Bài toán phát hiện bất thường
Bài toán phát hiện dị thường (Anomaly Detection) hay phát hiện điểm ngoại lai (Outlier) là một dạng bài toán tìm những bản ghi, hoặc những điểm quan sát có biểu hiện khác biệt rõ rệt so với phần dữ liệu còn lại hoặc khác với quy luật của dữ liệu bình thường. Những điểm bất thường này thường được gọi là: điểm ngoại lai, nhiễu, sai số hoặc các ngoại lê.
Trong thế giới của hệ thống phân tán và dữ liệu lớn, việc theo dõi và quản lý hệ thống là tối quan trọng. Với hàng trăm đến hàng ngàn bản ghi cần phải theo dõi, việc phát hiện bất thường có thể chỉ ra những chỗ bị sai trong dữ liệu, kiểm soát nhiễu loạn trong hệ thống. Từ đó chúng ta có thể cảnh báo cho các bên liên quan để phân tích nguyên nhân và tìm giải pháp xử lý vấn đề.
1. Vai trò của bài toán
Khi phân tích dữ liệu, các dữ liệu bất thường thường gây ra cản trở việc đưa ra nhận định và dự đoán. Trong nhiều trường hợp, các điểm bất thường thường là dấu hiệu của một sự việc nghiêm trọng đang diễn ra, có thể gây thiệt hại lớn và có thể tốn rất nhiều thời gian công sức để sửa chữa. Chính vì vậy, việc phát hiện bất thường giúp tránh được những rủi ro không đáng có có thể gây thiệt hại lớn về tiền bạc và công sức; đồng thời giúp đưa ra các quyết định chiến lược và phát triển chính xác hơn và hiệu quả hơn. Ví dụ: đơn vị điện lực sẽ theo dõi nhằm phát hiện bất thường trong chỉ số đo đếm của công tơ từ đó xác định công tơ hỏng/lỗi hoặc xác định hành vi trộm cắp điện để tiến hành kiểm tra. Hoặc ngân hàng khi phát hiện bất thường trong giao dịch thẻ tín dụng có thể từ chối giao dịch đó để đảm bảo quyền lợi của khách hàng và giữ được uy tín của ngân hàng. Tóm lại, việc phát hiện và xử lý bất thường đóng vai trò quan trọng trong việc vận hành kinh doanh, nghiệp vụ của các tập đoàn, tổ chức.
Tuy nhiên trong một số trường hợp, việc xuất hiện các bất thường không hẳn đã là một điều gì đó tiêu cực. Có thể đó là dấu hiệu một điều gì đó mới đang xuất hiện và việc phát hiện ra có thể giúp thay đổi nhận định về một vấn đề hoặc giúp chúng ta phát triển những ý tưởng mới. (Một câu chuyện về bất thường dẫn đến phát hiện mới: trong cấu trúc tinh thể, các nhà khoa học vẫn thường cho rằng tinh thể có cấu trúc đối xứng, vì vậy thường bác bỏ những kết quả hay lý thuyết về sự giả tinh thể. Tuy nhiên, nhà khoa học Dan Schetchman đã phát hiện ra cấu trúc giả tinh thể bất thường này của hợp kim Nhôm-Mangan. Ông đã không dám công bố phát hiện của mình trong 2 năm vì sợ phản ứng từ cộng đồng khoa học và đi ngược lại sách vở! Nhưng sau đó, ông đã công bố công trình và đã được nhận giải Nobel năm 2011. Sau này các nhà khoa học đã phát hiện ra nhiều loại cấu trúc giả tinh thể khác [1])
Trong các công ty và tập đoàn về IT, phát hiện bất thường được sử dụng cho các mục đích:
- Làm sạch dữ liệu, loại bỏ các nhiễu động hoặc dữ liệu bị sai: Các dữ liệu thường khó tránh khỏi có nhiễu động hoặc sai sót. Việc phát hiện và sửa chữa các sai sót và nhiễu động này trong khoa học dữ liệu đóng vai trò then chốt trong việc xây dựng và vận hành hệ thống dữ liệu. Xa hơn là nó có thể giúp đưa ra những quyết định và chiến lược dựa trên dữ liệu một cách chính xác và hiệu quả
- Phát hiện xâm nhập từ bên ngoài vào trong hệ thống: Để phát hiện ra những malware, trojans, virus, … xâm nhập vào hệ thống đánh cắp dữ liệu, hoặc xác định một cuộc tấn công mạng vào hệ thống.
