide.ai))
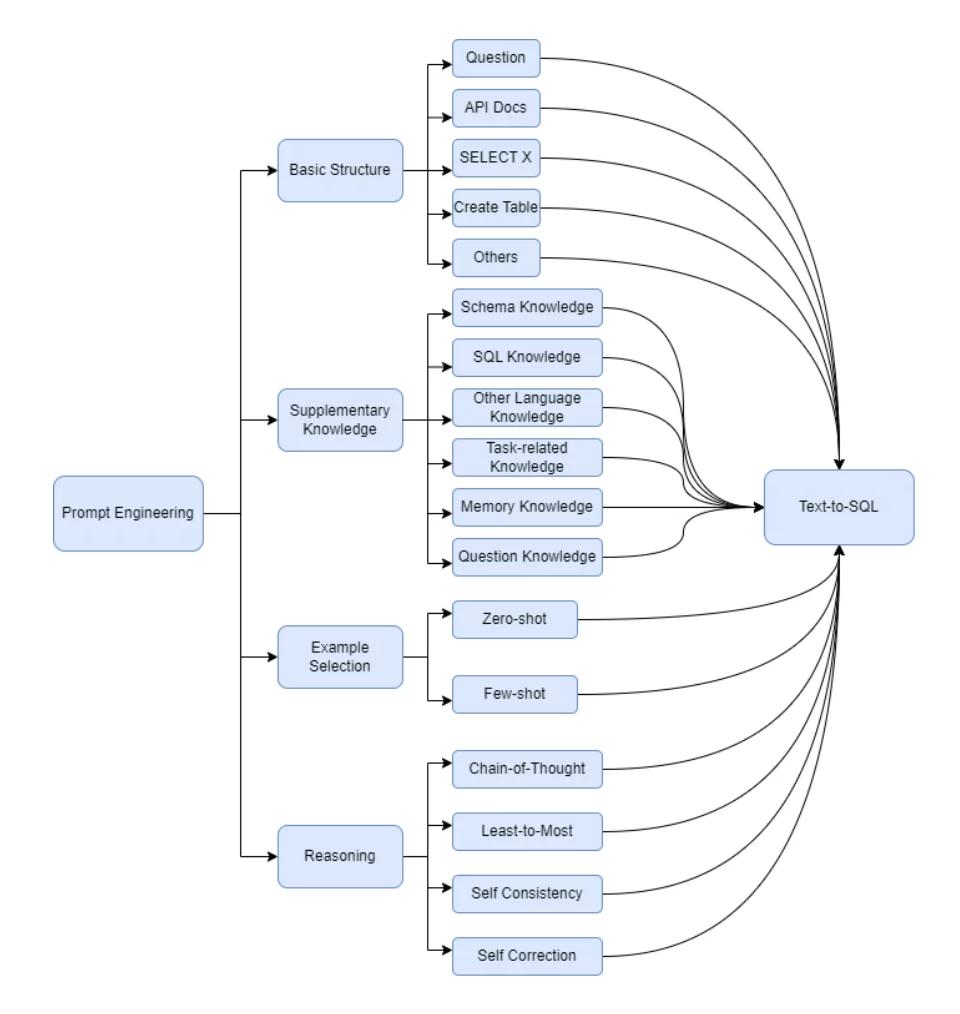
Hình 5: Phân loại các phương pháp prompt engineering cho Text2SQL.
Cấu trúc cơ bản của prompt cho bài toán Text2SQL:
- Instruction task hay system prompt: Chỉ dẫn cho mô hình về nhiệm vụ cần thực hiện là chuyển câu hỏi đầu vào sang câu query SQL. Ví dụ:
- Generate a SQL query to answer [QUESTION]{user_question}[/QUESTION] (sqlcoder)
- Answer the question by SQLite SQL query only and with no explanation. You must minimize SQL execution time while ensuring correctness. (PET-SQL)
- Câu hỏi tự nhiên: câu hỏi đầu vào đã qua làm sạch, tiền xử lý (ví dụ: dịch sang tiếng Anh)
- Database schema (Data Definition Language-DDL)
- Script SQL dùng để khởi tạo cơ sở dữ liệu
- Sử dụng thêm comment giải thích ngắn gọn, rõ ràng dữ liệu lưu trong từng cột và dữ liệu mẫu sẽ giúp mô hình đạt chất lượng cao hơn
- Constraints
- Các ràng buộc sử dụng thêm yêu cầu đối với câu lệnh SQL đầu ra, ví dụ: luôn chọn cột A, sắp xếp giảm dần theo cột B…
- Các tri thức liên quan tới cơ sở dữ liệu, ví dụ: từ viết tắt, giải thích thuật ngữ…
- Few shot samples
- Sử dụng một vài ví dụ cho mô hình nhứng gì bạn muốn nó thực hiện, giúp LLM học hỏi từ ví dụ này.
