Tinh chỉnh mô hình ngôn ngữ lớn (LLM)
Trong lĩnh vực trí tuệ nhân tạo đang phát triển nhanh chóng, việc sử dụng mô hình ngôn ngữ lớn (LLMs) một cách hiệu quả và hiệu suất ngày càng trở nên quan trọng hơn. Tuy nhiên, chúng ta có thể sử dụng các mô hình ngôn ngữ lớn theo nhiều cách khác nhau.
Về cơ bản, chúng ta có thể sử dụng các mô hình ngôn ngữ lớn được huấn luyện trước cho các nhiệm vụ mới theo hai cách chính: học trong ngữ cảnh và finetuning.
Trong bài viết này, chúng ta sẽ tóm tắt ngắn gọn về ý nghĩa của học trong ngữ cảnh, sau đó chúng ta sẽ đi qua các cách khác nhau để điều chỉnh lại LLMs.
Học trong ngữ cảnh và Chỉ mục hóa
Kể từ khi xuất hiện GPT-2 [ 2 ] và GPT-3 [ 3 ], chúng ta đã thấy rằng các mô hình ngôn ngữ lớn (LLMs) được huấn luyện trước trên một tập văn bản tổng quát có khả năng học trong ngữ cảnh, điều này không yêu cầu chúng ta phải huấn luyện lại hoặc điều chỉnh các LLMs được huấn luyện trước nếu chúng ta muốn thực hiện các nhiệm vụ cụ thể hoặc mới mà LLM không được huấn luyện rõ ràng trước đó. Thay vào đó, chúng ta có thể trực tiếp cung cấp một vài ví dụ về một nhiệm vụ mục tiêu thông qua đầu vào, như được minh họa trong ví dụ dưới đây.

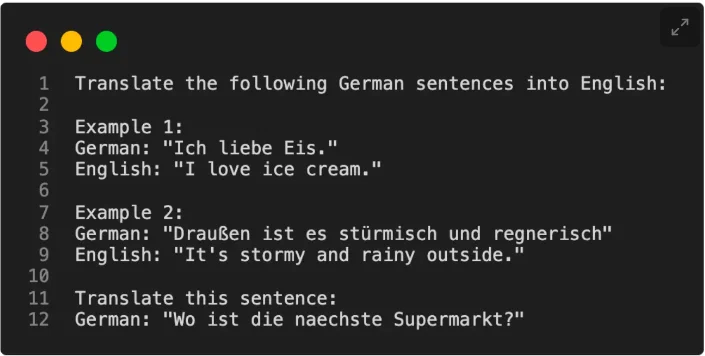
Học trong ngữ cảnh rất hữu ích nếu chúng ta không có truy cập trực tiếp vào mô hình, ví dụ như nếu chúng ta đang sử dụng mô hình thông qua một API.
Liên quan đến học trong ngữ cảnh là khái niệm điều chỉnh thông tin đầu vào để cải thiện kết quả đầu ra, được minh họa như bên dưới.

Nhân tiện, chúng ta gọi nó là hard prompt tuning vì chúng ta đang sửa đổi trực tiếp các từ hoặc mã thông báo đầu vào. Sau này, chúng ta sẽ thảo luận về một phiên bản khác biệt được gọi là soft prompt tuning (hoặc thường chỉ gọi là prompt tuning).
Phương pháp prompt tuning được đề cập ở trên cung cấp một phương án tiết kiệm tài nguyên hơn để thay thế cho việc điều chỉnh lại các tham số. Tuy nhiên, hiệu suất của nó thường không đạt được như việc finetuning, vì nó không cập nhật các tham số của mô hình cho một nhiệm vụ cụ thể, điều này có thể giới hạn tính linh hoạt của nó đối với những chi tiết cụ thể của nhiệm vụ. Hơn nữa, prompt tuning có thể tốn công sức, vì nó thường đòi hỏi sự tham gia của con người trong việc so sánh chất lượng của các prompt khác nhau.