- Phát hiện giả mạo: Được áp dụng trong các hệ thống tài chính ngân hàng, dùng để phát hiện những giao dịch lừa đảo giả mạo
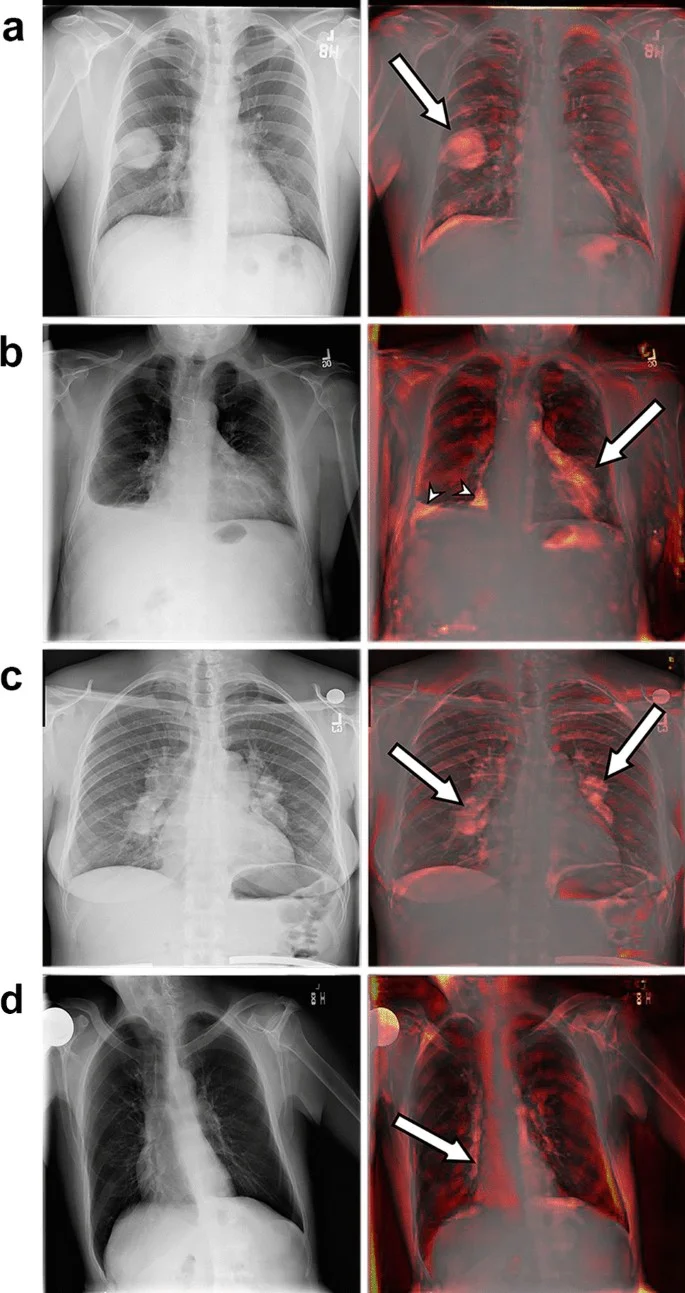
- Phát hiện bất thường trong y tế / chăm sóc sức khỏe: Những hình ảnh hoặc các chỉ số bất thường có thể là dấu hiệu của một bệnh lý hoặc ung thư
- Phát hiện sự cố trong vận hành hệ thống: Khi hệ thống xuất hiện những sự cố ngầm, những khu vực xuất hiện sự cố sẽ có những biểu hiện khác biệt. Các công cụ phát hiện bất thường sẽ xác định những vị trí bị sự cố này, hoặc xa hơn là chỉ ra khả năng đang bị loại sự cố nào
- Trong sản xuất: phát hiện ra những sản phẩm bị lỗi và kiểm tra chất lượng sản phẩm
2. Định nghĩa các loại bất thường
Dữ liệu bất thường thường hay có các dạng bất thường sau đây:
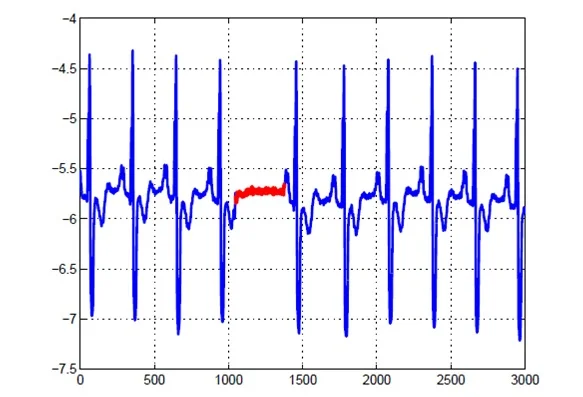
- Bất thường dáng điệu: Trong khuôn khổ một xu hướng dữ liệu được xem xét, những điểm bất thường nằm lệch ra khỏi xu hướng này. Ví dụ như trong hình sau, nhiệt độ tháng 6 có bất thường

- Tập hợp bất thường: Có những tập hợp các điểm dữ liệu khác biệt so với các điểm dữ liệu với các dáng điệu bình thường. Ví dụ như đồ thị sau, phần màu đỏ khác biệt so với quy luật của phần còn lại, có dấu hiệu bất thường và ta cần xem xét kĩ tập hợp điểm này.
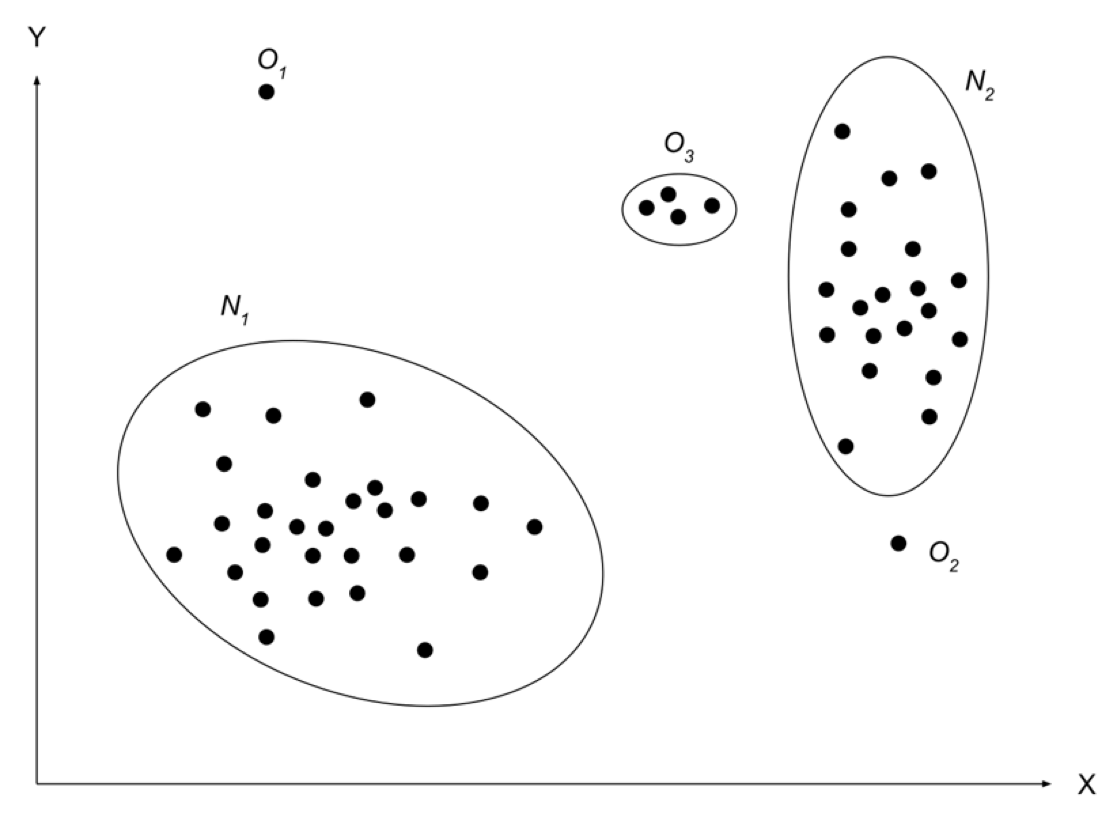
- Bất thường điểm hoặc bất thường toàn cục: Những điểm dữ liệu bất thường nằm lệch ra khỏi các tập hợp dữ liệu bình thường. Ví dụ điểm O1 và điểm O2 là bất thường điểm.