- Lưu ý khi sử dụng few shot:
- Thêm quá nhiều trường hợp đặc biệt có thể khiến LLM đạt chất lượng kém hơn trong trường hợp tổng quát
- Có thể thêm few shot “động” phù hợp với từng câu hỏi đầu vào để đạt chất lượng tốt hơn.
Fine-tuning
Các mô hình ngôn ngữ lớn ban đầu được huấn luyện trên dữ liệu lớn bao gồm văn bản ở nhiều ngôn ngữ khác nhau. Dữ liệu này có một phần nhỏ là code, mặc dù có khả năng ấn tượng trong việc sinh câu truy vấn trực tiếp từ câu hỏi tự nhiên nhưng vẫn còn nhiều hạn chế. Dựa trên phương pháp fine-tuning LLM chi phí thấp như LORA hay QLORA (số lượng tham số cần fine-tuning nhỏ hơn nhiều so với mô hình gốc), Fan Zhou và đồng nghiệp đã fine-tuning nhiều mô hình ngôn ngữ lớn (LLAMA2, CodeLLAMA, Qwen…) cho bài toán Text2SQL đạt kết quả vượt trội so với mô hình gốc.
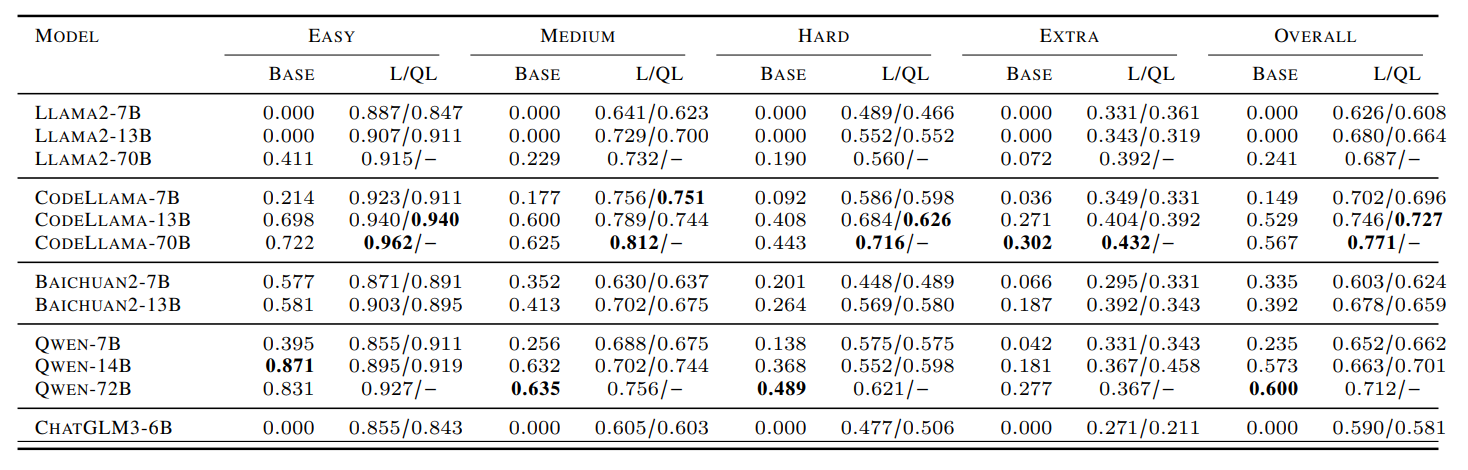
Bảng 1: LORA & QLORA finetuning đánh giá trên bộ dữ liệu Spider.
