Tutorial: Dịch máy sử dụng mô hình Seq2seq
Giới thiệu về dịch máy
Dịch máy là bài toán nhằm mục đích dịch từ một ngôn ngữ này sang một ngôn ngữ khác một cách tự động. Các phương pháp phổ biến gồm có dịch máy dựa trên thống kê và dịch máy dựa trên mạng neural. Dưới đây chúng tôi xin giới thiệu về dịch máy mạng neural, một trong những phương pháp phổ biến và hiệu quả nhất hiện nay
Dịch máy mạng neural là phương pháp sử dụng Deep Learning để tạo bản dịch cho văn bản từ ngôn ngữ này sang ngôn ngữ khác. Ngày nay, chúng ta có các phần mềm dịch có khả năng dịch gần như tức thời và tương đối chính xác toàn bộ trang web được viết bằng các ngôn ngữ khác.
Trong bài đăng trên blog này, chúng tôi sẽ chia nhỏ lý thuyết và thiết kế của mô hình Seq2Seq [1]. Sau đó, chúng ta sẽ xem qua phiên bản nâng cao của Seq2Seq với cơ chế attention [2], [3]. Dưới đây là một số thuật ngữ tiếng anh có sử dụng trong bài.
Các thuật ngữ tiếng Anh liên quan.
- Deep learning: Học sâu
- NMT (Neural machine translation): dịch máy mạng neural
- Seq2seq: Sequence to Sequence
- RNN (Recurrent Neural Network): Mạng neural hồi quy
- LSTM (Long short temp memory)
Cách thức hoạt động của Seq2Seq
Mô hình Seq2Seq hoạt động tương đối đơn giản. Mục tiêu của loại mô hình này là ánh xạ đầu vào chuỗi có độ dài cố định thành đầu ra chuỗi được ghép nối có độ dài cố định, trong đó độ dài câu đầu vào và đầu ra có thể khác nhau.
Nếu một chuỗi trong ngôn ngữ đầu vào có 8 từ và cùng một câu trong ngôn ngữ đích có 4 từ, thì một dịch giả chất lượng cao nên suy luận điều đó và rút ngắn độ dài câu của đầu ra
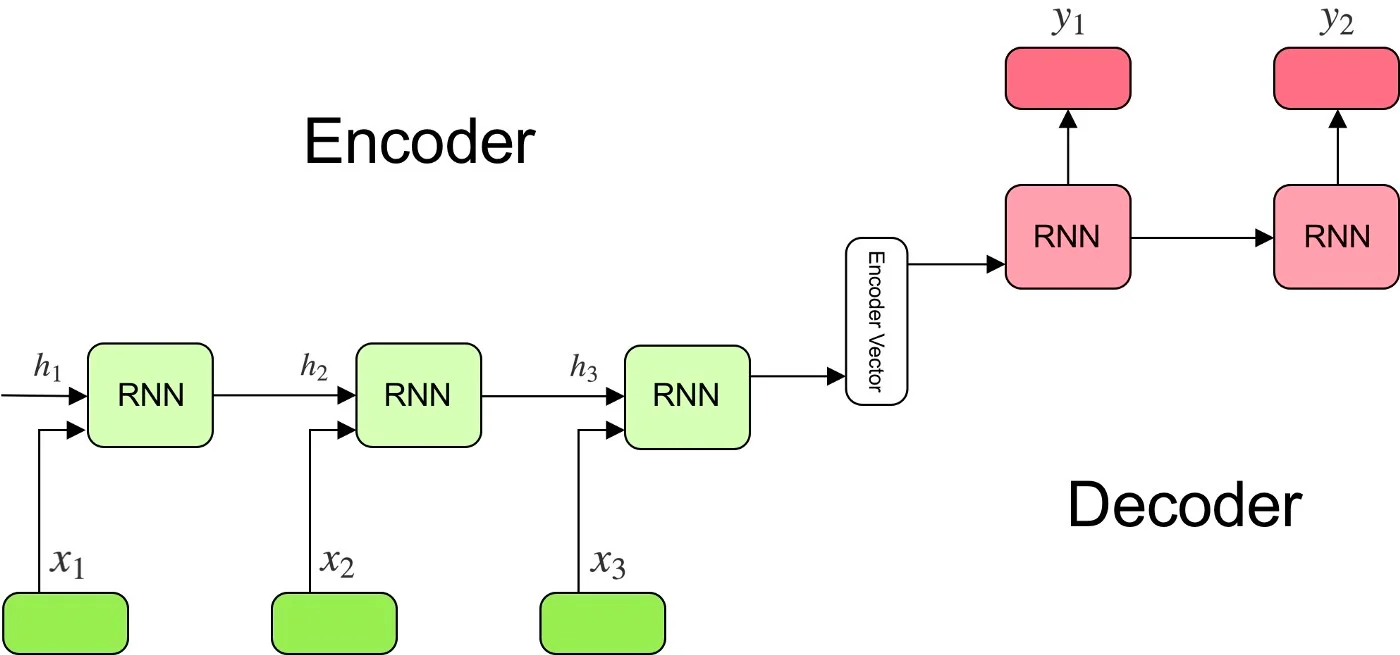