Trước khi chúng ta thảo luận về điều chỉnh lại các tham số chi tiết hơn, một phương pháp khác để sử dụng một phương pháp dựa trên học trong ngữ cảnh là chỉ mục hóa. Trong lĩnh vực LLMs, chỉ mục hóa có thể được coi là một giải pháp tránh học trong ngữ cảnh, cho phép chuyển đổi LLMs thành các hệ thống truy xuất thông tin để trích xuất dữ liệu từ các nguồn tài nguyên và trang web bên ngoài. Trong quá trình này, một mô-đun chỉ mục hóa phân tích một tài liệu hoặc trang web thành các đoạn nhỏ hơn, chuyển đổi chúng thành các vector có thể được lưu trữ trong cơ sở dữ liệu vector. Sau đó, khi người dùng gửi một truy vấn, mô-đun chỉ mục hóa tính toán độ tương đồng vector giữa truy vấn được nhúng và mỗi vector trong cơ sở dữ liệu. Cuối cùng, mô-đun chỉ mục hóa truy xuất top k vector có độ tương đồng cao nhất để tạo ra câu trả lời.
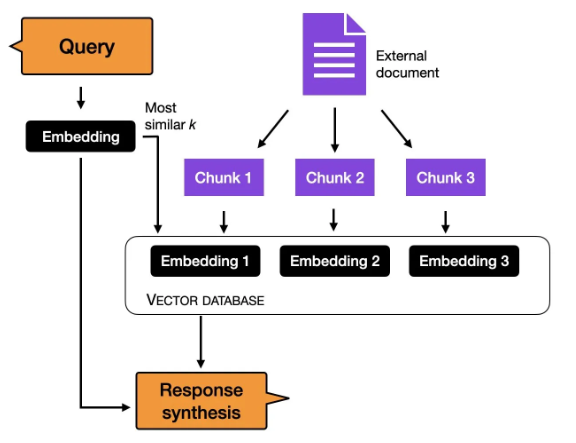
Ba phương pháp truyền thống dựa trên đặc trưng và điều chỉnh lại tham số
Học trong ngữ cảnh là một phương pháp có giá trị và thân thiện với người dùng trong các tình huống mà truy cập trực tiếp vào mô hình ngôn ngữ lớn (LLM) bị giới hạn, chẳng hạn như khi tương tác với LLM thông qua API hoặc giao diện người dùng.
Tuy nhiên, nếu chúng ta có truy cập vào LLM, việc thích ứng và điều chỉnh lại nó trên một nhiệm vụ mục tiêu bằng cách sử dụng dữ liệu từ một lĩnh vực mục tiêu thường dẫn đến kết quả tốt hơn. Vậy, làm cách nào chúng ta có thể thích ứng một mô hình cho một nhiệm vụ mục tiêu? Có ba phương pháp truyền thống được đề cập trong hình dưới đây.
Để cung cấp một số bối cảnh thực tế cho các thảo luận dưới đây, chúng ta sẽ điều chỉnh lại một LLM kiểu mã hóa như BERT [ 1 ]cho một nhiệm vụ phân loại. (Để giữ cho mọi thứ đơn giản, nhiệm vụ phân loại này dự đoán xem một bài đánh giá phim có tính cảm xúc tích cực hay tiêu cực.) Lưu ý rằng thay vì điều chỉnh lại một LLM kiểu mã hóa, cùng phương pháp này cũng có thể áp dụng cho các LLM kiểu giải mã như GPT . Hơn nữa, chúng ta cũng có thể điều chỉnh lại các LLM kiểu giải mã để tạo ra các câu trả lời đa câu hỏi thay vì chỉ phân loại văn bản. Để làm điều này, tôi sẽ cung cấp các ví dụ thực tế trong các bài viết trong tương lai.
