Giới thiệu về Ceph – Giải pháp lưu trữ trên Cloud
1. Giới thiệu Ceph
Cùng với sự phát triển mạnh mẽ của công nghệ điện toán đám mây (Cloud), các giải pháp quản lý lưu trữ cũng tiến hóa không ngừng để đáp ứng các yêu cầu mới. Các hệ thống lưu trữ trên các nền tảng điện toán đám mây hiện đại đòi hỏi cần phải đáp ứng được các tiêu chí cơ bản sau:
- Quản lý các hạ tầng phần cứng lưu trữ đa dạng từ nhiều nhà cung cấp khác nhau
- Dễ dàng thay đổi quy mô hệ thống tùy thuộc vào yêu cầu sử dụng
- Quản lý các hạ tầng lưu trữ phân tán
- Linh hoạt, mềm dẻo trong việc cung cấp các dịch vụ lưu trữ với loại hình, dung lượng, hiệu năng khác nhau tùy thuộc theo nhu cầu của khách hàng.
- Cung cấp được dịch vụ lưu trữ đảm bảo tính sẵn sàng và an toàn dữ liệu theo nhiều cấp độ khác nhau
- Chi phí thiết bị, quản lý, vận hành hợp lý
Các giải pháp truyền thống đơn thuần dựa trên các hệ thống phần cứng đặc thù của các hãng sản xuất thiết bị lưu trữ nên khó có thể đáp ứng đầy đủ được các yêu cầu trên. Do đó, những giải pháp lưu trữ dựa trên phần mềm (Software Defined Storage SDS) với khả năng linh hoạt, mêm dẻo dễ dàng hơn trong việc giải quyết các yêu cầu của những hệ thống lưu trữ phục vụ cho các nền tảng cloud hiện đại. Các hệ thống sử dụng SDS sử dụng một lớp trừu tượng để quản lý các hạ tầng phần cứng vật lý ở bên dưới, từ đó có thể đảm bảo được khả năng quản lý mềm dẻo trong việc cung cấp các dịch vụ lưu trữ cho các nền tảng điện toán đám mây
Một trong những giải pháp quản lý lưu trữ dựa trên SDS được ứng dụng rất phổ biến trong các nền tảng Cloud là Ceph. Ceph cung cấp một nền tảng mã nguồn mở thực hiện giải pháp quản lý tài nguyên lưu trữ toàn diện, mạnh mẽ và linh hoạt. Các mục tiêu cơ bản của Ceph bao gồm:
- Quản lý đa dạng các hạ tầng lưu trữ phân tán
- Khả năng mở rộng không giới hạn
- Quản lý bằng phần mềm (SDS)
- Khả năng chịu lỗi
- Hiệu năng cao
- Mã nguồn mở
Chúng ta sẽ cùng tìm hiểu sơ lược về kiến trúc tổng quan và cơ chế hoạt động cơ bản của Ceph.
2. Kiến trúc Ceph

Kiến trúc của Ceph được chia thành 3 tầng chính:
- Ceph Storage Cluster (lớp dưới cùng): đây là tầng quản lý toàn bộ các thiết bị lưu trữ của một hệ thống Ceph dựa trên RADOS (Reliable Autonomic Distributed Object Store). Toàn bộ các dữ liệu của Ceph đều được tổ chức lưu trữ dưới dạng đối tượng. RADOS cung cấp khả năng lưu trữ tin cậy, quản lý được các phần cứng lưu trữ không đồng nhất và phân tán, với phạm vi mở rộng không giới hạn. Ceph Storage Cluster bao gồm nhiều tiến trình phần mềm được triển khai trên các node mà nó quản lý. Các tiến trình này được chia thành các loại chính sau:
- OSD – Object Storage Daemon
- MON – Monitor Daemon
- MDS – Metadata Server
- MRG – Management Daemon
- Thư viện librados : thư viện cung cấp các API giao tiếp trực tiếp với RADOS
- Interface (RBD, RADOS GW, CEPH FS): cung cấp dịch vụ lưu trữ phổ biến được sử dụng trên các nền tảng cloud bao gồm block, file, object
Sau đây, cùng xem xét từng tầng trong kiến trúc Ceph.
- Ceph Storage Cluster:
- OSD: Object Storage Daemon là các tiến trình quản lý các thiết bị lưu trữ trong hệ thống Ceph. Thông thường một OSD process sẽ quản lý một thiết bị lưu trữ vật lý (1 physical disk hoặc 1 volume trong storage device được exposed cho host). OSD trực tiếp thực hiện các tác vụ đọc ghi dữ liệu, tạo các replicas, tái cân bằng, khôi phục dữ liệu. OSD sẽ giao tiếp với OSD khác và cung cấp thông tin cho các tiến trình MON và MRG. Trong một hệ thống Ceph cần tối thiểu 3 OSD để đảm bảo tính sẵn sàng và an toàn dữ liệu
- MON: Monitor Daemons là các tiến trình quan trọng trong việc thực hiện các hoạt động của RADOS. MON lưu trữ toàn bộ các thông tin để có thể truy cập đến đúng dữ liệu theo yêu cầu. MON lưu trữ các Cluster Map, bao gồm các loại map sau:
- Monitor Map: lưu thông tin node trong cluster, địa chỉ, port của tiến trình monitor. Map này lưu thông tin khi khởi tạo và các thay đổi
- OSD Map: OSD Map lưu danh sách pool, replica size, số lượng PG, danh sách các OSD cùng trạng thái. OSD Map lưu khi khởi tạo và các trạng thái thay đổi
- PG Map: PG version và timestamp, OSD map hiện tại, full ratio (tỉ lệ sử dụng của các OSD) và chi tiết của các PG như PG ID, trạng thái, số liệu thống kê hoạt động của pool trong PG
- CRUSH Map: lưu cấu trúc của các thiết bị lưu trữ (device, host, rack, row, room) và các quy tắc để thực hiện thao tác dữ liệu trên cấu trúc các thiết bị lưu trữ. Ceph sử dụng CRUSH Map nhận biết trạng thái của các thành phần trong cluster để đảm bảo nhân bản dữ liệu khi có các thành phần trong hệ thống bị lỗi.

