Phân loại ảnh văn bản – Document image classification
Phân loại ảnh văn bản, theo định nghĩa từ nghiên cứu của ĐH Queen, Canada [1], là việc gán nhãn một ảnh văn bản, dựa trên một tập các loại văn bản khác nhau được định nghĩa trước. Công nghệ này đóng vai trò quan trọng trong các luồng phân tích văn bản tự động, hoặc các quy trình xử lý văn bản trong doanh nghiệp. Mặc dù ngành thị giác máy hiện nay đã có những tiến bộ mạnh mẽ, đặc biệt với sự xuất hiện của các mạng học sâu, bài toán phân lớp văn bản vẫn là một bài toán khó.
Trong bài viết này, chúng tôi sẽ cung cấp một cái nhìn tổng quan về bài toán phân loại văn bản, cũng như một trong những phương pháp phổ biến để giải bài toán này, dựa trên các mạng neuron nhân tạo.
1. Tổng quan bài toán
1.1. Định nghĩa bài toán
Một bài toán phân lớp văn bản thường bao gồm hai thành phần chính: không gian văn bản, và tập các nhãn văn bản. Ở đây, không gian văn bản được định nghĩa là tập các ảnh đầu vào có thể của thuật toán phân lớp. Ví dụ như tập các ảnh văn bản hành chính được phát hành bởi công ty Samsung SDS trong quá khứ, hiện tại, và tương lai. Mỗi ảnh văn bản sẽ được đính kèm một hoặc nhiều nhãn văn bản khác nhau, đại diện cho loại văn bản của ảnh đó. Ví dụ, các văn bản hành chính phát hành bởi công ty Samsung SDS có thể được gán một trong các nhãn: Đơn xin phê duyệt tăng ca, Đơn xin nghỉ ốm, và Đơn xin trợ cấp học tập. Nhiệm vụ của thuật toán phân lớp văn bản là dự đoán đúng các nhãn tương ứng với từng ảnh văn bản đầu vào. Diễn giải theo ngôn ngữ toán học, thuật toán sẽ chia không gian văn bản thành các không gian con, tương ứng với từng nhãn văn bản. Các nhãn văn bản thường được định nghĩa dựa trên sự tương đồng về nội dung hoặc hình thức của văn bản.
1.2. Khó khăn chính đối với bài toán phân lớp
Đề cập tới không gian văn bản, khó khăn đầu tiên của việc phân lớp liên quan tới chất lượng ảnh đầu vào. Cụ thể, có nhiều ảnh đầu vào được chụp bởi những camera kém chất lượng, dẫn tới ảnh nhiễu, mờ, hoặc sai lệch về màu sắc. Bản thân tờ văn bản được chụp cũng có thể bị uốn gấp, hoặc nhàu nát. Đối với ảnh scan, việc sử dụng máy scan không đạt chuẩn cũng có thể ảnh hưởng tới chất lượng đầu vào của thuật toán.
Khó khăn tiếp theo liên quan tới việc gán nhãn văn bản phục vụ huấn luyện và đánh giá mô hình. Cụ thể, một số ảnh có thể không được gán nhãn, thường là các ảnh không liên quan tới quy trình doanh nghiệp. Ngược lại, do sự không rõ ràng trong việc phân định các nhãn văn bản, một số ảnh có thể được gán nhiều nhãn khác nhau.
Bản thân việc đánh nhãn cũng có những khó khăn riêng. Cụ thể, việc đánh nhãn thủ công các ảnh văn bản yêu cầu một định nghĩa chính xác về từng loại văn bản khác nhau, tránh nhập nhằng nhầm lẫn, gây khó khăn cho người đánh nhãn. Tuy nhiên, việc đưa ra những định nghĩa như vậy thường rất khó và mất thời gian, và việc tuân thủ chặt chẽ các định nghĩa đó cũng rất mệt mỏi đối với người đánh nhãn.
Một khó khăn thường thấy nữa là mất cân bằng dữ liệu, do một số loại văn bản chỉ có số lượng ít ảnh, như Giấy nghỉ ốm, trong khi một số loại khác lại rất nhiều, ví dụ như Hóa đơn. Việc mất cân bằng dữ liệu ảnh hưởng tới việc huấn luyện và đánh giá thuật toán phân lớp, tạo ra các thuật toán tồi, thậm chí làm sai lệch số liệu đánh giá.