3. Phương pháp xác định bất thường
Việc xác định các loại bất thường có thể dùng đến những phương pháp sau đây:
3.1. Phương pháp giám sát (Supervised Learning)
Ý tưởng chính: Dùng mô hình phân loại cho các điểm bình thường và bất thường đã được đánh nhãn, và dùng mô hình này để phân loại những dữ liệu mới chưa được phân loại. Các mô hình phân loại này có thể xử lý tốt trong những trường hợp tỉ lệ bất thường / bình thường bị lệch lớn.
Kỹ thuật này đòi hỏi phải có hiểu biết cả về dữ liệu bình thường và bất thường để có thể xây dựng mô hình phân loại để phân biệt các điểm bình thường và bất thường.
Có các loại phương pháp giám sát chính:
- Theo bộ quy tắc đã có (rule-based): Tùy vào kinh nghiệm và nghiệp vụ của lĩnh vực cần triển khai bài toán phát hiện bất thường, một bộ các quy tắc và điều kiện có thể được dựng nên để phát hiện ra bất thường. Cách làm này có nhược điểm là nếu có những bất thường không nằm trong khuôn khổ quy tắc thì không phát hiện ra được, và bộ quy tắc này phải được thường xuyên cập nhật. Hơn nữa, trong nhiều trường hợp, các phương pháp rule-based thường có hiệu quả không cao.
- Theo mô hình mạng neuron (Neural Network): Mô hình Neural network / học sâu tương đối phổ biến trong các bài toán sử dụng máy học và phân loại.
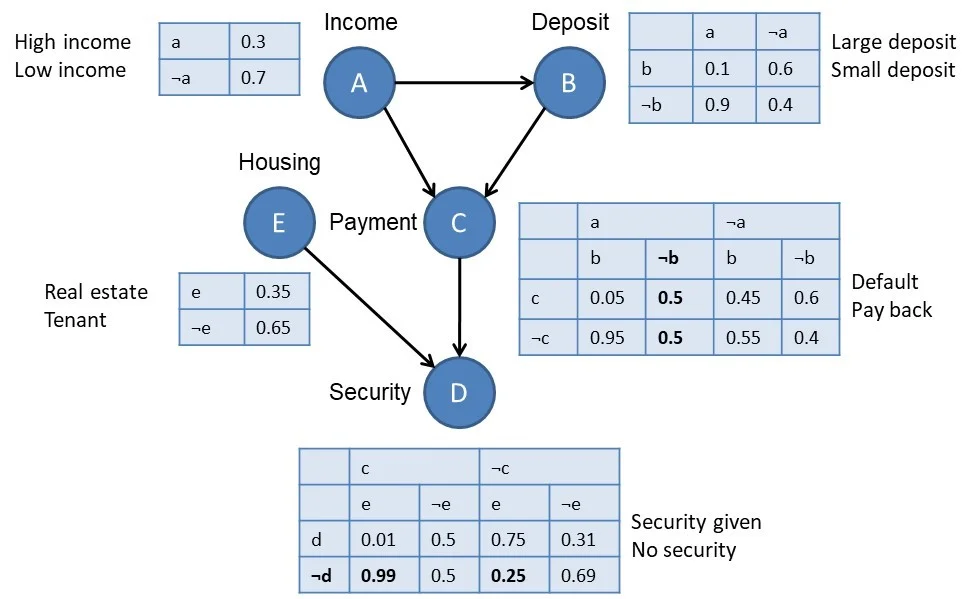
- Mạng Bayesian (Bayesian network): Đây là mô hình xác suất tường minh, thường được mô tả là một đồ thị G (thường là đồ thị không có chu trình và có hướng), chứa các node và đường mô tả sự phụ thuộc giữa các tham biến với nhau, và sự phụ thuộc giữa các tham biến được mô tả định lượng bởi phân bố xác suất có điều kiện giữa chúng. Ví dụ đồ thị sau mô tả mối quan hệ giữa các biến a (thu nhập), b (khoản vay), c (thanh toán), d (mức độ an toàn) và e (vay bất động sản hoặc vay khác)
- Các thuật toán phân loại, chẳng hạn SVM, RandomForest, …
3.2. Phương pháp không giám sát (Unsupervised Learning)
Đây là phương pháp thông dụng nhất để xác định bất thường. Ta không cần phải đánh nhãn để xác định bất thường khi xây dựng mô hình. Nhược điểm của phương pháp này là không phân biệt được những dữ liệu nào mới là bất thường thực sự, và có thể bắt cả những dữ liệu không bất thường. Kỹ thuật này nhìn chung sẽ có kết quả không chính xác bằng các phương pháp có giám sát.
