Một số design pattern trong giao tiếp gói tin trên nền tảng Cloud
Giới thiệu:
Ngày nay, các ứng dụng cloud thường áp dụng kiến trúc micro-services và thiết kế thành các hệ thống phân tán (distributed system) thay vì một hệ thống xử lý tập trung như trong các kiến trúc truyền thống. Chúng ta đều đã biết đến những lợi ích to lớn mà các kiến trúc này mang lại như khả năng mở rộng (scalability), khả năng phục hồi (resilence), tính ổn định (reliability) và tính linh hoạt (flexibility). Tuy nhiên kiến trúc này cũng mang lại những khó khăn nhất định trong quá trình triển khai. Một trong số đó là cách thức giao tiếp giữa số lượng lớn các thành phần trong hệ thống phân tán và giữa các dịch vụ trong kiến trúc micro-services, các phương thức giao tiếp này cần đảm bảo một mối liên kết lỏng lẻo (loosely coupled) giữa các đối tượng cần giao tiếp để các đối tượng này có thể liên tục mở rộng một cách độc lập mà không cần phụ thuộc vào các đối tượng khác.
Các design pattern là các giải pháp tổng quát chung cho các vấn đề phổ biến. Cũng như các vấn đề khác trong lập trình, các vấn đề gặp phải trong việc triển khai cách thức giao tiếp giữa các đối tượng trong hệ thống phân tán và kiến trúc micro-services cũng có các giải pháp được khái quát hóa dưới dạng các design pattern. Bài viết này sẽ giới thiệu một vài design pattern trong số đó.
Claim check:
Vấn đề gặp phải:
Ngày nay các ứng dụng cloud được sử dụng ở hầu hết mọi lĩnh vực trong cuộc sống, do đó nội dung và loại hình các gói tin cần giao tiếp cũng ngày một đa dạng hơn. Trong nhiều trường hợp, các ứng dụng cloud sẽ phải xử lý các gói tin có kích thước rất lớn dưới nhiều dạng khác nhau như hình ảnh, tài liệu, tin nhắn thoại… Với kiến trúc micro-services, việc phải xử lý các gói tin lớn cũng gây nên các vấn đề liên quan đến băng thông cũng như yêu cầu nhiều tài nguyên tính toán hơn do các gói tin này không chỉ được xử lý một lần bởi một ứng dụng duy nhất (kiến trúc monolithic) mà nó sẽ được xử lý bởi một chuỗi các service, các gói tin lớn này sẽ được truyền đi từ service này qua service khác thậm chí từ một service đến nhiều service khác. Trong chuỗi xử lý này, phần dữ liệu có kích thước lớn thường chỉ được sử dụng bởi một vài service nhất định, việc truyền phần dữ liệu này kèm gói tin gây nên sự lãng phí tài nguyên không cần thiết trong hệ thống. Thêm nữa, các kiến trúc được áp dụng trong giao tiếp giữa các micro-services thường được thiết kế tối ưu cho việc xử lý các gói tin nhỏ nhưng với số lượng khổng lồ (horizontal scaling), do đó việc phải xử lý các gói tin lớn sẽ khiến cho toàn bộ hệ thống hoạt động thiếu hiệu quả và làm chậm cả hệ thống.
Giải pháp:
Design pattern này có tên là claim check, claim check ở đây mang nghĩa tờ phiếu hành khách nhận được khi ký gửi hành lý ở các sân bay. Cái tên này cũng phần nào gợi đến cách tiếp cận của design pattern này với vấn đề nêu trên. Vấn đề ở trên cũng giống như vấn đề gặp phải khi các hành khách phải mang theo lượng lớn hành lý lên đến vài chục ký và sẽ rất bất tiện nếu hành khách phải mang theo hành lý đó bên mình trong suốt quá trình di chuyển ở sân bay cũng như lên máy bay. Giải pháp là hành khách sẽ ký gửi hành lý khi vừa đến sân bay và nhận về phiếu ký gửi dán kèm cùng vé máy bay, khi đến nơi khách hàng sẽ dùng phiếu ký gửi đó để nhận lại hành lý tại điểm đến. Design pattern claim check thực hiện quá trình tương tự như vậy bằng cách bóc tách gói tin kèm dữ liệu ở đầu gửi thành hai phần: phần dữ liệu có kích thước lớn (payload) và phần còn lại của gói tin (ví dụ như metadata) đi kèm với một mã định danh (claim check) ứng với phần dữ liệu. Phần dữ liệu sẽ được lưu trên một nền tảng lưu trữ như một cơ sở dữ liệu hay một object storage, phần mã định danh đính kèm với gói tin đóng vai trò như địa chỉ trỏ đến phần dữ liệu đã được lưu trữ. Sau đó, gói tin đính kèm mã định danh sẽ được truyền đi và tiếp tục xử lý bởi các service khác. Ở chiều nhận, nếu service cần sử dụng đến dữ liệu, service đó có thể truy xuất dữ liệu dựa trên mã định danh được đính kèm.