Trong đầu năm nay, cũng có 2 mô hình nổi trội là CodeS và SQLCoder, không sử dụng Lora hay QLora, thay vào đó, hai mô hình này sử dụng SFT (supervised Fine-tuning) và Reinforcement Learning from Human Feedback (RLHF) để fine-tune. Hai mô hình này đã tạo nên hiệu suất ấn tượng, vượt trội so với cả GPT4 trong việc sinh ra câu SQL (Hình 5). Tới thời điểm hiện tại, các mô hình fine-tune LLM với kích thước nhỏ (chỉ 1B) đã có thể đạt tới độ chính xác 90% cho tác vụ sinh câu SQL và khả thi khi ứng dụng vào truy vấn trong doanh nghiệp.
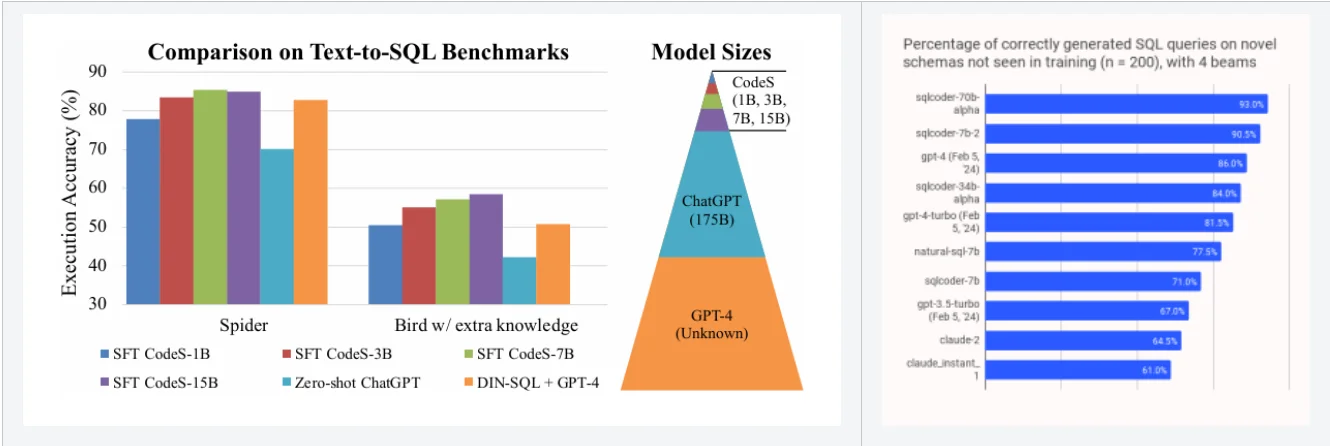
Hình 6: So sánh CodeS và SQLCoder với ChatGPT, GPT4
So sánh hai phương pháp fine-tuning và prompt engineering cho bài toán Text2sql
| Phương pháp | Fine-tuning | Prompt engineering |
| Yêu cầu dữ liệu | Cần lượng lớn dữ liệu chất lượng cao để huấn luyện lại mô hình | Không yêu cầu dữ liệu lớn, chỉ cần tối ưu câu prompt |
| Tài nguyên | Yêu cầu tài nguyên GPU lớn cho quá trình huấn luyện lại mô hình | Tiết kiệm tài nguyên GPU, có thể sử dụng trực tiếp trên các mô hình có sẵn |
| Tính linh hoạt | Phải fine-tune lại với từng mô hình cụ thể, đòi hỏi tinh chỉnh theo từng ứng dụng | Có thể áp dụng cho cả mô hình open-source và close-source (các dịch vụ công khai có trả phí) |
| Độ phức tạp | Quá trình fine-tuning phức tạp, cần thời gian và kỹ thuật chuyên sâu | Prompting có thể phức tạp khi cần tạo prompt chính xác, dễ dẫn đến số lượng token lớn hơn |
| Chất lượng kết quả | Chất lượng cao hơn do mô hình được tùy chỉnh chính xác cho bài toán cụ thể | Chất lượng kém hơn so với fine-tuning, phụ thuộc vào khả năng thiết kế prompt |
| Ứng dụng thực tế | Tối ưu cho các hệ thống yêu cầu độ chính xác cao, ít thay đổi | Phù hợp hơn cho các bài toán triển khai nhanh chóng, không cần huấn luyện lại mô hình |
NL2Vis, tương tự Text2SQL nhưng còn nhiều khó khăn
Mục tiêu của NL2Vis cũng gần tương tự như Text2SQL là chuyển đổi câu hỏi tự nhiên thành một ngôn ngữ lập trình có cấu trúc. NL2Vis sẽ cần đưa câu hỏi tự nhiên sang một ngữ pháp trực quan (visualization grammar hay grammar of graphics) để sử dụng cho các chương trình đồ họa để vẽ biểu đồ.