Phương pháp xác định bất thường không giám sát dùng các phương pháp sau:
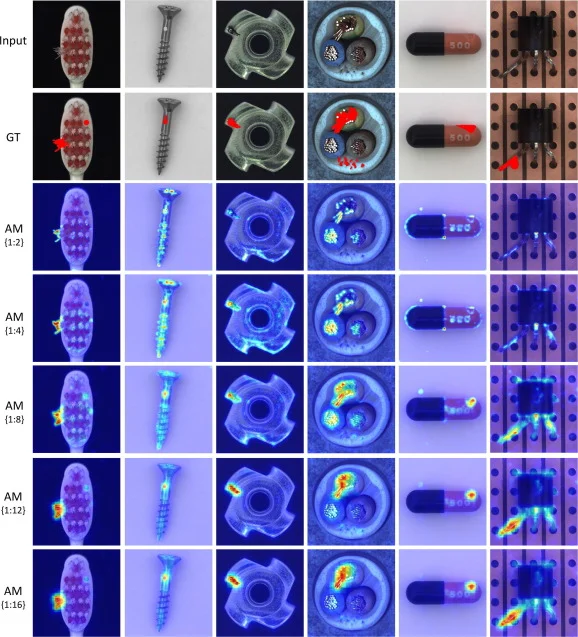
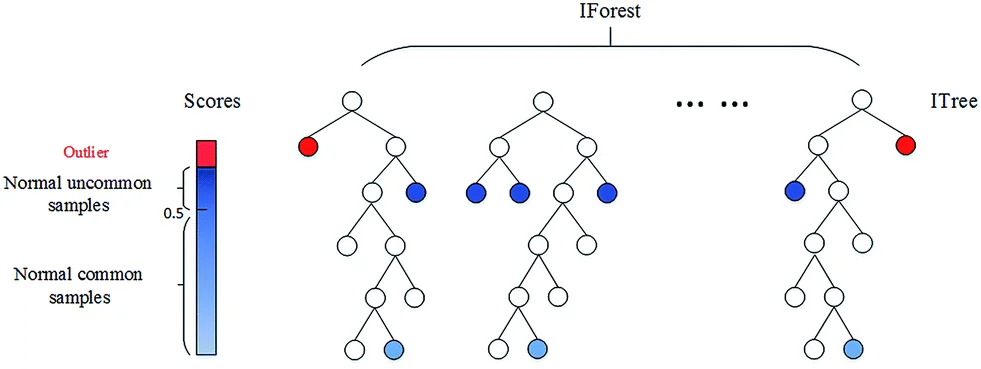
- Rừng cô lập: Dựa vào thuật toán Random Forest, một Isolation Forest sẽ xử lý những tập hợp nhỏ dữ liệu được lấy mẫu ngẫu nhiên theo dạng cây dựa theo một bộ tham biến ngẫu nhiên. Các mẫu dữ liệu sâu hơn ở trong cây sẽ ít có khả năng là bất thường bởi vì chúng cần nhiều lần cắt hơn từ cây. Tương tự như vậy, từ những nhánh ngắn hơn sẽ phát hiện ra được những điểm bất thường, do cây có thể phân biệt chúng dễ dàng
- Local Outlier Factor (thừa số bất thường địa phương): Sự lệch khỏi phân bố địa phương của một điểm dữ liệu nào đó so với những dữ liệu lân cận là dấu hiệu cho thấy sự bất thường. Thuật toán này xác định mẫu bất thường dựa vào mật độ thấp hơn rõ rệt so với mật độ các dữ liệu lân cận của chúng

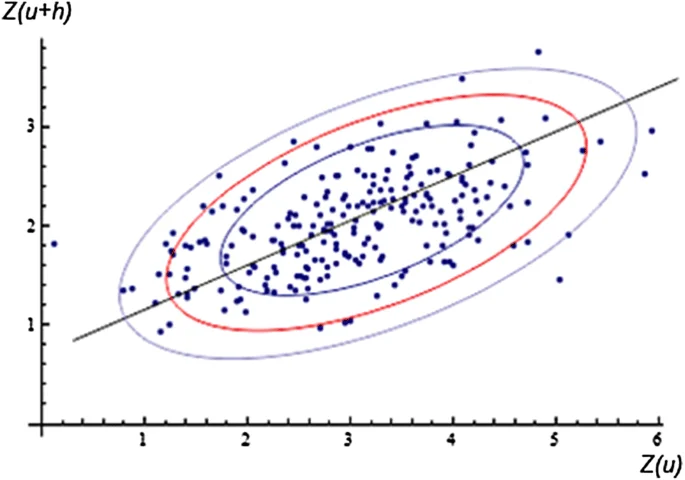
- Khoảng cách Mahalanobis: Đây là một phương pháp đơn giản, và rất hiệu quả trong các bài toán phát hiện bất thường mà chỉ có 1 loại dữ liệu và dữ liệu bị mất cân bằng lớn. Khoảng cách Mahalanobis của các điểm dữ liệu từ điểm trung tâm có thể được vẽ như hình dưới đây. Các điểm có khoảng cách Mahalanobis càng lớn thì càng có khả năng là các điểm bất thường
- Auto-encoders:
- Auto-encoder là một mô hình mô tả mạng neuron theo dạng đặc trưng của neural network đấy. Sau khi được huấn luyện mô hình, mỗi một điểm của dữ liệu sẽ được đặc trưng bởi một bộ biến số trong không gian encode. Cách hành xử của dữ liệu bình thường có thể được mô tả thông qua các tham biến trong không gian encode này. Nếu có điểm dữ liệu bất thường, thì bộ tham biến trong không gian encode không thể encode điểm đấy được, dẫn đến việc xây dựng lại điểm dữ liệu đó không chính xác, giúp ta xác định bất thường trong mô hình.
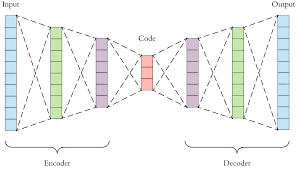
- Ứng dụng của VAE (Variational Auto Encoder) trong việc phân tích hình ảnh chụp não để phát hiện khối u bất thường [1]

- Phân cụm K-means:
Thuật toán k-means dựa trên ý chính như sau: 1/ Chọn K điểm bất kỳ làm các tâm ban đầu. 2/ Phân mỗi điểm dữ liệu vào cluster có tâm gần nó nhất. 3/ Cập nhật tâm cho từng cluster bằng cách lấy trung bình cộng của tất các các điểm dữ liệu đã được gán vào cluster đó sau bước 2. Ta lặp lại bước này đến khi việc gán dữ liệu vào từng cluster không thay đổi so với vòng lặp trước nó thì ta dừng.