1.3. Phương pháp đánh giá thuật toán phân lớp
Các phương pháp đánh giá truyền thống sử dụng Accuracy metric (độ chính xác) làm độ đo đánh giá sự hiệu quả của phương pháp phân lớp. Tuy nhiên, độ đo này tỏ ra không hiệu quả đối với dữ liệu mất cân bằng, do nó không phản ánh đúng chất lượng của thuật toán trong những trường hợp như vậy. Do đó, ta có thể cân nhắc các độ đo thay thế mạnh mẽ hơn như Precision, Recall, hoặc F1 score. Ngoại các độ đo trên, còn rất nhiều độ đo khác như mean Average Precision.

(Nguồn: ResearchGate)
Do sự đa dạng của các độ đo đánh giá, việc lựa chọn một độ đo phù hợp là rất quan trọng. Một độ đo tốt cần phản ảnh được bản chất của bài toán, mối quan tâm của người dùng, và các vấn đề liên quan. Ví dụ, nếu các dự đoán False Negative có thể gây ra hậu quả nghiêm trọng, thì độ đo Recall nên được ưu tiên.
1.4. Bộ dữ liệu đánh giá và độ chính xác hiện tại của các thuật toán phân lớp
Hiện nay có rất nhiều bộ dữ liệu khác nhau cho bài toán phân loại văn bản được công bố, phục vụ mục đích đánh giá các thuật toán phân lớp. Một trong các bộ nổi tiếng nhất là bộ RVL-CDIP với 400,000 ảnh đen trắng và 16 loại nhãn khác nhau. Bộ dữ liệu được chia thành tập huấn luyện với 320,000 ảnh, tập kiểm chứng (validation) với 40,000 ảnh, và tập đánh giá (test) với 40,000 ảnh còn lại.

(Nguồn: paperswithcode)
Theo bảng xếp hạng tại paperswithcode, các thuật toan phân lớp văn bản tân tiến nhất đã đạt được độ chính xác trên 95%. Đa phần trong số đó là các phương pháp Transfer learning dựa trên kiến trúc Transformer (một loại mạng học sâu) cũng như nội dung và hình thức của văn bản đầu vào. Nổi bật nhất trong các phương pháp này là họ phương pháp LayoutLM được đề xuất bởi Viện nghiên cứu Microsoft tại Châu Á, bắt nguồn từ bài toán đọc hiểu ảnh văn bản.
Phần tiếp theo đây sẽ cung cấp cái nhìn tổng quan về LayoutLM, cũng như LayoutLMv2, một cải tiến của LayoutLM, như một cách tiếp cận bài toán phân loại ảnh văn bản.
2. LayoutLM – Một cách tiếp cận bài toán phân lớp ảnh văn bản
LayoutLM [2] là một phương pháp bắt nguồn từ bài toán đọc hiểu ảnh văn bản. Bài toán này được đánh giá là rất thử thách, do sự đa dạng về bố cục và hình thức của văn bản, chất lượng tệ của các máy scan thông thường, và sự phức tạp trong cấu trúc văn bản.
Trước LayoutLM, các phương pháp AI cho bài toán này thường được xây dựng dựa trên các mạng học sâu chuyên biệt cho thị giác máy, hoặc cho xử lý ngôn ngữ tự nhiên, hoặc kết hợp của cả hai. Các công trình nghiên cứu đầu tiên về bài toán này thường tập trung vào khoanh vùng và phân tích các vùng khác nhau trong ảnh đầu vào, ví dụ như bảng biểu hoặc hình vẽ. Ở các công trình sau, các nhà nghiên cứu sử dụng các mô hình Faster R-CNN hoặc Mask R-CNN để tăng độ chính xác cho việc khoanh vùng. Mới đây nhất, tận dụng các tiến bộ trong phương pháp mạng tích chập đồ thị (Graph convolutional networks – GCN) trong việc trích xuất thông tin hình ảnh và ngôn ngữ, các mô hình GCN đã được sử dụng để kết hợp thông tin văn bản và hình ảnh cho mục đích trích xuất thông tin từ ảnh văn bản.
Có một vài điểm yếu đối với các phương pháp kể trên. Đầu tiên, chúng dựa vào một lượng ít ỏi các ảnh được đánh nhãn thủ công mà không tận dụng được một lượng dồi dào dữ liệu không có nhãn. Ngoài ra, các phương pháp trên thường sử dụng mô hình CV (thị giác máy) hoặc NLP (xử lý ngôn ngữ tự nhiên) được huấn luyện trước, mà không kết hợp huấn luyện dựa trên thông tin về cả hình ảnh và văn bản.
Để giải quyết các điểm yếu trên, LayoutLM kết hợp thông tin hình ảnh và văn bản ở khâu pre-training (huấn luyện trước), từ đó có được multimodal token representation (đặc trưng hình ảnh và nội dung trích xuất được từ các đối tượng trong ảnh văn bản) chất lượng cao, có thể phục vụ các tác vụ sau này, ví dụ như phân loại văn bản.