Hiện tại cộng đồng NLI đã phát triển một số thư viện đồ họa phổ biến được xây dựng dựa trên ngữ pháp trực quan như: Vega-Lite (Vega Team, 2017) hoặc Echarts (2018) được viết trên JavaScripts; ggplot2 (Villanueva và Chen, 2019) trên ngôn ngữ R; VizQL (2006) được phát triển và sử dụng trên phần mềm Tableau. Ngữ pháp này thường có các cấu trúc tường minh và dễ hiểu, giúp người dùng định nghĩa từng thuộc tính của một biểu đồ theo ý muốn thay vì bị giới hạn ở các template biểu đồ có sẵn (Hình 6). Việc sử dụng ngữ pháp trực quan làm ngôn ngữ đầu ra đã giúp NL2Vis tận dụng được các phương pháp của bài toán sinh mã nguồn trong NLP. Điều này đã dẫn đến nhiều kết quả nghiên cứu đột phá gần đây, bao gồm: sinh được nhiều loại biểu đồ ít thông dụng, hỗ trợ sinh các biểu đồ phức tạp, đưa ra suy luận đúng từ các yêu cầu không đầy đủ, cho phép người dùng cập nhật và chỉnh sửa biểu đồ bằng yêu cầu,.. (Shen L., 2021).

Hình 7: Ví dụ về cấu trúc ngữ pháp của Vega-Lite.

Hình 8: Một vài mẫu của cặp câu hỏi – biểu đồ trong tập nvBench.
Giống với Text2SQL, NL2Vis cũng được nghiên cứu phát triển từ hướng tiếp cận truyền thống là chia thành các tác vụ nhỏ và ánh xạ các thành phần câu trả lời từ câu hỏi tự nhiên. Ở giai đoạn đầu, việc ánh xạ chủ yếu dựa trên quy tắc (rule-based) (Cox et al., 2001; Kato et al., 2002), phương pháp đã cho kết quả tiềm năng khi ứng dụng cho một số biểu đồ cơ bản như cột, đường, tròn.
Sau đó một số phương pháp phân tích cú pháp phổ biến trong NLP như NLTK, Stanford Parser đã được đưa vào nhằm hỗ trợ trả lời những câu hỏi phức tạp, DataTone (Gao et a., 2015) đã sử dụng kết quả phân tích cú pháp để đề xuất giả thuyết với các câu hỏi thiếu cụ thể và đã tăng độ chính xác khi sử dụng lên tới 5 lần; Arklang (2019) cũng được Tableau công bố giúp chuyển các câu “ra lệnh” tự nhiên sang dạng truy vấn có cấu trúc. Ở giai đoạn này, do chưa có bộ dữ liệu benchmark nên các nghiên cứu vẫn sử dụng kết quả khảo sát người dùng để đánh giá.
Khi các thư viện ngữ pháp trực quan được hoàn thiện và ra mắt cộng đồng, các bộ dữ liệu benchmark cho NL2Vis mới được xây dựng và công bố. Hiện tại có 2 bộ benchmark lớn và được sử dụng phổ biến:
-
- nvBench (2021): sử dụng bộ câu hỏi và dữ liệu của Spider, với 25.750 cặp câu hỏi – biểu đồ được tổng hợp tự động, có 9.897 thông số, sử dụng Vega-Lite và ECharts
- VisText (2023): 12,441 biểu đồ thực tế cùng với mô tả cụ thể được con người tạo ra với độ phức tạp cao, gồm 709 thông số và sử dụng Vega-Lite
Mô hình Seq2Vis (2021) được giới thiệu cùng nvBench đã cho thấy tiềm năng ứng dụng các mô hình Seq2Seq vào NL2Vis. Các phương pháp Seq2Seq khác cũng đã được nghiên cứu trên tập nvBench và cho kết quả cải thiện đáng chú ý như ncNet (2021) và RGVisNet (2022) với độ chính xác lần lượt là 26% và 45%.