Mô hình Seq2Seq thường chia sẻ một khuôn khổ chung. Ba thành phần chính của bất kỳ mô hình Seq2Seq nào là mạng bộ mã hóa(encoder) và bộ giải mã(decoder) và mã hóa vectơ trung gian giữa chúng. Các mạng này thường là mạng neural hồi quy (RNN), nhưng thường thì chúng được tạo thành với GRU và Bộ nhớ ngắn hạn dài (LSTM) chuyên biệt hơn.
Mạng bộ mã hóa là một loạt các đơn vị RNN. Nó sử dụng những đơn vị RNN để mã hóa tuần tự các phần tử từ đầu vào cho vectơ mã hóa, với trạng thái ẩn cuối cùng được ghi vào vectơ trung gian.
Nhiều mô hình NMT tận dụng cơ chế attention để cải thiện mã hóa ngữ cảnh giữa từ dự đoán và câu input đầu vào. Sự attention là cách buộc bộ giải mã tập trung vào một số phần nhất định trong đầu ra của bộ mã hóa thông qua một tập hợp các trọng số. Các trọng số attention này được nhân với các vectơ đầu ra của bộ mã hóa. Điều này tạo ra một mã hóa vectơ kết hợp sẽ tăng cường khả năng của bộ giải mã để hiểu ngữ cảnh của các kết quả đầu ra mà nó đang tạo ra và do đó cải thiện dự đoán của nó. Việc tính toán các trọng số attention này được thực hiện thông qua lớp attention chuyển tiếp nguồn cấp dữ liệu, lớp này sử dụng đầu vào của bộ giải mã và trạng thái ẩn làm đầu vào.
Vectơ bộ mã hóa chứa các biểu diễn số của đầu vào từ bộ mã hóa. Nếu mọi thứ diễn ra chính xác, nó sẽ ghi lại tất cả thông tin từ câu đầu vào ban đầu. Vectơ mã hóa này sau đó đóng vai trò là trạng thái ẩn ban đầu cho mạng bộ giải mã.
Mạng bộ giải mã về cơ bản là nghịch đảo của bộ mã hóa. Nó lấy vectơ trung gian được mã hóa làm trạng thái ẩn và tuần tự tạo bản dịch. Mỗi phần tử trong đầu ra thông báo dự đoán của bộ giải mã về phần tử tiếp theo.