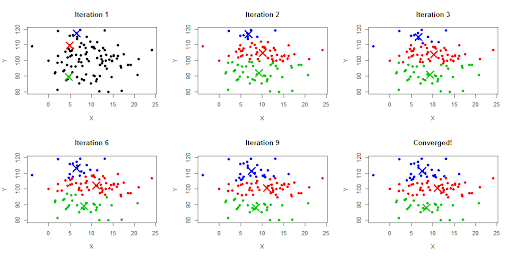
Để sử dụng k-means phát hiện bất thường, ta có thể biểu diễn phân bố của các khoảng cách từ các điểm tới tâm trên 1 histograms, và sử dụng phương pháp tính z-scores để phát hiện bất thường (hoặc các phương pháp phát hiện bất thường khác sử dụng thống kê như Inner Quantile Range)
3.3. Phương pháp bán giám sát (Semi-supervised learning)
Là sự kết hợp giữa hai phương pháp giám sát và không giám sát. Trong đó phần dữ liệu được lọc ra bởi kỹ thuật không giám sát sẽ do các chuyên gia (các kỹ thuật viên, nhân viên) sẽ giám sát để chỉnh lại những điểm bất thường / không bất thường, vì vậy mà phương pháp này tương đối chính xác. Phương pháp này cần hiểu biết về dữ liệu bình thường để có thể đưa ra mô hình học các cách hành xử của dữ liệu bình thường, bất kỳ dữ liệu nào vượt ngoài ngưỡng của những dữ liệu bình thường sẽ được xem là bất thường.
4. Phát hiện bất thường giao dịch thẻ tín dụng với Brightics AI
Để minh họa cho bài toán phát hiện bất thường, chúng tôi sẽ sử dụng bộ dữ liệu giao dịch thẻ tín dụng trên Kaggle:
Bộ dữ liệu chứa các giao dịch được thực hiện bằng thẻ tín dụng vào 2 ngày trong tháng 9 năm 2013 bởi chủ thẻ ở Châu Âu. Trong đó có 492 vụ gian lận được phát hiện trong tổng số 284.807 giao dịch. Có thể thấy đây là bộ dữ liệu rất mất cân bằng, do số lượng giao dịch lừa đảo chỉ chiếm 0,172% trong tất cả các giao dịch.
Do vấn đề bảo mật nên Kaggle không tiết lộ bộ dữ liệu gốc, mà sử dụng biến đổi PCA để đưa ra 28 biến mới là: V1, V2, … V28 (đây là các thành phần chính có được sau biến đổi PCA). Ngoài ra, biến ‘Time’ và ‘Amount’ không qua biến đổi. Biến ‘Thời gian’ thể hiện số giây đã trôi qua giữa mỗi giao dịch so với giao dịch đầu tiên trong tập dữ liệu. Biến ‘Amount’ là số tiền giao dịch. Biến cần dữ đoán là biến “Class”, nhận giá trị 1 trong trường hợp gian lận hoặc 0 nếu ngược lại.