Tiềm năng khi ứng dụng LLM vào NL2Vis
Tương tự với Text2SQL, có 2 cách tối ưu kết quả khi ứng dụng LLM vào NL2Vis là fine-tune mô hình hoặc chỉnh sửa prompt.
Prompt Engineering
Cấu trúc prompt của NL2Vis không có nhiều khác biệt so với Text2SQL, khác biệt lớn nhất nằm ở phần DDL và đặc tả ngôn ngữ đầu ra:
- Instruction task hay system prompt
- Câu hỏi tự nhiên
- Database schema (Data Definition Language-DDL)
- Ngoài schema, sẽ cần đưa vào toàn bộ dữ liệu hoặc mô tả tổng hợp dữ liệu cần hiển thị để mô hình lựa chọn loại biểu đồ phù hợp
- Constraints
- Few shot samples: cung cấp sample là bắt buộc khi sử dụng các mô hình LLM tổng quát do các ngữ pháp trực quan không phổ biến và có khả năng chưa được cập nhật bởi LLM
- template của ngữ pháp đầu ra dưới dạng json
- 1 đoạn mã nguồn sinh biểu đồ

Hình 9: Ví dụ về prompt được sử dụng trong framework Chat2Vis.
Fine-tuning
Hiện tại mới có Yang W. và đồng nghiệp (2024) thử nghiệm fine-tune mô hình ngôn ngữ T5 ( 60 và 220 triệu tham số) trên tập dữ liệu benchmark nvBench. Kết quả fine-tune này đã cho cải thiện rõ rệt so với các mô hình Seq2Seq và còn vượt qua được gpt-4 trong một số hạng mục (Bảng 2). Kết quả này cho thấy tiềm năng của việc fine-tune mô hình ngôn ngữ lớn cho NL2Vis.
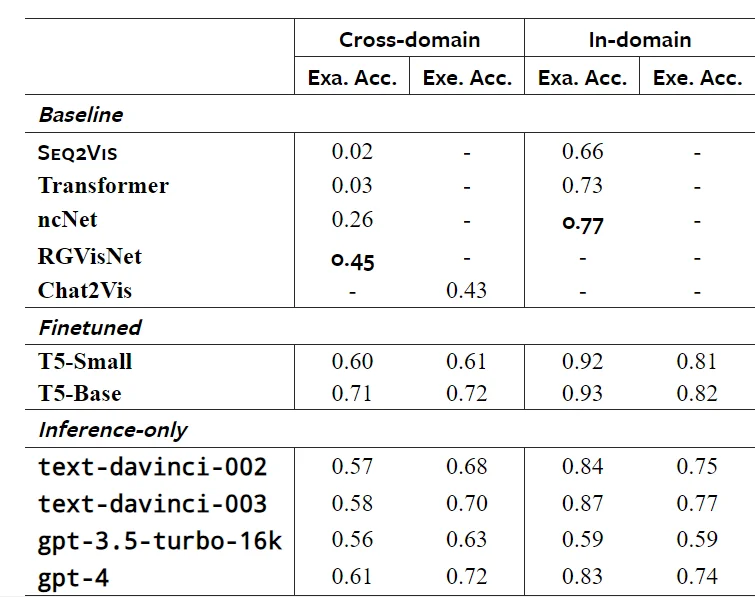
Bảng 2: So sánh kết quả của 3 phương pháp: Seq2Seq, fine-tune LLM với prompt engineer LLM với prompt. Thử nghiệm trên bộ benchmark nvBench.
Hướng nghiên cứu tiếp theo cho Text2Vis
Các nghiên cứu hiện tại đã cho thấy tiềm năng lớn trong ứng dụng LLM vào NL2Vis, tuy nhiên độ chính xác của kết quả vẫn còn nhiều phần cần cải thiện.
Hiện tại các tập benchmark đang được xây dựng trên ngữ pháp Vega-Lite, tuy nhiên Vega-Lite chưa được sử dụng rộng rãi trong các công cụ trực quan phổ biến. Điều này cũng hạn chế việc ứng dụng trực tiếp các kết quả nghiên cứu hiện tại vào doanh nghiệp. VizQL của Tableau là một lựa chọn thay thế tốt, tuy nhiên cho tới giờ vẫn chưa có bộ dữ liệu benchmark nào cho VizQL được công bố. Bởi vậy, việc thống nhất một ngữ pháp chủ đạo trong cộng đồng và xây dựng benchmark là cần thiết.