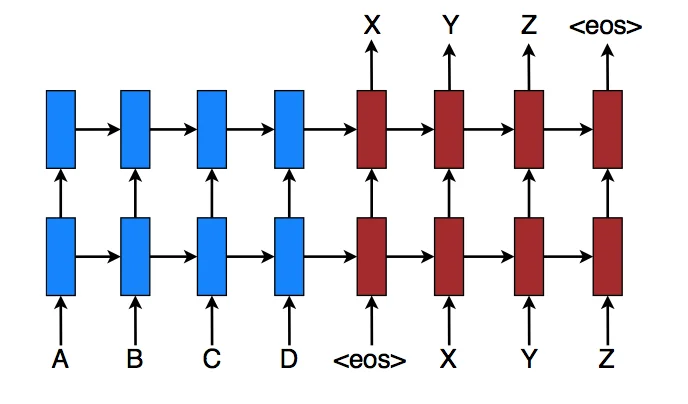
Trong thực tế, một NMT sẽ lấy một chuỗi đầu vào của một ngôn ngữ và tạo ra một chuỗi các nhúng đại diện cho từng thành phần, từ trong câu. Các đơn vị RNN trong bộ mã hóa lấy cả trạng thái ẩn trước đó và một phần tử duy nhất của đầu vào ban đầu được nhúng làm đầu vào và mỗi bước có thể cải thiện tuần tự bước trước đó bằng cách truy cập trạng thái ẩn của bước trước đó để thông báo cho phần tử được dự đoán. Điều quan trọng cũng cần đề cập là ngoài việc mã hóa câu, phần cuối của biểu diễn thẻ câu được bao gồm như một phần tử trong chuỗi. Việc gắn thẻ cuối câu này giúp người dịch biết những từ nào trong ngôn ngữ dịch sẽ kích hoạt bộ giải mã ngừng giải mã và xuất ra câu đã dịch.
Các nhúng trạng thái ẩn cuối cùng được mã hóa trong vectơ bộ mã hóa trung gian. Các mã hóa nắm bắt càng nhiều thông tin càng tốt về câu đầu vào để tạo điều kiện thuận lợi cho bộ giải mã giải mã chúng thành bản dịch. Nó có thể làm điều này nhờ được sử dụng làm trạng thái ẩn ban đầu cho mạng bộ giải mã.
Sử dụng thông tin từ vectơ bộ mã hóa, mỗi đơn vị lặp lại trong bộ giải mã chấp nhận trạng thái ẩn từ đơn vị trước đó và tạo ra đầu ra cũng như trạng thái ẩn của chính nó. Bộ giải mã được trạng thái ẩn thông báo để đưa ra dự đoán về một chuỗi và với mỗi dự đoán tuần tự, nó dự đoán phiên bản tiếp theo của chuỗi bằng cách sử dụng thông tin từ trạng thái ẩn trước đó. Do đó, đầu ra cuối cùng là kết quả cuối cùng của các dự đoán từng bước của từng thành phần trong câu được dịch. Độ dài của câu này không liên quan đến độ dài của câu đầu vào nhờ vào thẻ cuối câu <EOS>, thẻ này cho bộ giải mã biết khi nào nên ngừng thêm thuật ngữ vào câu.
Trong phần tiếp theo, chúng tôi sẽ chỉ ra cách bạn có thể triển khai từng bước bằng cách sử dụng hàm riêng biệt và PyTorch.
Thực nghiệm với Pytorch
1. Chuẩn bị dữ liệu
Thu thập và chuẩn bị Bộ dữ liệu Tiếng Anh – Tiếng Pháp WMT2014 Europarl v7
Bộ dữ liệu tiếng Anh – tiếng Pháp WMT2014 Europarl v7 là tập hợp các bài phát biểu được thực hiện trong Nghị viện Châu Âu và được dịch sang một số ngôn ngữ khác nhau. Bạn có thể truy cập miễn phí tại https://www.statmt.org/europarl/
Để lấy tập dữ liệu lên Gradient, chỉ cần vào terminal và chạy
wget https://www.statmt.org/europarl/v7/fr-en.tgz
tar -xf fre-en.tgzBạn cũng sẽ muốn tải xuống tập dữ liệu hướng dẫn do Torch cung cấp.