2.1. LayoutLM áp dụng cho bài toán phân loại văn bản
Cho trước một ảnh văn bản đầu vào, một hệ thống OCR sẽ khoanh vùng và trích xuất nội dung của từng từ (word) trong văn bản. Các đầu ra của hệ thống OCR sau đo sẽ được mã hóa thành các representation (đặc trưng) bởi LayoutLM. Các đặc trưng này sau đó có thể được dùng cho phân lớp văn bản. Để phục vụ tốt cho bài toán phân lớp, các đặc trưng này được huấn luyện để mang các thông tin về ngữ cảnh, ngữ nghĩa, hình thức, và vị trí của các từ tương ứng.
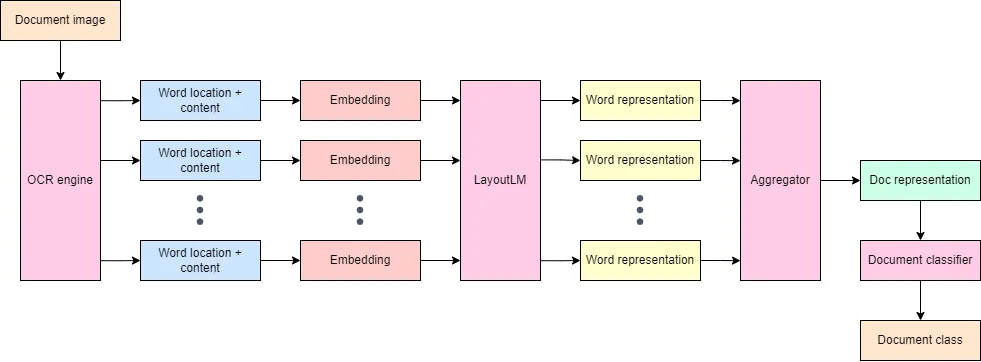
Sau khi có đầu ra của LayoutLM, các đặc trưng của mỗi từ sẽ được kết hợp lại, tạo nên một đặc trưng tổng thể (document representation) cho toàn bộ ảnh văn bản. Đặc trưng tổng thể này sẽ mã hóa nội dung, cấu trúc, và hình thức của văn bản đầu vào. Đặc trưng đó sẽ được đưa qua một thuật toán phân lớp (classification algorithm) đơn giản, như multi-layer perceptron classifier, để phân lớp văn bản.
2.2. Kiến thức nền tảng
Trước khi đào sâu hơn vào LayoutLM, ta sẽ tìm hiểu về cơ chế attention và các kiến trúc liên quan là Transformer và BERT.
Cơ chế attention
Cơ chế attention [3] khởi nguyên từ bài toán dịch máy (neural machine translation). Đây là một cải tiến dựa trên mạng LSTM để giải quyết vấn đề liên quan tới các chuỗi dài của LSTM. Cụ thể, đối với chuỗi đầu vào đủ dài, tín hiệu huấn luyện đối với các lớp neuron tương ứng với các time step đầu tiên sẽ bị tiêu biến, theo thuật ngữ chuyên môn là gradient vanishing problem. Đối với khâu dự đoán, đóng góp của các time step đầu tiên vào đầu ra cuối cùng cũng sẽ bị áp đảo bởi các time step cuối cùng. Nói các khác, thuật toán đã “quên” đầu vào của các time step trước đó.