Hiện tượng hallucination vẫn thường hay gặp, đặc biệt là trong các yêu cầu có tính nhập nhằng, khả năng suy luận và đưa ra các gợi ý phù hợp của LLM vẫn còn nhiều hạn chế. Dù có khả năng trích chọn dữ liệu biểu diễn rất tốt, LLM vẫn gặp nhiều khó khăn khi sinh các tác vụ trực quan cụ thể như: sắp xếp, đánh dấu các điểm bất thường, so sánh,… (Hannah K., 2024). Việc tích hợp kỹ thuật RAG và những agent hỗ trợ khác là cần thiết để giúp kết quả này dễ tiếp cận tới người dùng hơn.
Những yếu tố trên có thể là các hướng nghiên cứu tiềm năng về ứng dụng LLM cho NL2Vis trong tương lai.
Các khó khăn và hướng ứng dụng LLM cho v-NLI
Một số ứng dụng LLM vào v-NLI hiện có
Hiện tại đã có nhiều nền tảng thương mại hỗ trợ v-NLI vào các LLM Agent, OpenAI hay Poe cũng đã tích hợp tính năng thực thi đoạn html để sinh ra biểu đồ hiển thị trong hội thoại. Giúp người dùng dễ dàng tạo ra các biểu đồ đơn giản phục vụ cho nhu cầu hàng ngày từ dữ liệu. Để tăng độ chính xác, phục vụ cho các tác vụ phức tạp hơn, Kanaries Data, Inc. đã kết hợp hệ thống tự động giải thích, đề xuất chỉnh sửa prompt cho người dùng.
Các thư viện sử dụng LLM cho v-NLI hiện tại đều cần thêm các agent để xử lý và tinh chỉnh các câu trả lời từ mô hình, đặc biệt với các tác vụ trực quan phức tạp. LIDA của Microsoft (Victor D. 2023) hiện tại đang là thư viện mã nguồn mở thông dụng và được quan tâm. Framework của LIDA gồm nhiều LLM agent cho từng tác vụ theo hướng tiếp cận truyền thống. LIDA không bị giới hạn về ngôn ngữ và cho phép người dùng sử dụng prompt engineering để điều chỉnh. LIDA hỗ trợ sử dụng nhiều thư viện trực quan khác nhau và còn cho phép người dùng đưa ra yêu cầu về phong cách biểu diễn đồ thị, đồng thời cách chia lớp này cũng giúp việc giải thích kết quả dễ dàng hơn với người dùng.
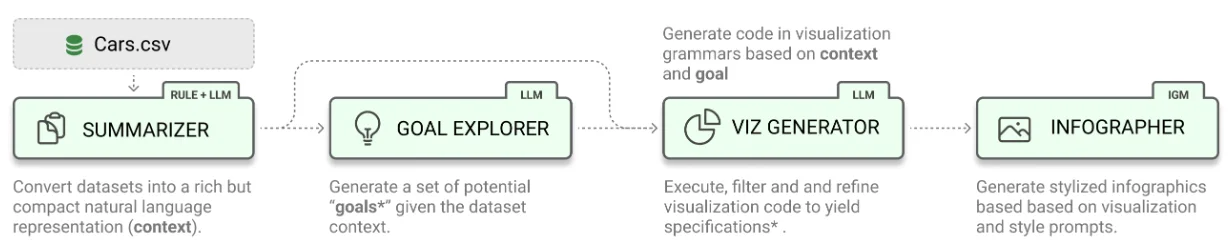
Hình 10: Kiến trúc của LIDA gồm 4 LLM agents: tổng hợp thông tin, tổng hợp các task, sinh mã nguồn và điều chỉnh các hàm để vẽ phù hợp với các yêu cầu hiển thị.