wget https://download.pytorch.org/tutorial/data.zip
unzip data.zip2. Xử lí dữ liệu
# load doc into memory
def load_doc(filename):
# open the file as read only
file = open(filename, mode='rt', encoding='utf-8')
# read all text
text = file.read()
# close the file
file.close()
return text
# split a loaded document into sentences
def to_sentences(doc):
return doc.strip().split('\n')
# clean a list of lines
def clean_lines(lines):
cleaned = list()
# prepare regex for char filtering
re_print = re.compile('[^%s]' % re.escape(string.printable))
# prepare translation table for removing punctuation
table = str.maketrans('', '', string.punctuation)
for line in lines:
# normalize unicode characters
line = normalize('NFD', line).encode('ascii', 'ignore')
line = line.decode('UTF-8')
# tokenize on white space
line = line.split()
# convert to lower case
line = [word.lower() for word in line]
# remove punctuation from each token
line = [word.translate(table) for word in line]
# remove non-printable chars form each token
line = [re_print.sub('', w) for w in line]
# remove tokens with numbers in them
line = [word for word in line if word.isalpha()]
# store as string
cleaned.append(' '.join(line))
return cleaned
# save a list of clean sentences to file
def save_clean_sentences(sentences, filename):
dump(sentences, open(filename, 'wb'))
print('Saved: %s' % filename)
# load English data
filename = 'europarl-v7.fr-en.en'
doc = load_doc(filename)
sentences = to_sentences(doc)
sentences = clean_lines(sentences)
save_clean_sentences(sentences, 'english.pkl')
# spot check
for i in range(10):
print(sentences[i])
# load French data
filename = 'europarl-v7.fr-en.fr'
doc = load_doc(filename)
sentences = to_sentences(doc)
sentences = clean_lines(sentences)
save_clean_sentences(sentences, 'french.pkl')
# spot check
for i in range(1):
print(sentences[i])Thao tác này sẽ lấy bộ dữ liệu WMT2014 và xóa sạch mọi dấu câu, chữ hoa, ký tự không in được và mã thông báo có số trong đó. Sau đó, nó chọn các tập tin để sử dụng sau này.
with open('french.pkl', 'rb') as f:
fr_voc = pickle.load(f)
with open('english.pkl', 'rb') as f:
eng_voc = pickle.load(f)
data = pd.DataFrame(zip(eng_voc, fr_voc), columns = ['English', 'French'])
dataCó thể sử dụng pickle.load()để tải các tệp hiện đã lưu và sau đó có thể sử dụng dataframe của Pandas thuận tiện để kết hợp hai tệp.
3. Kết hợp hai bộ dữ liệu
Tạo tập dữ liệu đầy đủ hơn
data2 = pd.read_csv('eng-fra.txt', '\t', names = ['English', 'French'])Chúng ta cần tải lên tập dữ liệu gốc từ hướng dẫn PyTorch và có thể nối chúng và lưu chúng trở lại ở định dạng ban đầu được sử dụng bởi tập dữ liệu mẫu từ PyTorch.
data = pd.concat([data,data2], ignore_index= True, axis = 0)
data.to_csv('eng-fra.txt')Bây giờ, tập dữ liệu có thể được áp dụng cho đoạn code hướng dẫn PyTorch. Nhưng trước tiên, hãy xem các bước cần thiết để chuẩn bị tập dữ liệu và xem chúng ta có thể thực hiện những cải tiến nào.
from __future__ import unicode_literals, print_function, division
from io import open
import unicodedata
import string
import re
import random
import torch
import torch.nn as nn
from torch import optim
import torch.nn.functional as F
import torchtext
from torchtext.data import get_tokenizer
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")Hàm trợ giúp chuẩn bị tập dữ liệu
SOS_token = 0
EOS_token = 1
class Lang:
def __init__(self, name):
self.name = name
self.word2index = {}
self.word2count = {}
self.index2word = {0: "SOS", 1: "EOS"}
self.n_words = 2 # Count SOS and EOS
def addSentence(self, sentence):
for word in sentence.split(' '):
self.addWord(word)
def addWord(self, word):
if word not in self.word2index:
self.word2index[word] = self.n_words
self.word2count[word] = 1
self.index2word[self.n_words] = word
self.n_words += 1
else:
self.word2count[word] += 1Để xử lý tập dữ liệu cho mô hình, chúng tôi có thể sử dụng lớp Lang này để cung cấp chức năng hữu ích như word2index, index2word và word2count. Ô tiếp theo cũng sẽ chứa các chức năng hữu ích để làm sạch tập dữ liệu gốc.
def readLangs(lang1, lang2, reverse=False):
print("Reading lines...")