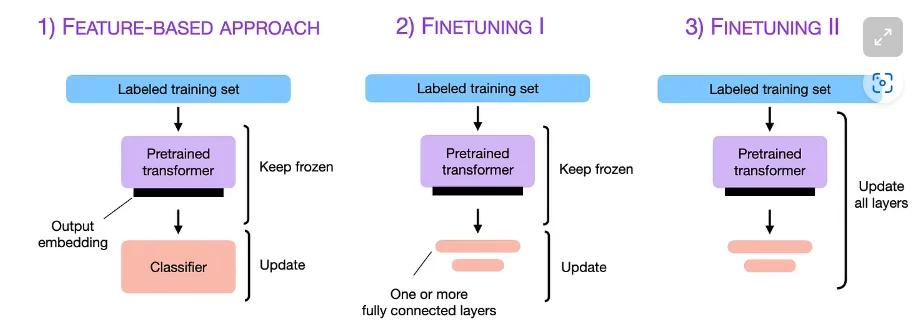
- Phương pháp dựa trên đặc trưng
Trong phương pháp dựa trên đặc trưng, chúng ta tải một LLM được huấn luyện trước và áp dụng nó vào tập dữ liệu mục tiêu của chúng ta. Ở đây, chúng ta đặc biệt quan tâm đến việc tạo ra các nhúng đầu ra cho tập huấn luyện, mà chúng ta có thể sử dụng như các đặc trưng đầu vào để huấn luyện một mô hình phân loại. Mặc dù phương pháp này phổ biến đối với các mô hình tập trung vào nhúng như BERT, chúng ta cũng có thể trích xuất nhúng từ các mô hình phong phú kiểu GPT.Mô hình phân loại có thể là một mô hình hồi quy logistic, Random Forest, hoặc XGBoost – bất cứ điều gì mà trái tim chúng ta muốn. (Tuy nhiên, dựa trên kinh nghiệm của tôi, các bộ phân loại tuyến tính như hồi quy logistic thường hoạt động tốt nhất ở đây.)Về mặt khái niệm, chúng ta có thể minh họa phương pháp dựa trên đặc trưng bằng đoạn code sau:
model = AutoModel.from_pretrained("distilbert-base-uncased")
# ...
# tokenize dataset
# ...
# generate embeddings
@torch.inference_mode()
def get_output_embeddings(batch):
output = model(
batch["input_ids"],
attention_mask=batch["attention_mask"]
).last_hidden_state[:, 0]
return {"features": output}
dataset_features = dataset_tokenized.map(
get_output_embeddings, batched=True, batch_size=10)
X_train = np.array(imdb_features["train"]["features"])
y_train = np.array(imdb_features["train"]["label"])
X_val = np.array(imdb_features["validation"]["features"])
y_val = np.array(imdb_features["validation"]["label"])
X_test = np.array(imdb_features["test"]["features"])
y_test = np.array(imdb_features["test"]["label"])
# train classifier
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression()
clf.fit(X_train, y_train)
print("Training accuracy", clf.score(X_train, y_train))
print("Validation accuracy", clf.score(X_val, y_val))
print("test accuracy", clf.score(X_test, y_test))2. Điều chỉnh lại tham số I – Cập nhật các lớp đầu ra
Một phương pháp phổ biến liên quan đến phương pháp dựa trên đặc trưng được mô tả ở trên là điều chỉnh lại các lớp đầu ra (chúng ta sẽ đề cập đến phương pháp này là điều chỉnh lại tham số I). Tương tự như phương pháp dựa trên đặc trưng, chúng ta giữ nguyên các tham số của LLM được huấn luyện trước. Chúng ta chỉ huấn luyện lại các lớp đầu ra mới được thêm vào, tương tự như huấn luyện một bộ phân loại hồi quy logistic hoặc perceptron đa tầng nhỏ trên các đặc trưng nhúng.
model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased",
num_labels=2
)
# freeze all layers
for param in model.parameters():
param.requires_grad = False
# then unfreeze the two last layers (output layers)
for param in model.pre_classifier.parameters():
param.requires_grad = True
for param in model.classifier.parameters():
param.requires_grad = True
# finetune model
lightning_model = CustomLightningModule(model)
trainer = L.Trainer(
max_epochs=3,
...
)
trainer.fit(
model=lightning_model,
train_dataloaders=train_loader,
val_dataloaders=val_loader)
# evaluate model
trainer.test(lightning_model, dataloaders=test_loader)Về lý thuyết, phương pháp này nên có hiệu suất mô hình tương tự và tốc độ tương tự như phương pháp dựa trên đặc trưng vì chúng ta sử dụng cùng một mô hình gốc được đóng băng. Tuy nhiên, vì phương pháp dựa trên đặc trưng làm cho việc tính toán và lưu trữ các đặc trưng nhúng cho tập dữ liệu huấn luyện dễ dàng hơn một chút, phương pháp dựa trên đặc trưng có thể thuận tiện hơn cho các tình huống cụ thể trong thực tế.
3. Điều chỉnh lại tham số II – Cập nhật tất cả các lớp
Trong khi báo cáo gốc về BERT [ 1 ] cho thấy việc chỉ điều chỉnh lại lớp đầu ra có thể dẫn đến hiệu suất mô hình tương đương với việc điều chỉnh lại tất cả các lớp, nhưng điều này đòi hỏi nhiều tham số hơn và do đó đắt đỏ hơn. Ví dụ, một mô hình BERT cơ bản có khoảng 110 triệu tham số. Tuy nhiên, lớp cuối cùng của một mô hình BERT cơ bản cho phân loại nhị phân chỉ bao gồm 1.500 tham số. Hơn nữa, hai lớp cuối cùng của một mô hình BERT cơ bản chiếm khoảng 60.000 tham số – chỉ chiếm khoảng 0,6% tổng kích thước mô hình.