Đặc biệt, trong bài viết này chúng tôi sử dụng Brightics AI để khai phá và xây dựng mô hình dự đoán cho tập dữ liệu này. Brightics AI, được xây dựng bởi Samsung, là nền tảng phân tích dữ liệu đã trở nên rất quen thuôc trong cộng đồng làm dữ liệu tại Hàn Quốc. Nó cung cấp rất nhiều function (hàm) có sẵn cho phép người dùng làm việc trọn vẹn với dữ liệu từ: khai phá dữ liệu (EDA), trích chọn đặc trưng (feature engineering), huấn luyện & kiểm định mô hình, trực quan hóa và xuất báo cáo, vv Ngoài ra, brightics có bản Brightics Studio miễn phí (ít chức năng hơn Brightics AI), bạn có thể tải Brightics Studio để dùng thử tại link sau: https://github.com/brightics/studio/releases/tag/v1.2-2021.09
4.1. Phân tích khai phá dữ liệu (EDA)
Chúng ta cùng xem qua một vài bản ghi trong tập dữ liệu credit card:

Cùng nhìn qua một số đặc trưng của dữ liệu bằng cách sử dụng hàm Profile Table :
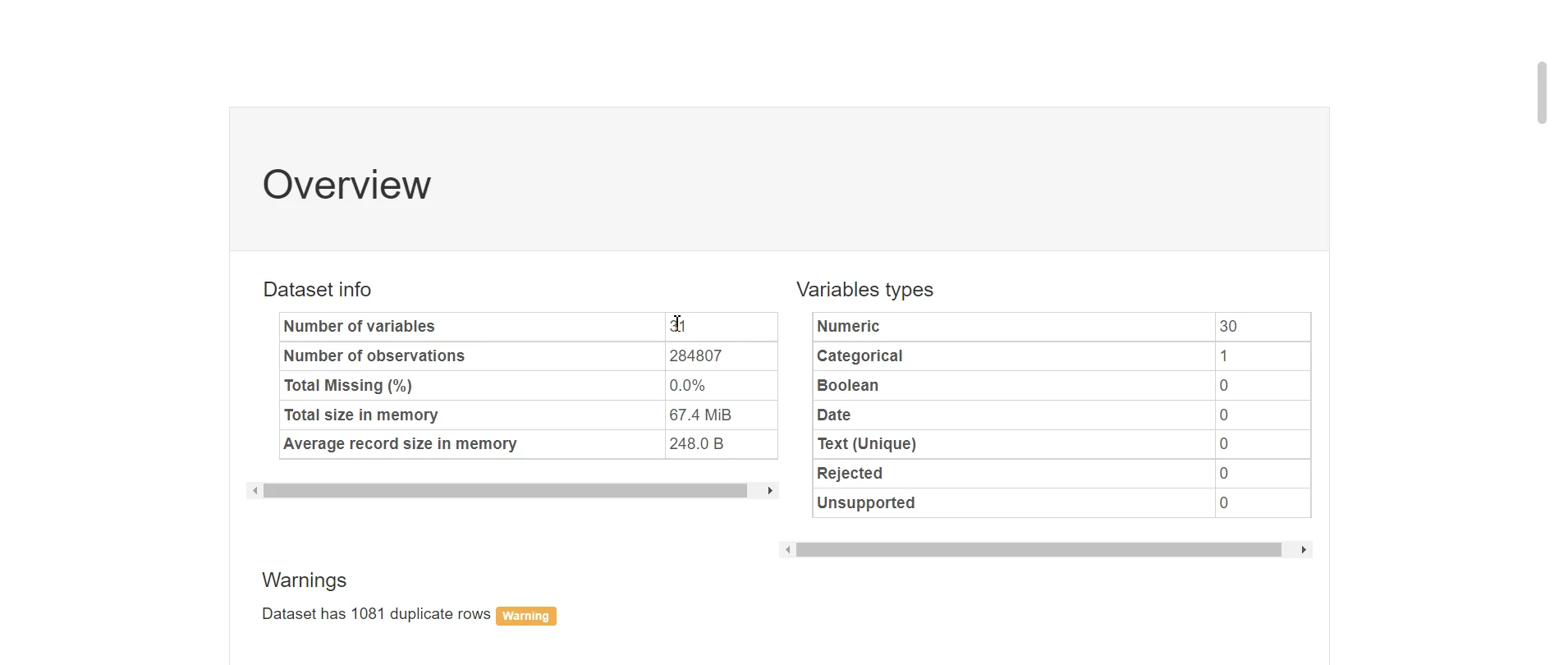
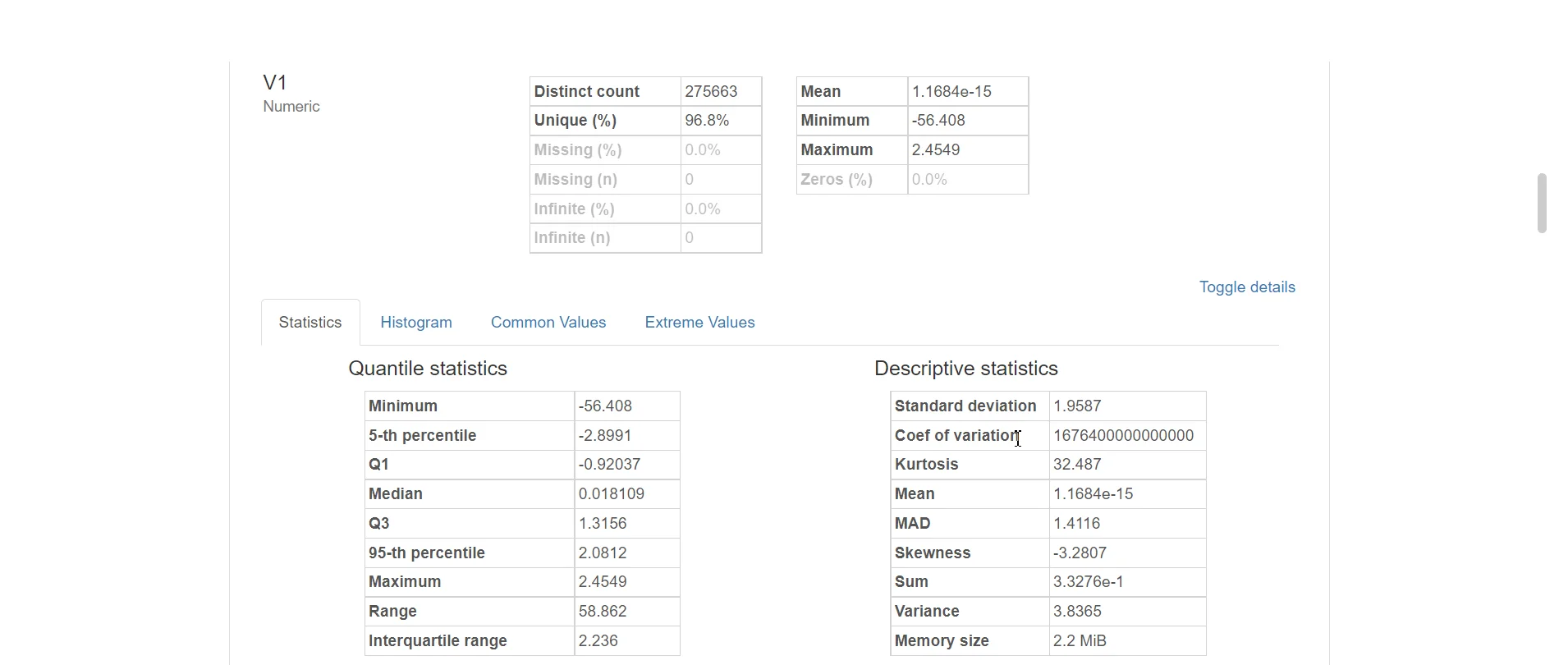
Dữ liệu đã được chuẩn hóa nên không gặp trình trạng thiếu dữ liệu (missing value). Ta có thể xem cụ thể thông tin của từng biến một, ví dụ như biến V1 sau đây:
4.2. Lựa chọn feature (Feature selection)
Vì số lượng biến trong bộ dữ liệu khá nhiều nên chúng ta sẽ cần xem liệu có biến nào không giúp phân biệt giao dịch bình thường & gian lận thì chúng ta sẽ loại ra trước khi đưa vào mô hình. Chúng ta sẽ sử dụng kiểm định p-value. so sánh giữa 2 class. Giả thuyết của kiểm định này là:
Ho: là trung bình tổng thể (theo một biến nào đó: V1, V2,..) của hai nhóm bất thường và bình thường là bằng nhau; tức là biến đang xét không giúp phân biệt giao dịch bất thường.
H1: là trung bình 2 tổng thể khác nhau.