# Read the file and split into lines
lines = open('%s-%s2.txt' % (lang1, lang2), encoding='utf-8').\
read().strip().split('\n')
# Split every line into pairs and normalize
pairs = [[normalizeString(s) for s in l.split('\t')] for l in lines]
# Reverse pairs, make Lang instances
if reverse:
pairs = [list(reversed(p)) for p in pairs]
input_lang = Lang(lang2)
output_lang = Lang(lang1)
else:
input_lang = Lang(lang1)
output_lang = Lang(lang2)
return input_lang, output_lang, pairsTiếp theo, hàm readLangs nhận csv của chúng ta để tạo input_lang, output_lang và ghép các biến mà chúng ta sẽ sử dụng để chuẩn bị tập dữ liệu của mình. Hàm này sử dụng các hàm trợ giúp để làm sạch văn bản và chuẩn hóa các chuỗi.
MAX_LENGTH = 12
eng_prefixes = [
"i am ", "i m ",
"he is", "he s ",
"she is", "she s ",
"you are", "you re ",
"we are", "we re ",
"they are", "they re ", "I don t", "Do you", "I want", "Are you", "I have", "I think",
"I can t", "I was", "He is", "I m not", "This is", "I just", "I didn t",
"I am", "I thought", "I know", "Tom is", "I had", "Did you", "Have you",
"Can you", "He was", "You don t", "I d like", "It was", "You should",
"Would you", "I like", "It is", "She is", "You can t", "He has",
"What do", "If you", "I need", "No one", "You are", "You have",
"I feel", "I really", "Why don t", "I hope", "I will", "We have",
"You re not", "You re very", "She was", "I love", "You must", "I can"]
eng_prefixes = (map(lambda x: x.lower(), eng_prefixes))
eng_prefixes = set(eng_prefixes)
def filterPair(p):
return len(p[0].split(' ')) < MAX_LENGTH and \
len(p[1].split(' ')) < MAX_LENGTH and \
p[1].startswith(eng_prefixes)
def filterPairs(pairs):
return [pair for pair in pairs if filterPair(pair)]
eng_prefixesTrong một thay đổi khác so với hướng dẫn Torch, tôi đã mở rộng danh sách các tiền tố tiếng Anh để bao gồm các tiền tố bắt đầu phổ biến nhất cho tập dữ liệu hiện được kết hợp. Tôi cũng đã mở rộng max_length đến 12 trong nỗ lực tạo ra một tập hợp các điểm dữ liệu mạnh mẽ hơn, nhưng điều này có thể gây ra nhiều yếu tố gây nhiễu cũng như các yếu tố hữu ích. Hãy thử giảm max_length xuống 10 và xem hiệu suất thay đổi như thế nào.
def prepareData(lang1, lang2,reverse = False):
input_lang, output_lang, pairs = readLangs(lang1, lang2, reverse)
print("Read %s sentence pairs" % len(pairs))
pairs = filterPairs(pairs)
print("Trimmed to %s sentence pairs" % len(pairs))
print("Counting words...")