Kết quả của chúng ta sẽ khác nhau dựa trên mức độ tương đồng của nhiệm vụ mục tiêu và miền mục tiêu với tập dữ liệu mà mô hình được huấn luyện trước. Tuy nhiên, trong thực tế, điều chỉnh lại tất cả các lớp hầu như luôn dẫn đến hiệu suất mô hình tốt hơn.
Vì vậy, khi tối ưu hiệu suất mô hình, tiêu chuẩn vàng cho việc sử dụng các LLM được huấn luyện trước là cập nhật tất cả các lớp (đây được gọi là điều chỉnh lại tham số II). Về mặt khái niệm, điều chỉnh lại tham số II rất giống với điều chỉnh lại tham số I. Sự khác biệt duy nhất là chúng ta không đóng băng các tham số của LLM được huấn luyện trước mà điều chỉnh lại chúng:
model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased",
num_labels=2
)
# freeze layers (which we don't do here)
# for param in model.parameters():
# param.requires_grad = False
# finetune model
lightning_model = LightningModel(model)
trainer = L.Trainer(
max_epochs=3,
...
)
trainer.fit(
model=lightning_model,
train_dataloaders=train_loader,
val_dataloaders=val_loader)
# evaluate model
trainer.test(lightning_model, dataloaders=test_loader)Nếu bạn tò mò về một số kết quả thực tế, các đoạn mã trên đã được sử dụng để huấn luyện một bộ phân loại đánh giá phim sử dụng một mô hình DistilBERT cơ bản được huấn luyện trước (bạn có thể truy cập vào các tệp notebook mã nguồn tại đây):
- Phương pháp dựa trên đặc trưng với hồi quy logistic: độ chính xác kiểm tra 83%
- Điều chỉnh lại tham số I, cập nhật hai lớp cuối cùng: độ chính xác 87%
- Điều chỉnh lại tham số II, cập nhật tất cả các lớp: độ chính xác 92%.
Các kết quả này nhất quán với quy tắc chung là điều chỉnh lại nhiều lớp thường dẫn đến hiệu suất tốt hơn, nhưng điều đó đến với chi phí tăng lên.
Điều chỉnh lại tham số hiệu quả về tham số
Điều chỉnh lại tham số hiệu quả về tham số cho phép chúng ta tái sử dụng các mô hình được huấn luyện trước trong khi giảm thiểu các tài nguyên và tính toán. Tóm lại, điều chỉnh lại tham số hiệu quả về tham số hữu ích cho ít nhất 5 lý do sau:
Giảm chi phí tính toán (yêu cầu ít GPU và thời gian GPU hơn);
Tốc độ huấn luyện nhanh hơn (hoàn thành huấn luyện nhanh hơn);
Yêu cầu phần cứng thấp hơn (hoạt động với GPU nhỏ hơn và bộ nhớ ít hơn);
Hiệu suất mô hình tốt hơn (giảm thiểu quá khớp);
Lưu trữ ít hơn (phần lớn các trọng số có thể được chia sẻ trên các nhiệm vụ khác nhau).
Trong các phần trước, chúng ta đã học được rằng điều chỉnh lại nhiều lớp thông thường dẫn đến kết quả tốt hơn. Bây giờ, các thử nghiệm ở trên dựa trên một mô hình DistilBERT, một mô hình tương đối nhỏ. Nếu chúng ta muốn điều chỉnh lại các mô hình lớn hơn mà chỉ vừa với bộ nhớ GPU, ví dụ như các LLM sinh mới nhất, chúng tôi có thể sử dụng phương pháp dựa trên đặc trưng hoặc phương pháp điều chỉnh lại tham số I như trên. Nhưng giả sử chúng tôi muốn đạt được chất lượng mô hình tương tự như điều chỉnh lại tham số II?
Trong suốt nhiều năm, các nhà nghiên cứu đã phát triển nhiều kỹ thuật (Lialin et al.) để điều chỉnh lại LLM với hiệu suất mô hình cao chỉ yêu cầu huấn luyện một số lượng tham số nhỏ. Những phương pháp này thường được tham khảo là các kỹ thuật điều chỉnh lại tham số hiệu quả về tham số (PEFT).