Hình 1. Sơ đồ cách vận hành của design pattern claim check
Design pattern này có thể tóm tắt bằng 6 bước như sau:
- Gói tin với dữ liệu có kích thước lớn được gửi đi
- Phần dữ liệu được tách ra khỏi gói tin và được lưu trữ trong cơ sở dữ liệu hoặc một nền tảng lưu trữ khác
- Phần gói tin sau khi đã được tách dữ liệu sẽ được đính kèm theo claim check có vai trò như địa chỉ trỏ đến dữ liệu đã được lưu trữ
- Gói tin thu được ở bước 3 sẽ được gửi đi để xử lý tiếp hoặc đẩy vào hàng chờ
- Khi gói tin được nhận, phần dữ liệu được tách ra có thể được truy xuất và ghép lại
- Dữ liệu sau khi được truy xuất có thể được xử lý cùng với gói tin
Request – reply bất đồng bộ:
Vấn đề gặp phải:
Trong các ứng dụng, việc giao tiếp giữa các thành phần thường được thực hiện qua các API và phổ biến nhất là REST API. Khi người dùng thực hiện các yêu cầu (request) trên ứng dụng phía người dùng (client-side application), các yêu cầu này được ứng dụng gửi đi dưới dạng các API request đến back-end hay server-side để xử lý request này và trả lại kết quả (reply) cho ứng dụng client-side. Có hai phương thức triển khai cơ chế request – reply này, đó là: đồng bộ và bất đồng bộ.
Đối với cơ chế request – reply đồng bộ, phía client sau khi gửi request sẽ chờ reply từ phía server trước khi tiếp tục gửi các request khác. Cơ chế này không gặp vấn đề gì khi các API request được xử lý nhanh chóng và ngay lập tức trả về reply cho phía client. Tuy nhiên, trong nhiều trường hợp, server không thể xử lý request đủ nhanh do các nguyên nhân như đường truyền mạng, khoảng cách địa lý, kích thước của gói tin, số lượng request mà server phải xử lý hoặc đôi khi chính tính chất của request cũng yêu cầu server phải xử lý trong thời gian dài, ví dụ như các tác vụ liên quan đến AI hoặc tạo các hạ tầng trên nền tảng cloud như máy ảo. Việc xử lý các request như vậy có thể lên tính bằng nhiều phút hoặc thậm chí hàng giờ. Do đó, sử dụng cơ chế request – reply đồng bộ sẽ khiến phía client phải chờ trong một thời gian dài trước khi nhận được kết quả mà không nhận được thông tin phản hồi nào trong suốt quá trình. Vấn đề này không chỉ gặp phải với các ứng dụng có kiến trúc client – server mà nó cũng xảy ra trong giao tiếp giữa các thành phần trong hệ thống phân tán (server-to-server) khi một thành phần gọi đến API của một thành phần khác, điều này làm giảm năng suất cũng như khả năng mở rộng của hệ thống.
Giải pháp:
Vấn đề nêu trên có thể làm ta liên tưởng đến vấn đề chúng ta gặp phải khi đặt một đơn hàng mà phải mất hàng tuần mới có thể giao đến và chúng ta phải chờ trong suốt thời gian đó mà không nhận được thông tin trạng thái nào về đơn hàng. Giải pháp của các nền tảng thương mại điện tử cho vấn đề này là ngay lập tức phản hồi người dùng rằng đơn hàng đã được tiếp nhận và trong quá trình xử lý, sau đó người dùng có thể tiếp tục đặt các đơn hàng khác, ngoài ra người dùng cũng có thể thường xuyên theo dõi trạng thái đơn hàng. Giải pháp của design pattern này cũng tiếp cận vấn đề một cách tương tự. Trong design pattern này, API được gọi đến bởi request không có nhiệm vụ xử lý request mà chỉ có nhiệm vụ tiếp nhận request, chuyển tiếp request này vào một hàng chờ để phía server xử lý và phản hồi lại là request đã được tiếp nhận thành công hay chưa một cách nhanh nhất có thể (để giảm độ trễ tối đa, các nền tảng cloud có thể thiết kế các tài nguyên tính toán được sử dụng cho việc này ở gần với người dùng nhất có thể về mặt địa lý). Nếu được tiếp nhận thành công, trong phản hồi trạng thái tiếp nhận request, API này cũng sẽ gửi cho người dùng một đầu mối (endpoint) để người dùng có thể liên tục kiểm tra trạng thái xử lý request (có thể là một API endpoint hoặc đường dẫn chứa số định danh của request – giống như mã vận đơn để theo dõi một đơn hàng). Cuối cùng, sau khi trạng thái xử lý request được xác định là hoàn tất, một phản hồi về kết quả sẽ được trả lại cho phía client. Nếu kích thước của gói tin phản hồi quá lớn, ta có thể áp dụng kết hợp design pattern claim check nêu ở trên để trả về cho client đường dẫn đến kết quả (resource URI ở hình bên dưới) thay vì chứa toàn bộ nội dung trong phản hồi.