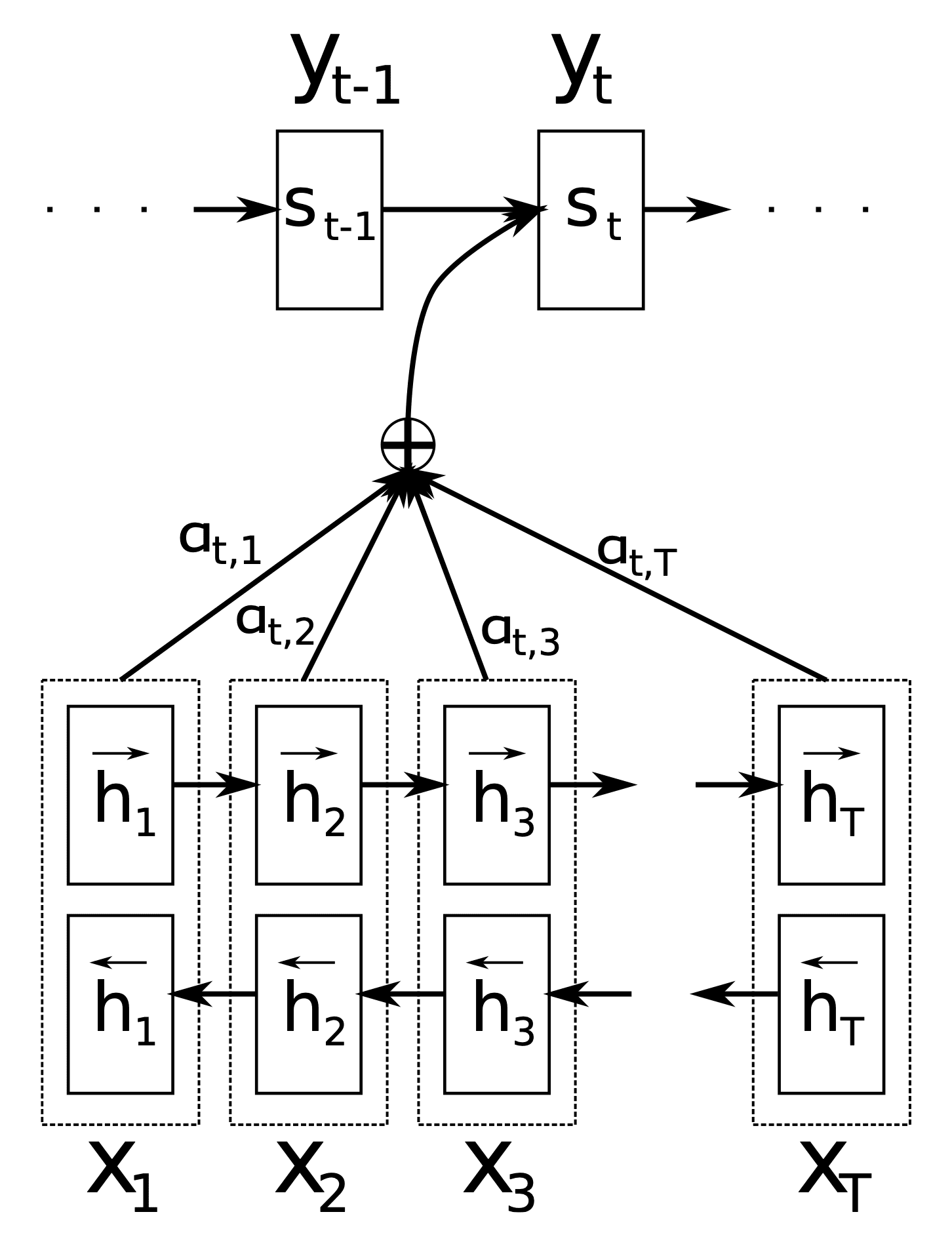
được sử dụng để dự đoán từ tiếp theo (s)
(Nguồn: Bài báo gốc về attention mechanism bởi Badanau và các đồng nghiệp)
Để giải quyết vấn đề trên, ta sẽ lấy trung bình cộng có trọng số của các hidden states được tính toán bởi LSTM ở các time steps khác nhau. Mỗi hidden state sẽ được gán trọng số, gọi là attention score, tương ứng với time step đó. Attention scores sẽ được tính toán dựa trên hidden state của time step hiện tại, và các từ đã được dự đoán trước đó. Chúng phản ánh mức độ tập trung của mô hình vào từng time step trong quá trình dự đoán từ hiện tại.
Chi tiết hơn, đề nghị bạn đọc tham khảo bài báo gốc của Attention mechanism.
Kiến trúc Transformer
Kiến trúc Transformer [4] là một trong những nỗ lực loại bỏ hoàn toàn các mạng RNN truyền thống trong các bài toán time-series. Trong bài báo này, tác giả đề xuất thay thế LSTM bằng self-attention và multi-head attention – hai biến thể của attention mechanism.