Một số kỹ thuật PEFT được sử dụng phổ biến nhất được tóm tắt trong hình bên dưới.
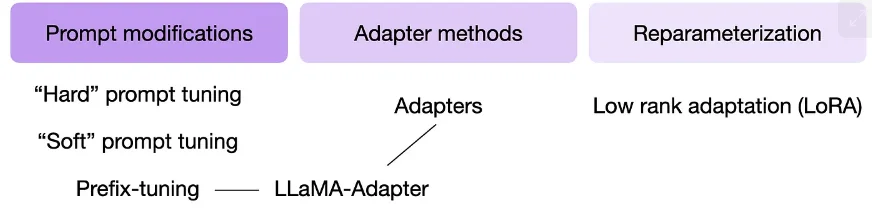
Vậy, các kỹ thuật này hoạt động như thế nào? Tóm lại, tất cả đều liên quan đến việc giới thiệu một số lượng nhỏ tham số bổ sung mà chúng ta điều chỉnh lại (thay vì điều chỉnh lại tất cả các lớp như chúng ta đã làm trong phương pháp Điều chỉnh lại tham số II ở trên). Theo một cách nào đó, Điều chỉnh lại tham số I (chỉ điều chỉnh lại lớp cuối cùng) cũng có thể được coi là một kỹ thuật điều chỉnh lại tham số hiệu quả. Tuy nhiên, các kỹ thuật như đặt tiền tố, adapter và chuyển đổi hạng thấp, tất cả đều “sửa đổi” nhiều lớp, đạt được hiệu suất dự đoán tốt hơn (với chi phí thấp).
Reinforcement Learning with Human Feedback
Trong Học tăng cường với Phản hồi từ con người (RLHF), một mô hình được huấn luyện trước được điều chỉnh lại sử dụng kết hợp giữa học có giám sát và học tăng cường – phương pháp này đã trở nên phổ biến nhờ mô hình ChatGPT ban đầu, được xây dựng dựa trên InstructGPT [ 4 ].
Trong RLHF, phản hồi từ con người được thu thập bằng cách yêu cầu con người xếp hạng hoặc đánh giá các đầu ra khác nhau của mô hình, cung cấp một tín hiệu thưởng. Những nhãn thưởng được thu thập có thể được sử dụng để huấn luyện một mô hình thưởng, sau đó sử dụng để hướng dẫn việc điều chỉnh lại LLM theo sở thích của con người.
Chính mô hình thưởng được học thông qua học có giám sát (thông thường sử dụng một LLM được huấn luyện trước làm mô hình cơ sở). Sau đó, mô hình thưởng được sử dụng để cập nhật LLM được huấn luyện trước mà sẽ được điều chỉnh lại theo sở thích của con người – quá trình huấn luyện sử dụng một dạng của học tăng cường gọi là tối ưu hóa chính sách gần nhất (Schulman et al.).

Tại sao lại sử dụng một mô hình thưởng thay vì huấn luyện mô hình được huấn luyện trước trực tiếp trên phản hồi từ con người? Điều đó bởi vì việc liên quan đến con người trong quá trình học sẽ tạo ra một chướng ngại vì chúng ta không thể nhận được phản hồi trong thời gian thực.
Kết luận
Điều chỉnh lại tất cả các lớp của một LLM được huấn luyện trước vẫn là tiêu chuẩn vàng để điều chỉnh lại cho các nhiệm vụ mới, nhưng có nhiều phương pháp hiệu quả khác cho việc sử dụng các bộ biến đổi được huấn luyện trước. Các phương pháp như tiếp cận dựa trên đặc trưng, học trong ngữ cảnh và các kỹ thuật điều chỉnh lại tham số hiệu quả về tham số cho phép ứng dụng hiệu quả của LLM cho các nhiệm vụ mới trong khi giảm thiểu chi phí tính toán và tài nguyên.
Hơn nữa, học tăng cường với phản hồi từ con người (RLHF) là một phương pháp thay thế cho việc điều chỉnh lại có giám sát, có thể cải thiện hiệu suất mô hình.
Trích dẫn
[ 1 ] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[ 2 ] Language Models are Unsupervised Multitask Learners
[ 3 ] Language Models are Few-Shot Learners
[ 4 ] Training language models to follow instructions with human feedback