Để phục vụ cho những biểu đồ phức tạp thường dùng trong nghiên cứu, MatplotAgent (Yang Z. 2024) đã sử dụng hệ thống tự feedback từ hình ảnh được vẽ thay vì kiểm tra mã nguồn. Cách tiếp cận này đã giúp hạn chế mức phụ thuộc vào loại ngôn ngữ đầu ra (Hình 10). Yang Z. và đồng nghiệp cũng đã giới thiệu bộ dữ liệu matplotBench gồm 100 ảnh đồ thị vô cùng phức tạp (Hình 11) và đánh giá độ chính xác bằng cách so sánh ảnh đồ thị được sinh với ảnh ground-truth. Hướng ứng dụng này có thể là cách tiếp cận mới và tiềm năng, giải quyết được các vấn đề về thống nhất ngôn ngữ đầu ra.
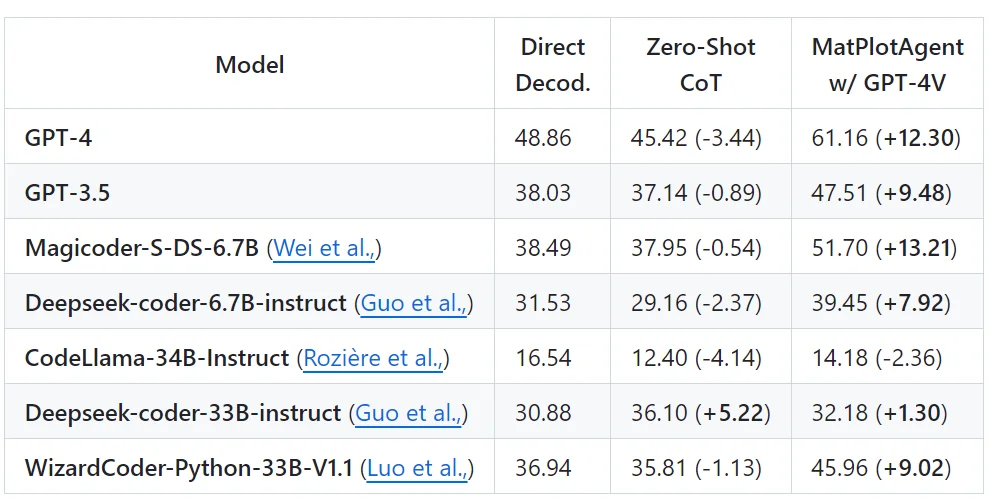
Hình 11: Kết quả của MatplotAgent trên tập MatplotBench khi so sánh với luồng thông thường không có tự feedback
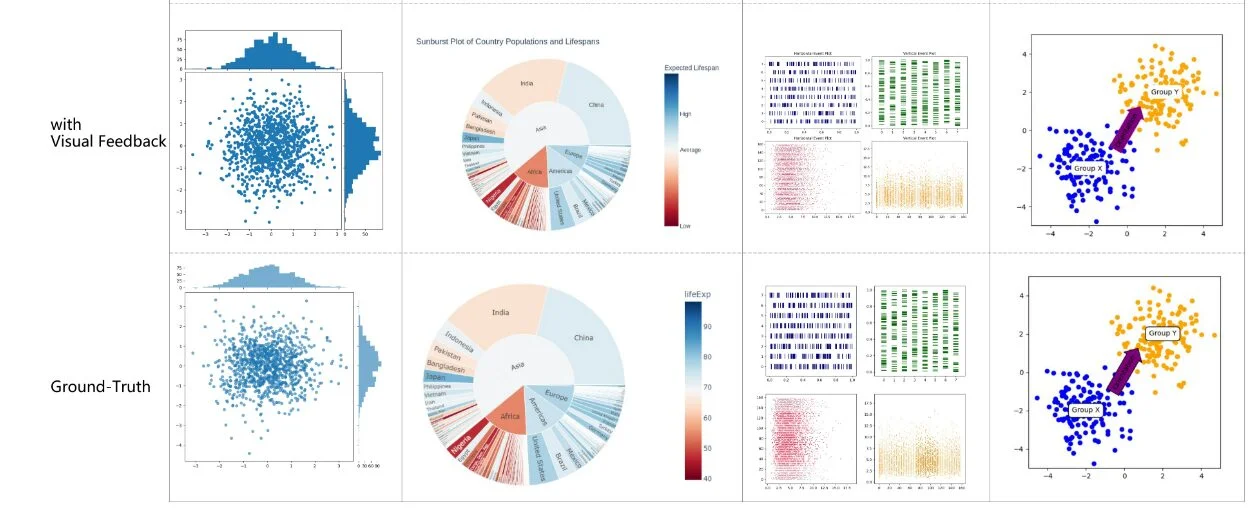
Hình 12: Một số biểu đồ phức tạp được sinh bởi MatplotAgent so với ground-truth từ tập matplotBench
Tùy thuộc vào nhu cầu về độ chính xác và tính bảo mật của dữ liệu, có thể các doanh nghiệp sẽ cần phát triển riêng bộ dữ liệu huấn luyện để fine-tune một mô hình riêng để có thể ứng dụng LLM.