Độ tin cậy: 95%. Mức ý nghĩa 0.05
Thực hiện kiểm định này với tất cả các biến, kết quả trả về như sau:
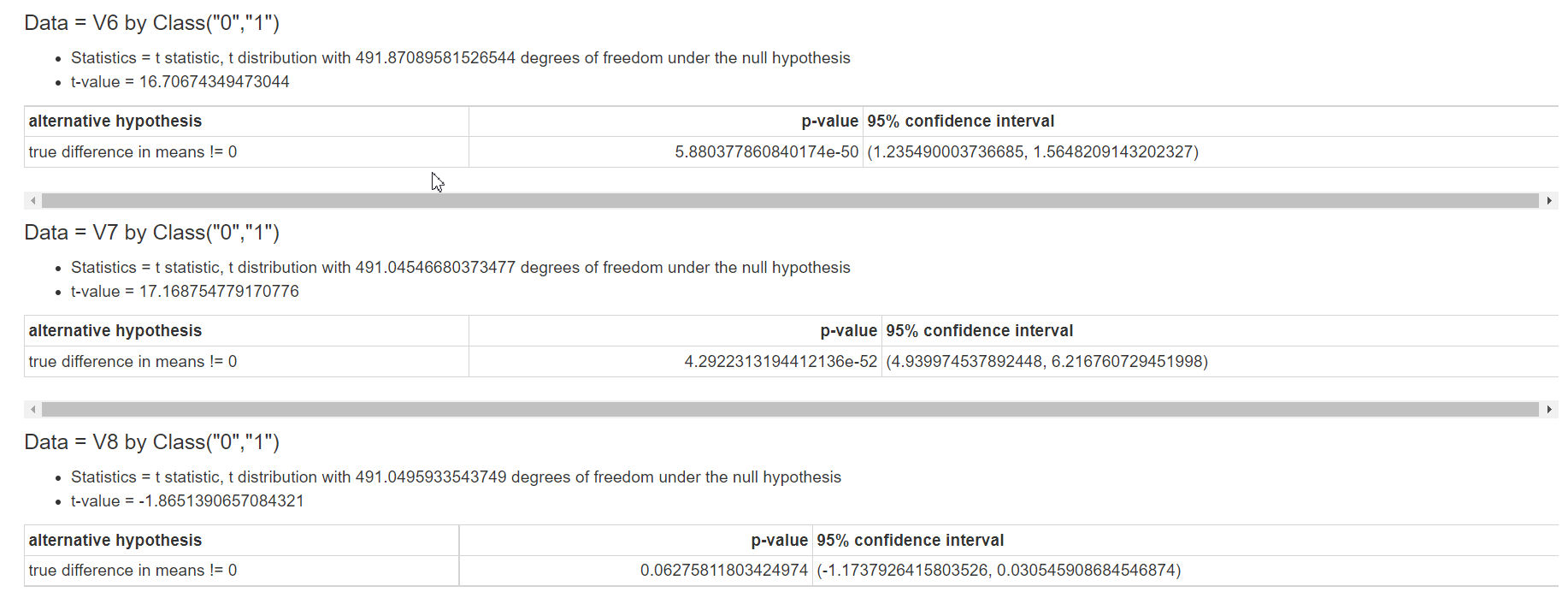
VD với kết quả trên:
+ Biến V6, V7 có p-value <<< 0.05 => bác bỏ H0, công nhận H1. 2 biến này có ý nghĩa thống kê giúp phân biệt 2 loại giao dịch
+ Biến V8, p-value xấp xỉ 0.06 > mức ý nghĩa => không đủ cơ sở để bác bỏ H0. Vậy ta công nhận H0 với độ tin cậy 95%. Vậy biến V8 không giúp phân biệt 2 loại giao dịch nên ta sẽ loại biến này ra.
Lần lượt xem kết quả của từng biến, ta sẽ loại được các biến V8, V15, V22, V23, V25, V26.
4.3 Thí nghiệm một số mô hình và so sánh kết quả
(1) Mô hình có giám sát
Chia tập dữ liệu thành bộ huấn luyện và bộ kiểm định theo tỷ lệ 7:3. Brightics cung cấp sẵn các hàm để chia dữ liệu, huấn luyện mô hình và đánh giá mô hình. Ở đây chúng tôi sẽ thử nghiệm với 2 mô hình là Random Forest và XGBoost. Kết quả của hai mô hình như sau:

Kết quả của mô hình Random Forest
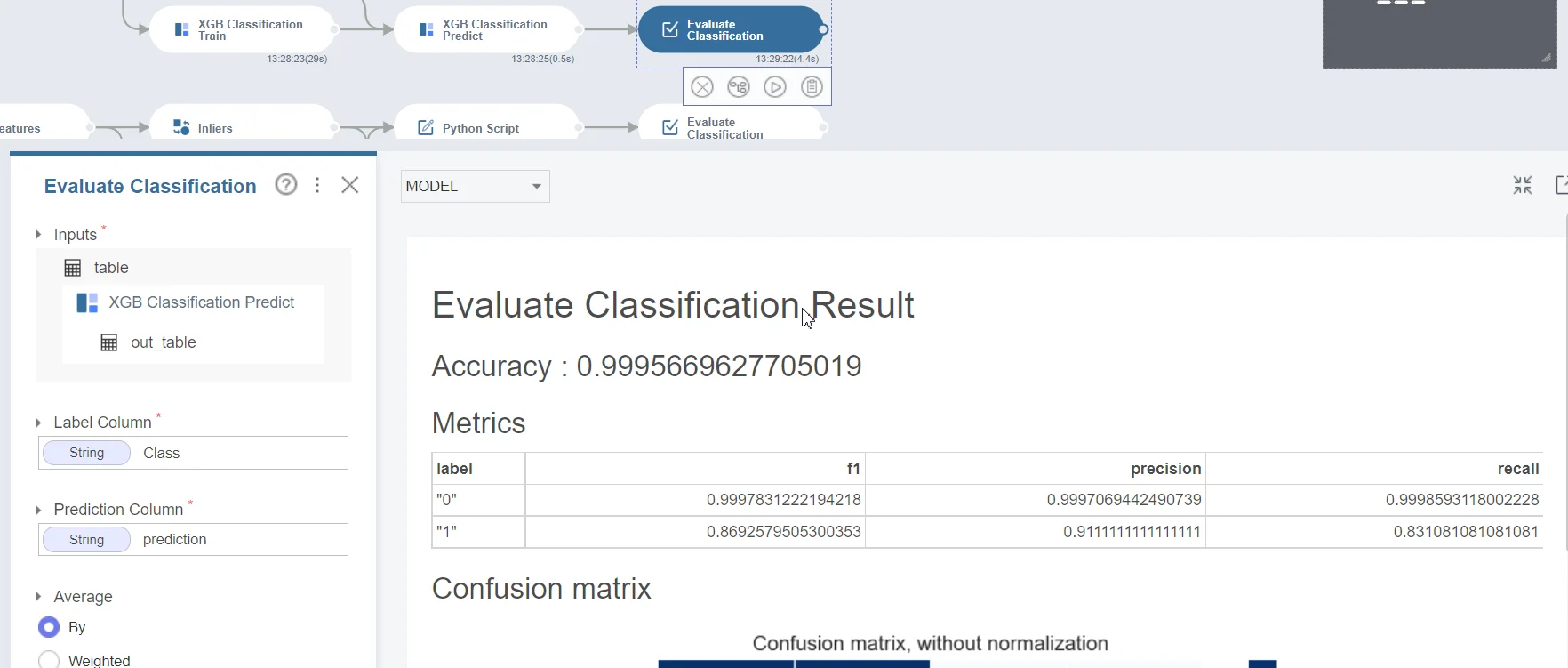
Kết quả mô hình XGBoost
(2) Mô hình không giám sát
Chúng tôi sẽ sử dụng mô hình Isolation Forest hai lần với dữ liệu thuộc nhóm bình thường và dữ liệu thuộc nhóm bất thường
Kết quả như sau:
- Độ chính xác của nhóm giao dịch bình thường: 0.89999 (tức là có 89,99% giao dịch bình thường được mô hình khoanh vùng vào nhóm bình thường, còn lại mô hình nhận diện là điểm bất thường)
- Độ chính xác khi chạy mô hình với nhóm giao dịch gian lận: 0,9024 (tức là có 90,24% giao dịch bất thường được mô hình nhận diện là giao dịch bất thường)
(3) Kết luận: Nhìn chung, kết quả khi sử dụng Isolation Forest sẽ kém hơn 2 mô hình có giám sát bên trên
Cùng nhìn lại toàn bộ luồng làm việc của Brightics. Tổng thời gian chạy toàn bộ luồng, từ hàm tải dữ liệu đến khi có kết quả của các mô hình là 2 phút.