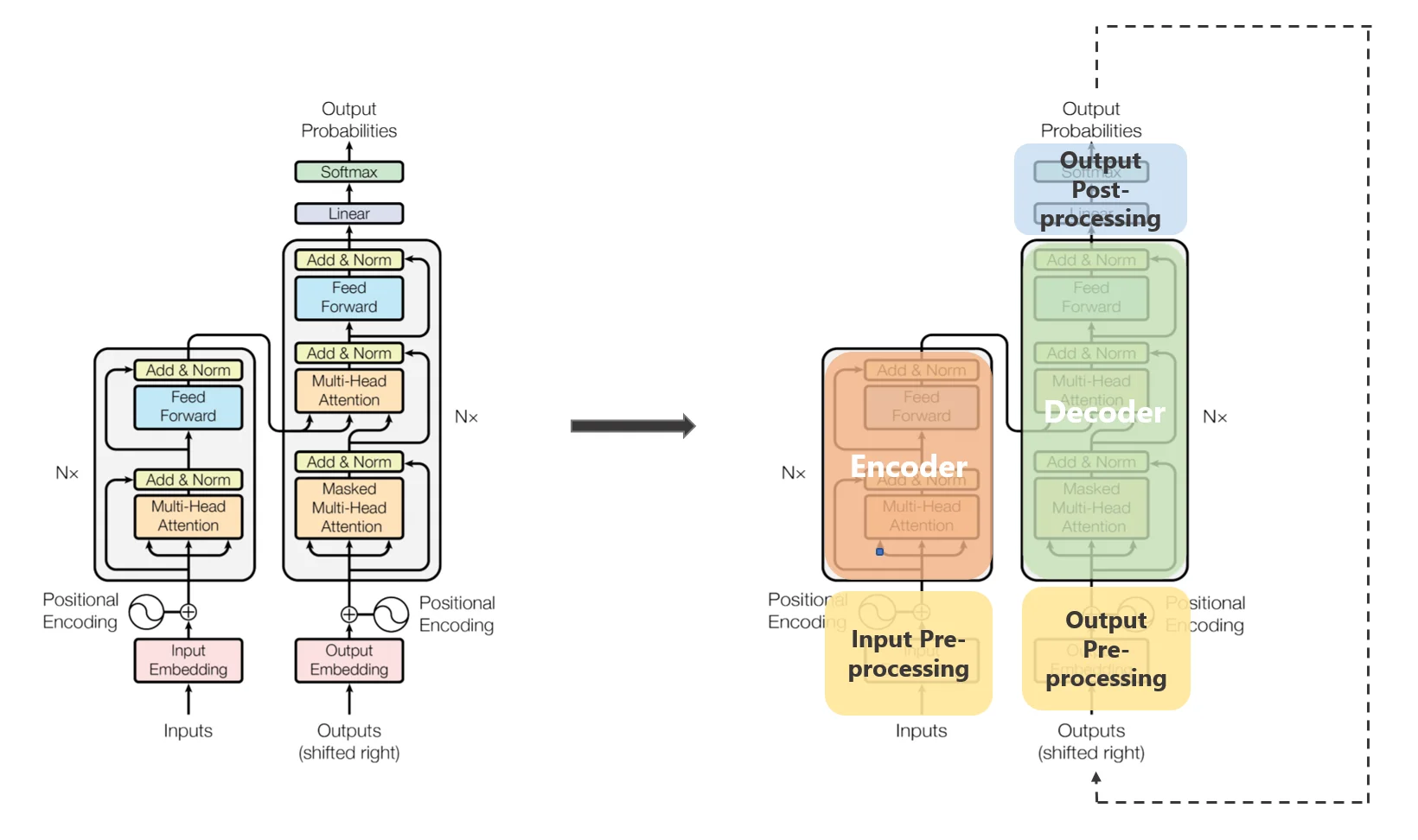
(Nguồn: towardsdatascience)
Kiến trúc tổng quan của Transformer bao gồm một encoder và một decoder, với đầu vào là một chuỗi các tokens (hoặc các words theo ngôn ngữ thông thường). Mỗi token được mã hóa sử dụng các kĩ thuật word embedding, sau đó kết hợp với một position embedding mang thông tin vị trí của token đó trong chuỗi. Chuỗi token đã được mã hóa sẽ được đẩy vào encoder, module phụ trách việc mã hóa sâu hơn các tokens này để trích xuất được các đặc trưng cần thiết. Các đặc trưng này sau đó được đưa vào decoder để phục vụ mục đích dịch máy.
Điểm đặc biệt là không có mô hình RNN truyền thống nào như LSTM được sử dụng trong Transformer. Thay vào đó, cấu trúc trình tự của chuỗi token được mã hóa bởi position embeddings, và ngữ nghĩa của chuỗi được mô hình hóa bởi các modules multi-head attention.
Transformer đã đem lại kết quả vượt trội trên nhiều bài toán khác nhau của lĩnh vực xử lý ngôn ngữ tự nhiên, cũng như các bài toán time-series khác.
BERT
BERT [5] là viết tắt của Bidirectional Encoder Representations from Transformers. Kiến trúc này được đề xuất từ bài báo của J. Devlin và đồng nghiệp năm 2018, trong một nỗ lực nhằm cải tiến các pre-trained language representation (đặc trưng ngôn ngữ) để có thể sử dụng cho các tác vụ ngôn ngữ.