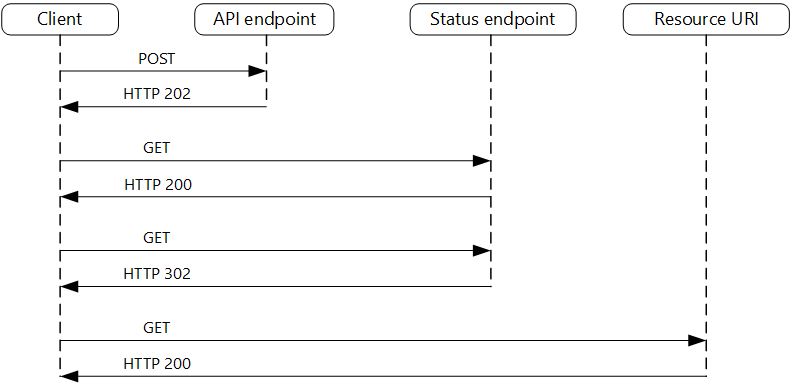
Hình 2. Flowchart của design pattern request – reply bất đồng bộ
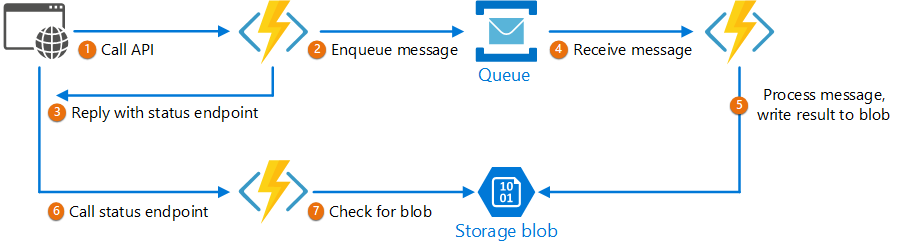
Hình 3. Ví dụ về cách design patter request – reply bất đồng bộ được áp dụng trong chu trình xử lý request
(Resource URI ở flowchart trên được triển khai dưới dạng đường dẫn đến các object trong object storage)
Publisher – Subscriber:
Vấn đề gặp phải:
Trong các hệ thống phân tán, đôi khi các thành phần trong hệ thống cần giao tiếp một gói tin với cùng nội dung đến nhiều thành phần khác trong hệ thống, ví dụ như các ứng dụng đa nền tảng, sau khi thông tin được xử lý, kết quả cần được gửi đồng thời đến ứng dụng di động và ứng dụng web. Một trường hợp sử dụng khác là khi người phát triển cần thu thập thông tin với mục đích kiểm tra, phân tích hoặc debug luồng vận hành giữa các thành phần nhưng không muốn ảnh hưởng tới các thành phần đang vận hành trực tiếp, khi đó phía nguồn gửi sẽ phải gửi cùng một gói tin đến các service thực hiện các tác vụ xử lý ứng với từng mục đích. Trong các kiến trúc giao tiếp bất đồng bộ, để tách rời mối liên kết chặt chẽ (tightly coupled) giữa bên gửi và bên nhận nhằm tăng khả năng mở rộng của hệ thống, một hàng chờ (queue) thường được đặt giữa phía gửi và phía nhận để các gói tin có thể được liên tục gửi đi từ bên gửi, trong khi đó bên nhận có thể lần lượt xử lý từng gói tin từ trong hàng chờ với tần suất độc lập với bên gửi. Tuy nhiên trong trường hợp có nhiều nguồn gửi và mỗi nguồn gửi lại gửi đến nhiều điểm nhận, việc tạo một hàng chờ cho mỗi liên kết đó rất khó để hệ thống có thể mở rộng vì số lượng liên kết từ điểm đến điểm (point-to-point) khi đó trở nên rất nhiều (tăng theo cấp số nhân). Để giải quyết vấn đề về số lượng liên kết, chúng ta có thể nghĩ đến giải pháp sử dụng một khối xử lý trung tâm có một hàng chờ lớn cho tất cả các giao tiếp. Với kiến trúc này, số lượng liên kết khi hệ thống mở rộng chỉ tăng lên theo cấp số cộng. Tuy nhiên, các phương pháp triển khai truyền thống sẽ yêu cầu khối xử lý trung gian này phải đóng vai trò như một bộ định tuyến và khối xử lý này sẽ dần trờ thành một nút cổ chai (bottleneck) trong hệ thống khi số đầu mối gửi và nhận dần tăng lên. Ngoài ra, kiến trúc này vẫn chưa giải quyết được vấn đề các gói tin với nội dung giống hệt nhau nhưng khác thông tin điểm nhận được truyền đi trong hệ thống gây hao phí tài nguyên băng thông một cách không cần thiết.