Khó khăn trong việc xây dựng ứng dụng v-NLI
1. Về dữ liệu huấn luyện: Các mô hình LLM thường được huấn luyện trên cơ sở dữ liệu và câu truy vấn đơn giản, đã được chuẩn hóa. Tuy nhiên, khi chuyển sang ứng dụng thực tế, dữ liệu thường phức tạp hơn rất nhiều. Các cơ sở dữ liệu thực tế có thể chứa các trường không mang ý nghĩa hoặc đã được mã hóa, dẫn đến việc mô hình khó khăn trong việc tạo ra các truy vấn chính xác.
2. Độ phức tạp của câu hỏi: Người dùng thường đưa ra các câu hỏi không rõ ràng, nhập nhằng hoặc đa nghĩa, điều này làm tăng độ phức tạp cho việc chuyển đổi câu hỏi thành mã nguồn. Ngoài ra, do người dùng không biết cách dữ liệu được lưu trữ trong cơ sở dữ liệu, họ có thể đặt câu hỏi theo cách không tương thích với cấu trúc dữ liệu, dẫn đến khó khăn trong việc tạo ra truy vấn chính xác.
3. Dữ liệu thực tế: Trong môi trường thực tế, dữ liệu trong các cơ sở dữ liệu thường không được chuẩn hóa hoàn toàn. Ví dụ, tên trường có thể không mang ý nghĩa rõ ràng hoặc đã bị mã hóa, gây khó khăn cho mô hình LLM trong việc nhận diện và xử lý dữ liệu để tạo ra các truy vấn phù hợp.
4. Hạn chế của LLM: Mặc dù các mô hình LLM đã đạt được độ chính xác cao, chúng vẫn gặp phải hạn chế về tính giải thích của kết quả. Hiện tượng ảo giác (hallucination) – khi mô hình tạo ra thông tin không có thật – là một vấn đề lớn, làm cho việc kiểm soát đầu ra của LLM trở nên khó khăn. Điều này hạn chế khả năng áp dụng rộng rãi của các mô hình này trong các hệ thống yêu cầu độ tin cậy cao, như trong các ứng dụng liên quan đến truy vấn cơ sở dữ liệu.
Kết luận
Các bài toán Text2SQL và NL2Vis đã đạt được những thành tựu đáng kể nhờ vào sự tiến bộ của các mô hình ngôn ngữ lớn (LLM). Với độ chính xác ngày càng cao, đây là một tín hiệu tích cực cho các doanh nghiệp trong việc phát triển và ứng dụng hệ thống. Khi kết hợp với kỹ thuật Retrieval-Augmented Generation (RAG), những hệ thống này có tiềm năng mở rộng thành nhiều ứng dụng như hỏi đáp tự động, tra cứu thông tin, và sinh báo cáo một cách liền mạch, giúp người dùng không cần phải học cách thao tác với hệ thống phức tạp.
Tuy nhiên, trong thực tế, vẫn còn một số thách thức cần vượt qua. Mặc dù Text2SQL đã đạt độ chính xác ấn tượng lên tới 90%, việc triển khai trong các môi trường thực tế vẫn đòi hỏi nhiều sự tinh chỉnh để đảm bảo câu trả lời có độ chính xác cao nhất. Đối với NL2Vis, mặc dù có nhiều tiềm năng, vẫn cần thêm nghiên cứu để phát triển các bộ benchmark tối ưu và ngôn ngữ trực quan hoá dữ liệu. Việc giải quyết các vấn đề này sẽ là chìa khóa để tận dụng tối đa khả năng của các hệ thống NLI trong tương lai. Hãy cùng theo dõi các bài viết tiếp theo để khám phá chi tiết hơn về ứng dụng thực tế cũng như những thách thức hiện tại, và cách giải quyết chúng.