Tính tới thời điểm xuất bản của bài báo, đã có các công trình nghiên cứu về pre-trained language representation như ELMo, hay GPT. Tuy nhiên, các phương pháp này chỉ sử dụng mô hình ngôn ngữ một chiều (unidirectional language models) để học các đặc trưng ngôn ngữ, do đó giới hạn khả năng của các pre-trained representation và cản trở hiệu suất của mô hình.
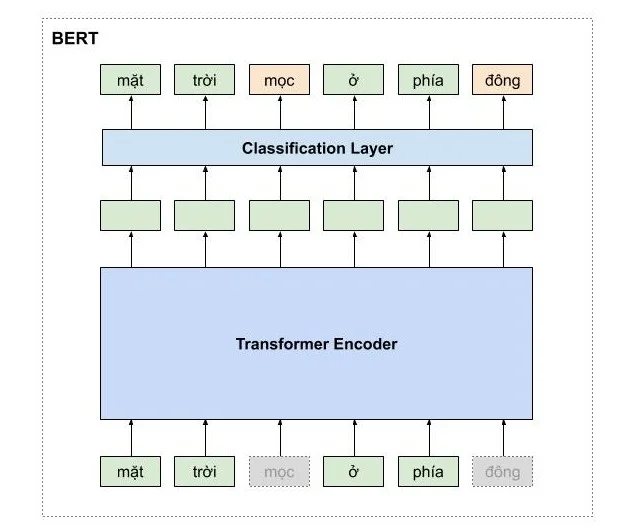
(Nguồn: pbcquoc’s transformer repository)
Bắt nguồn từ các quan sát này, BERT sử dụng các đặc trưng ngôn ngữ hai chiều (bi-directional representations), được tạo ra bằng cách đưa chuỗi token đầu vào qua một chuỗi các Transformer encoder block. Để tăng cường hiệu suất cho các tác vụ phía sau (downstream tasks), tác giả đã tiền huấn luyện BERT với hai bài toán: Masked langauge model (MLM), và Next sentence prediction, nhằm giúp các đặc trưng ngôn ngữ nén được nhiều thông tin ngữ cảnh hơn.
BERT đã đánh bật các phương pháp trước đó trên nhiều bài toán xử lý ngôn ngữ tự nhiên khác nhau. BERT đã mở ra một kỷ nguyên mới trong lĩnh vực học sâu.
LayoutLM
LayoutLM kế thừa kiến trúc của BERT, với các chỉnh sửa trên token embeddings module và các bài toán tiền huấn luyện để phù hợp với bài toán đọc hiểu ảnh văn bản. Cụ thể, đối với dữ liệu ảnh, position embedding cần thể hiện vị trí trong không gian 2 chiều, thay vì 1 chiều như time-series. Ngoài ra, ta cần tích hợp thêm thông tin hình ảnh bên cạnh thông tin văn bản.