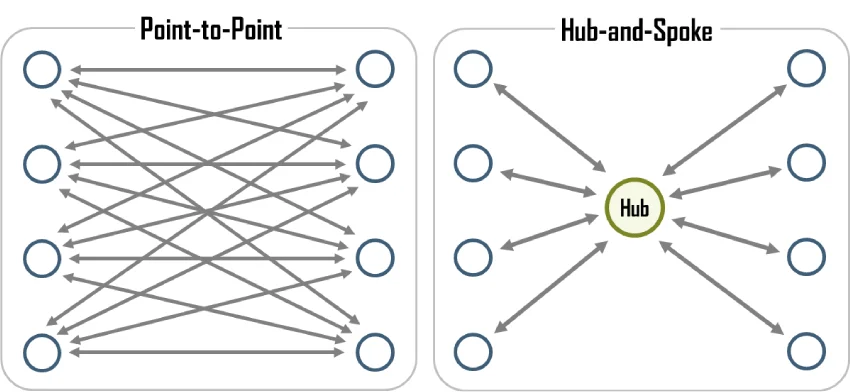
Hình 4. So sánh kết nối điểm đến điểm (point-to-point) và kết nối trung gian thông qua hub
Giải pháp:
Trong design pattern publisher – subscriber (hay gọi tắt là pub-sub), publisher là phía nguồn gửi, subscriber là các đầu mối nhận gói tin. Giải pháp đưa ra cho vấn đề nêu trên là sử dụng một hệ thống trung gian để phân phối các gói tin (message broker) tuy nhiên hệ thống trung gian này không có nhiệm vụ định tuyến nên tải xử lý sẽ được giảm đi cũng như có thể dễ dàng mở rộng khi cần thiết. Để đáp ứng được hai tiêu chí đó, bên trong message broker sẽ có hai kênh: kênh đầu vào để tiếp nhận gói tin từ publisher được gọi là topic, kênh đầu ra để đẩy các gói tin từ message broker đến các subscriber được gọi là subscription. Mối liên hệ giữa publisher và topic cũng như subscriber và subscription là mối quan hệ nhiều – nhiều (many-to-many), nghĩa là, một publisher có thể gửi gói tin đến nhiều topic và một topic cũng có thể nhận gói tìn từ nhiều publisher, tương tự với subscriber và subscription (tham khảo sơ đồ ở hình 5). Message broker còn đóng vai trò nhân bản các gói tin gốc thành các bản sao để gửi đến các subscriber. Với cơ chế này các gói tin gửi đi sẽ không cần chứa thông tin địa chỉ nhận vì luồng đi của gói tin đã được hình thành sẵn dựa trên các topic và subscription, do đó message broker sẽ được giảm tải vì không cần phải đóng vai trò của một thiết bị định tuyến. Đồng thời băng thông của hệ thống cũng được giảm tải do phía gửi không cần phải gửi nhiều gói tin với cùng nội dung nhưng tới các địa chỉ khác nhau mà chỉ cần gửi duy nhất một gói tin tới message broker. Về khả năng mở rộng hệ thống, message broker có thể dễ dàng mở rộng nhờ tính linh hoạt của thiết kế này, khi message broker được triển khai dưới dạng một hệ thống phân tán, mỗi đơn vị tính toán của hệ thống này (có thể dưới dạng máy ảo hoặc container) chỉ cần quản lý một số lượng nhất định các topic và subscription một cách độc lập thay vì phải nắm toàn bộ thông tin về tất cả các subscriber để làm nhiệm vụ định tuyến.