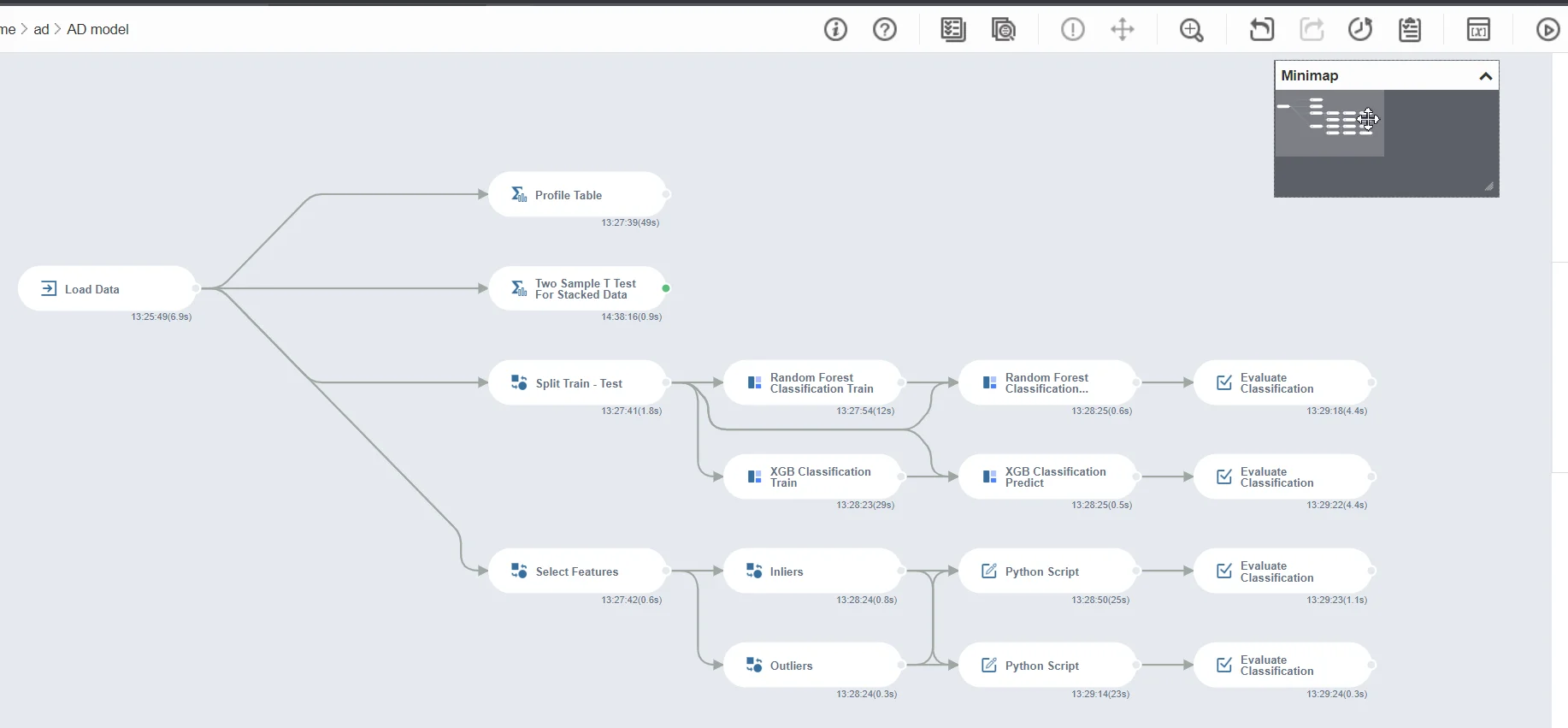
Trong thực tế, nếu được huấn luyện đầy đủ, mô hình có giám sát luôn trả về kết quả có độ chính xác cao hơn là mô hình không giám sát. Tuy nhiên, nếu tình hình dữ liệu không cho phép, mô hình không giám sát nên được áp dụng, sau đó áp dụng mô hình có giám sát sau khi có thêm dữ liệu đầy đủ.
Tài liệu tham khảo:
1: https://en.wikipedia.org/wiki/Quasicrystal
2: Unsupervised Brain Anomaly Detection and Segmentation with Transformers
Walter Hugo Lopez Pinaya, Petru-Daniel Tudosiu, Robert Gray, Geraint Rees, Parashkev Nachev, Sebastien Ourselin, M. Jorge Cardoso