for pair in pairs:
input_lang.addSentence(pair[0])
output_lang.addSentence(pair[1])
print("Counted words:")
print(input_lang.name, input_lang.n_words)
print(output_lang.name, output_lang.n_words)
return input_lang, output_lang, pairs
input_lang, output_lang, pairs = prepareData('eng', 'fra', True)
print(random.choice(pairs))Cuối cùng, hàm chuẩn bị dữ liệu đặt tất cả các hàm trợ giúp lại với nhau để lọc và hoàn thiện các cặp ngôn ngữ cho đào tạo NMT. Bây giờ tập dữ liệu của chúng ta đã sẵn sàng hoạt động, hãy bắt đầu viết code cho mô hình
Encoder
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size):
super(EncoderRNN, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
def forward(self, input, hidden):
embedded = self.embedding(input).view(1, 1, -1)
output = embedded
output, hidden = self.gru(output, hidden)
return output, hidden
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)Bộ mã hóa mà chúng tôi đang sử dụng về cơ bản giống như hướng dẫn và có lẽ là đoạn mã đơn giản nhất. Chúng ta có thể thấy từ chức năng chuyển tiếp, đối với mỗi phần tử đầu vào, bộ mã hóa xuất ra cả vectơ đầu ra và trạng thái ẩn. Trạng thái ẩn đó sau đó được trả về, vì vậy nó có thể được sử dụng trong bước tiếp theo, cùng với đầu ra
Attention Decoder
class AttnDecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size, dropout_p=0.1, max_length=MAX_LENGTH):
super(AttnDecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.dropout_p = dropout_p
self.max_length = max_length
self.embedding = nn.Embedding(self.output_size, self.hidden_size)
self.attn = nn.Linear(self.hidden_size * 2, self.max_length)
self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)
self.dropout = nn.Dropout(self.dropout_p)
self.gru = nn.GRU(self.hidden_size, self.hidden_size)
self.out = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input, hidden, encoder_outputs):
embedded = self.embedding(input).view(1, 1, -1)
embedded = self.dropout(embedded)
attn_weights = F.softmax(
self.attn(torch.cat((embedded[0], hidden[0]), 1)), dim=1)
attn_applied = torch.bmm(attn_weights.unsqueeze(0),
encoder_outputs.unsqueeze(0))
output = torch.cat((embedded[0], attn_applied[0]), 1)
output = self.attn_combine(output).unsqueeze(0)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = F.log_softmax(self.out(output[0]), dim=1)
return output, hidden, attn_weights
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)Vì chúng tôi đang sử dụng attention trong ví dụ, có một số khác biệt chính ở đây giữa các mạng bộ mã hóa và bộ giải mã.
Đầu tiên, có thêm 2 tham số cho hàm init(): max_length và dropout_p. max_length là số phần tử tối đa mà một câu có thể chứa để được xem xét. dropout_p được sử dụng để tránh sự overfit.
Thứ hai, chúng ta có attention. Ở mỗi bước, tầng attention nhận đầu vào attention, trạng thái bộ giải mã và tất cả trạng thái bộ mã hóa. Nó sử dụng điều này để tính điểm attention. Đối với mỗi trạng thái bộ mã hóa, sự attention sẽ tính toán “mức độ phù hợp” của nó đối với trạng thái bộ giải mã này. Nó áp dụng một chức năng attention nhận một trạng thái bộ giải mã và một trạng thái bộ mã hóa và trả về một giá trị vô hướng. Điểm attention được sử dụng để tính trọng số attention. Các trọng số này là một phân phối xác suất được tạo ra bằng cách áp dụng softmax cho điểm attention. Cuối cùng, nó tính toán đầu ra attention dưới dạng tổng trọng số của các trạng thái bộ mã hóa với trọng số attention.
Các tham số bổ sung và cơ chế attention này cho phép bộ giải mã yêu cầu ít thông tin tổng thể và đào tạo hơn nhiều để phát triển sự hiểu biết về mối quan hệ của tất cả các từ trong chuỗi
4. Huấn luyện mô hình
teacher_forcing_ratio = 0.5
def train(input_tensor, target_tensor, encoder, decoder, encoder_optimizer, decoder_optimizer, criterion, max_length=MAX_LENGTH):
encoder_hidden = encoder.initHidden()
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
input_length = input_tensor.size(0)
target_length = target_tensor.size(0)
encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device=device)
loss = 0
for ei in range(input_length):
encoder_output, encoder_hidden = encoder(
input_tensor[ei], encoder_hidden)
encoder_outputs[ei] = encoder_output[0, 0]
decoder_input = torch.tensor([[SOS_token]], device=device)
decoder_hidden = encoder_hidden
use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False
if use_teacher_forcing:
# Teacher forcing: Feed the target as the next input
for di in range(target_length):
decoder_output, decoder_hidden, decoder_attention = decoder(
decoder_input, decoder_hidden, encoder_outputs)
loss += criterion(decoder_output, target_tensor[di])
decoder_input = target_tensor[di] # Teacher forcing
else:
# Without teacher forcing: use its own predictions as the next input
for di in range(target_length):
decoder_output, decoder_hidden, decoder_attention = decoder(
decoder_input, decoder_hidden, encoder_outputs)
topv, topi = decoder_output.topk(1)
decoder_input = topi.squeeze().detach() # detach from history as input
loss += criterion(decoder_output, target_tensor[di])
if decoder_input.item() == EOS_token:
break
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
return loss.item() / target_lengthHàm đào tạo mà chúng tôi đang sử dụng có một số tham số. input_tensor và target_tensor lần lượt là chỉ số thứ 0 và thứ 1 của cặp câu. Bộ mã hóa là bộ mã hóa được mô tả ở trên. Bộ giải mã là bộ giải mã attention được mô tả ở trên. Chúng tôi sử dụng bộ tối ưu hóa bộ mã hóa và bộ giải mã từ Stochastic Gradient Descent sang Adagrad, vì nhận thấy các bản dịch có loss thấp hơn khi sử dụng Adagrad. Cuối cùng, sử dụng cross entropy làm hàm mục tiêu chính, trái ngược với hướng dẫn sử dụng nn.NLLLoss().