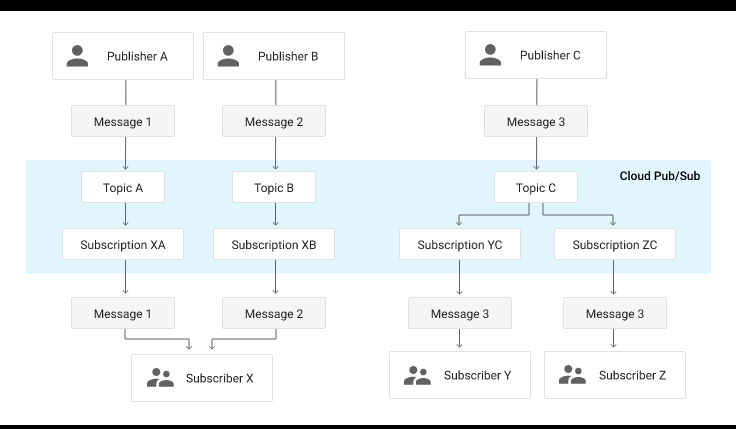
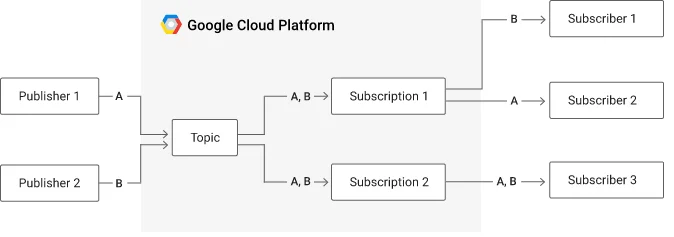
Hình 5. Sơ đồ luồng vận hành của design pattern publisher – subscriber
Choreography:
Vấn đề gặp phải:
Trong các ứng dụng áp dụng kiến trúc micro-services, các tính năng thường được thực thi bởi một chuỗi các service theo một luồng (workflow) nhất định với đầu ra của một service là đầu vào của một hoặc nhiều service khác. Việc giao tiếp giữa các service thường được thực hiện bằng cách gọi các API của service khác. Điều này gây ra một số khó khăn nhất định trong việc quản lý luồng vận hành của các service đặc biệt trong các ứng dụng doanh nghiệp (enterprise) khi có những luồng vận hành rất phức tạp dẫn đến số lượng liên kết điểm đến điểm (point-to-point) giữa các service cũng sẽ vì thế mà trở nên rất lớn. Giải pháp phổ biến nhất cho vấn đề này là sử dụng một service trung tâm có vai trò quản lý luồng vận hành của các service còn lại, service này thường được gọi là orchestrator. Trong kiến trúc này, orchestrator sẽ gọi đến lần lượt các API của các API dựa trên logic luồng vận hành được lập trình bên trong orchestrator, và các service khác cũng chỉ giao tiếp với orchestrator, nhờ đó kiến trúc này giảm được số lượng liên kết giữa các service. Orchestrator cũng có thể được trang bị các tính năng nâng cao như tự động thử lại khi xảy ra lỗi hoặc quản lý tình trạng của các service để tự động thay thế các service không hoạt động. Mặc dù được sử dụng rộng rãi nhưng kiến trúc này cũng gặp phải những vấn đề nhất định và không phù hợp trong một số hoàn cảnh. Orchestrator đóng vai trò xử lý trung tâm nên sẽ gây nên một điểm lỗi duy nhất (single point of failure) và nghẽn cổ chai (bottleneck) trong hệ thống, đồng thời việc orchestrator quản lý tất cả các service còn lại cũng sẽ tạo nên các liên kết chặt chẽ (tightly coupled) giữa orchestrator với tất cả các service đó, điều này ảnh hưởng đến khả năng mở rộng (scalability) của hệ thống. Ngoài ra, việc orchestrator cần một logic định sẵn về luồng vận hành để quản lý các service cũng làm giảm tính linh hoạt của hệ thống, mỗi khi luồng vận hành cần thêm hoặc bớt các service thì logic bên trong orchestrator cũng cần phải được định nghĩa lại.