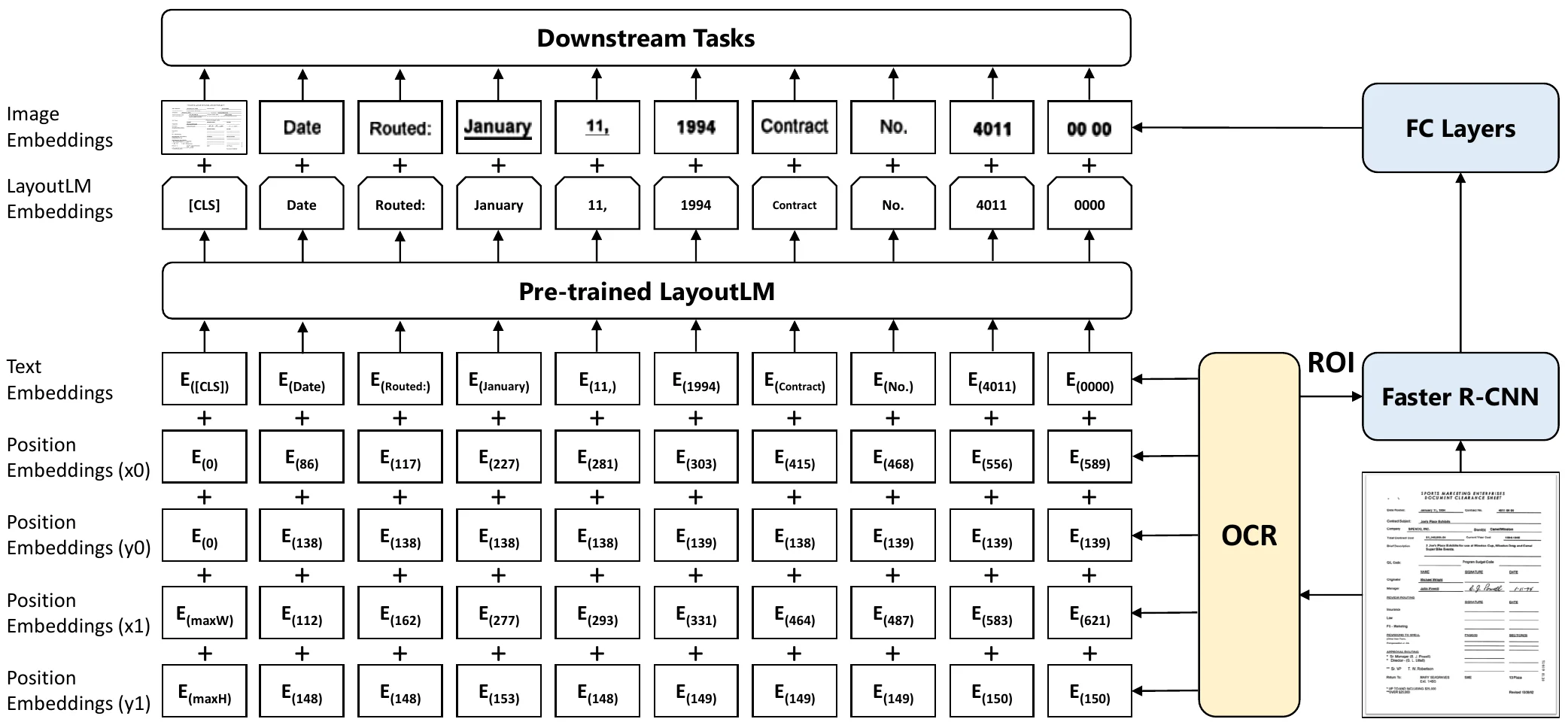
(Nguồn: Bài báo gốc của LayoutLM)
Dựa trên những khác biệt này, LayoutLM kết hợp đặc trưng ngôn ngữ từ BERT với 2D position embedding nhằm mã hóa vị trí tương đối của từng token trong ảnh, cùng đặc trưng ảnh của mỗi token khoanh vùng được trong ảnh. Đặc trưng ảnh mã hóa các thông tin như font chữ, hoặc màu chữ, của từng token.
Đối với tiền huấn luyện, LayoutLM sử dụng Masked visual-language model (MVLM), một biến thể của bài toán MLM, và Multi-label document classification (MDC), chính là bài toán phân lớp văn bản ta quan tâm.
LayoutLMv2
LayoutLMv2 [6] là một cải tiến của LayoutLM, dựa trên quan sát rằng sự kết hợp sâu sắc giữa thông tin văn bản, hình ảnh và bố cục sẽ dẫn đến tương tác đa phương thức tốt hơn, dẫn đến biểu diễn mã thông báo tốt hơn.
Cụ thể, LayoutLM chỉ kết hợp thông tin hình ảnh sau quá trình tiền huấn luyện đặc trưng ngôn ngữ và bố cục. Các tác giả lập luận rằng, theo cách tiếp cận này, kiến thức miền (domain knowledge) của một loại tài liệu không thể dễ dàng chuyển sang một loại tài liệu khác, do đó, các mô hình thường phải huấn luyện lại sau khi loại tài liệu được thay đổi. Trong trường hợp này, sự bất biến cục bộ trong bố cục tài liệu chung, tức là các cặp khóa-giá trị trong bố cục trái-phải, bảng trong bố cục lưới, v.v., không được tận dụng triệt để.