Chúng ta cũng nên nhìn vào tỷ lệ teacher_forcing_ratio. Giá trị này, được đặt thành .5, được sử dụng để giúp cải thiện hiệu quả của mô hình. Ở mức 0,5, nó xác định ngẫu nhiên xem có cung cấp mục tiêu làm đầu vào tiếp theo cho bộ giải mã hay sử dụng dự đoán của chính bộ giải mã hay không. Điều này có thể giúp dịch hội tụ nhanh hơn, nhưng cũng có thể dẫn đến sự mất ổn định.
def trainIters(encoder, decoder, n_iters, print_every=1000, plot_every=100):
start = time.time()
plot_losses = []
print_loss_total = 0 # Reset every print_every
plot_loss_total = 0 # Reset every plot_every
encoder_optimizer = optim.Adagrad(encoder.parameters())
decoder_optimizer = optim.Adagrad(decoder.parameters())
training_pairs = [tensorsFromPair(random.choice(pairs))
for i in range(n_iters)]
criterion = nn.CrossEntropyLoss()
for iter in range(1, n_iters + 1):
training_pair = training_pairs[iter - 1]
input_tensor = training_pair[0]
target_tensor = training_pair[1]
loss = train(input_tensor, target_tensor, encoder,
decoder, encoder_optimizer, decoder_optimizer, criterion)
print_loss_total += loss
plot_loss_total += loss
if iter % print_every == 0:
print_loss_avg = print_loss_total / print_every
print_loss_total = 0
print('%s (%d %d%%) %.4f' % (timeSince(start, iter / n_iters),
iter, iter / n_iters * 100, print_loss_avg))
if iter % plot_every == 0:
plot_loss_avg = plot_loss_total / plot_every
plot_losses.append(plot_loss_avg)
plot_loss_total = 0
showPlot(plot_losses)hidden_size = 256
encoder = EncoderRNN(input_lang.n_words, hidden_size).to(device)
attn_decoder = AttnDecoderRNN(hidden_size, output_lang.n_words, dropout_p=0.1).to(device)
trainIters(encoder1, attn_decoder1, 75000, print_every=5000)Bây giờ khởi tạo các mô hình bộ mã hóa và bộ giải mã attention để đào tạo và thực thi chức năng trainIters.
Chúng tôi sẽ sử dụng kích thước ẩn là 256 và đảm bảo rằng bạn đã đặt thiết bị của mình thành device(type='cuda'). Điều này sẽ đảm bảo rằng RNN huấn luyện sử dụng GPU.
Với việc sử dụng cơ chế attention cho mô hình seq2seq, kết quả cho bài toán dịch máy đã cả thiện lớn [3] và sau này cơ chế attention đã được ứng dụng và phát triển cho mô hình transformers [4].
Không những vậy, mô hình này còn có thể áp dụng cho các bài toán khác như nhận dạng kí tự (OCR) [5]
Tài liệu tham khảo
[1] Sequence to Sequence Learning with Neural Networks
[2] NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
[ 3] Effective Approaches to Attention-based Neural Machine Translation
[ 4] Attention is all you need
[ 5] Sequence to Sequence Learning for Optical Character Recognition https://arxiv.org/abs/1511.04176
[6] Dataset https://www.statmt.org/europarl/