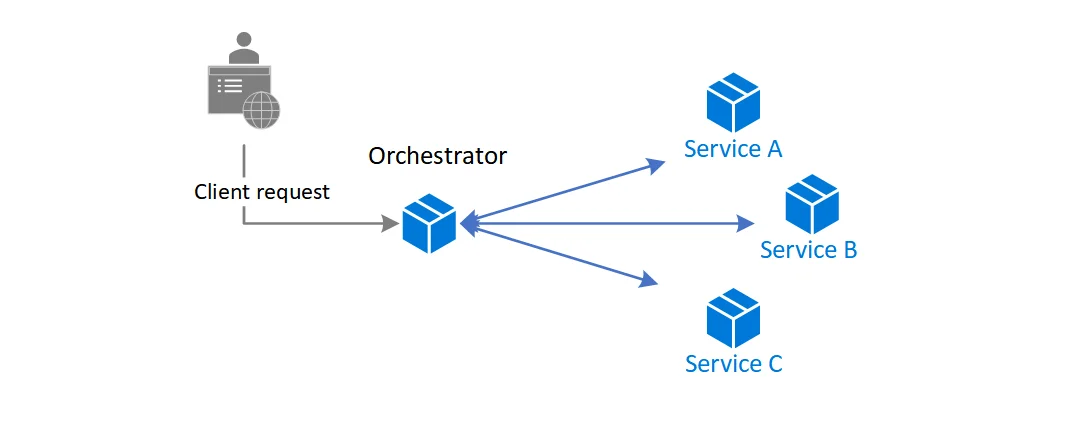
Hình 6. Kiến trúc sử dụng service trung tâm quản lý luồng vận hành(orchestrator)
Giải pháp:
Giải pháp được đề xuất trong design pattern choreography là thay thế service orchestrator bằng một message broker (tương tự như trong design pattern pub-sub) để các service có thể giao tiếp với nhau và tự động tạo nên một luồng vận hành mà không cần đến một service quản lý trung tâm. Cơ chế pub-sub chính là cốt lõi của việc tạo nên luồng vận hành này bằng cách gán topic cho các service ở phía trước trong chuỗi để đẩy gói tin đi và các service ở phía sau trong chuỗi sẽ được gán với các subscription để tiếp nhận gói tin, có thể hiểu một cách đơn giản các service tạo đầu vào cho các service khác là các publisher và các service tiếp nhận đầu ra từ các service khác là các subscriber, một service có thể vừa là publisher vừa là subscriber. Giải pháp này giải quyết được vấn đề về mối liên kết chặt chẽ giữa các service vì mối liên kết này được tách rời (decouple) bởi message broker và tình trạng nghẽn cổ chai và điểm lỗi duy nhất khi sử dụng một service xử lý trung tâm. Tuy nhiên, kiến trúc choreography sẽ mất đi khả năng phục hồi (resilence) mà orchestrator mang lại do lúc này không có một service bên ngoài để quản lý và giám sát, vì vậy để đạt được tính ổn định, các service cần được thiết kế để đạt được các tính chất như tính sẵn sàng và khả năng chịu lỗi cao.

Hình 7. Ví dụ áp dụng kiến trúc Choreography trong ứng dụng giao hàng bằng drone
Chúng ta có thể tham khảo hình bên trên về ví dụ của một ứng dụng giao hàng bằng drone để hiểu rõ hơn về kiến trúc này. Trong ứng dụng này, có bốn service tham gia vào luồng vận hành: tiếp nhận đơn hàng (ingestion), package (đóng gói), lập lịch cho drone (drone scheduler) và giao hàng (delivery). Trong ví dụ này, service ingestion sẽ là publisher cho service package và service package vừa là subscriber của service ingestion vừa là publisher cho service scheduler, cứ như vậy lần lượt với các service phía sau trong chuỗi vận hành. Ta có thể thấy từ ví dụ, bằng việc đẩy gói tin vào topic ở chiều gửi và đăng ký vào luồng subscription ở chiều nhận, các service tự tạo nên một luồng vận hành mà không cần đến sự can thiệp của một orchestrator. Ở hình bên trên ta cũng có thể thấy một thành phần được thêm vào kiến trúc để bù đắp điểm yếu về khả năng phục hồi và khả năng giám sát tình trạng của các service trong kiến trúc này, đó là một hàng chờ cho các gói tin gửi không thành công (dead letter queue / DLQ). Nhờ việc kiểm tra DLQ, một service bên ngoài có thể thử gửi lại và kiểm tra service bị lỗi khi xác định lỗi sau nhiều lần thử lại không thành công.