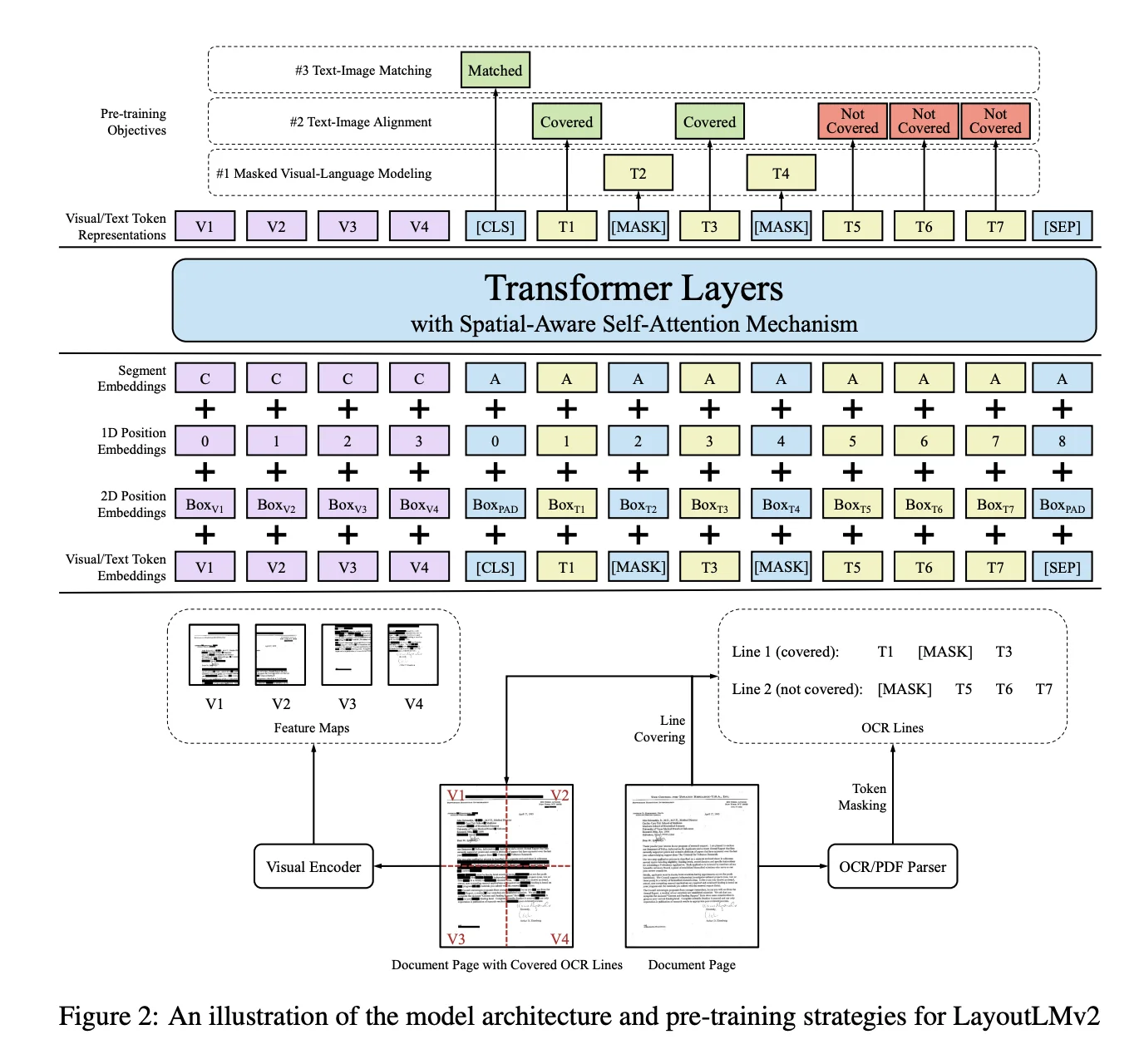
(Nguồn: Bài báo gốc của LayoutLMv2)
Dựa trên quan sát này, LayoutLMv2 tích hợp thông tin hình ảnh ngay từ khâu tiền huấn luyện, tận dụng lợi thế của kiến trúc Transformer để học mối tương quan giữa đặc trưng hình ảnh và đặc trưng văn bản. Để tiền huấn luyện các đặc trưng hình ảnh, hai bài toán được đề xuất cho LayoutLMv2, đó là text-image alignment và text-image matching.
3. Nguồn tham khảo
– [1] A survey of document image classification: problem statement, classifier architecture and performance evaluation – Nawei Chen et. al. (2007)
– [2] LayoutLM: Pre-training of Text and Layout for Document Image Understanding – Yiheng Xu et. al. (2020)
– [3] Neural Machine Translation by Jointly Learning to Align and Translate – Dzmitry Bahdanau et. al. (2016)
– [4] Attention Is All You Need – Ashish Vaswani et. al. (2017)
– [5] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding – Jacob Devlin et. al. (2018)
– [6] LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding – Yang Xu et. al. (2020)


















Bài viết hay quá ạ 😀
[…] Như đã đề cập, trong các văn bản có bố cục phức tạp, việc sử dụng kết hợp giữa cả thông in hình ảnh và thông tin ngữ nghĩa có thể giúp tăng cường hiệu năng của mô hình trích rút thông tin. Các mô hình Transformer có thể tận dụng tối đa sức mạnh của cơ chế tự chú ý để có thể kết hợp hiệu quả các thông tin trong văn bản. Trong đó, mô hình LayoutLM đạt được hiệu năng vượt trội nhờ vào việc huấn luyện trên tập dữ liệu văn bản cực lớn và không cần gán nhãn. Chi tiết về mô hình LayoutLM đã được đề cập trong bài viết Phân loại ảnh văn bản – Document image classification. […]