- Thư viện librados: đây là một thư viện viết bằng ngôn ngữ C, cho phép client giao tiếp trực tiếp với RADOS. Tất các các truy cập đến RADOS đều thông qua thư viện librados, gồm cả tầng interface hoặc các ứng dụng khác không sử dụng interface sẵn có của Ceph. Thư viện này hỗ trợ nhiều ngôn ngữ lập trình phổ biến C++, Java, Python, Ruby, and PHP.
- Interface:
- RBD: Rados Block Device cung cấp dịch vụ lưu trữ dưới dạng các thiết bị block. Đây là hình thức lưu trữ cơ bản khi dữ liệu được chia vào các block (512 bytes). Các thiết bị lưu trữ vật lý như HDD, SSD cũng thường lưu trữ data dạng thô theo hình thức này. RDG dựa trên nền tàng lưu trữ đối tượng của Ceph Storage Cluster để cung cấp các block device cho các client.
Mỗi Block Device có thể lưu trữ trên một hoặc nhiều object của tầng Ceph Storage Cluster. Sử dụng các tính năng thừa hưởng từ RADOS, các block device có khả năng resizeble, thin-provision, clone, snapshot.
Về phía client, Ceph hỗ trợ ánh xạ các block device vào các kernel object đối với các hệ thống Linux hoặc sử dụng librdb cho các hệ thống QEMU/KVM.

RADOS GW: là proxy cung cấp các API đang HTTP restful để xây dựng các dịch vụ lưu trữ đối tượng. Do nền tảng Ceph đã quản lý tất cả các dữ liệu dưới dạng object nên RADOS GW chỉ cung cấp các API để truy cập, quản lý đối tượng như tổ chức bucket, đọc, ghi, xóa object….. Các API tương thích AWS S3 hoặc Openstack Swift. Một object S3 hoặc Swift có thể sử dụng một hoặc nhiều object của tầng Ceph Storage Cluster để lưu trữ. RADOS GW cũng giao tiếp với Ceph Storage Cluster thông librados.

- CEPH FS : Ceph File System cung cấp dịch vụ file system tương thích POSIX. Dịch vụ file system dựa trên nền tảng của Ceph Storage Cluster bên dưới thông qua thư viện librados. CephFS libary cung cấp các tính năng của file system. Về phía client, Ceph hỗ trợ :
- Object Kernel Linux cho các hệ thống Linux thông thường
- CephFS FUSE cho Filesystem Userspace(FUSE)
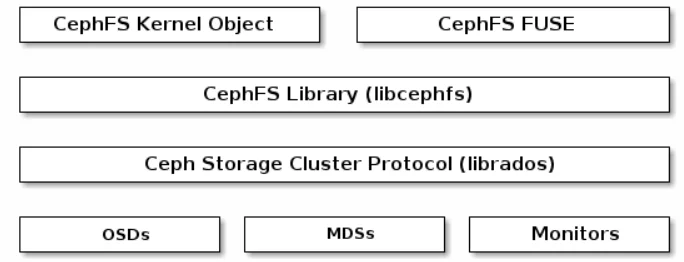
Client có thể mount Ceph File System như một Kernel Object hoặc một Filesystem Userspace(FUSE).
Trong tầng Ceph Storage Cluster, các MDS chỉ phục vụ cho dịch vụ Ceph File System như đã trình bày ở trên. Các MSD lưu trữ các thông tin của các file system như cấu trúc thư muc, chế độ truy cập của từng thư mục hoặc file …
Mỗi file trong CephFS có thể được lưu trữ trên một hoặc nhiều object của tầng Ceph Storage Cluster.
3. Cơ chế hoạt động
- Tổ chức dữ liệu trong Ceph
- Đơn vị lưu trữ cơ bản trong Ceph là Object. Mỗi Object có một identity(ID), dữ liệu và metadata lưu dưới dạng label/value. Mỗi object được lưu trong OSD


- Mỗi OSD tương ứng với một đơn vị lưu trữ vật lý (disk) hoặc logic(LUN). Các OSD đảm nhiệm việc đọc, ghi và replication object. Hiện tại, Ceph có hai loại OSD là FileStore và BlueStore. FileStore lưu trữ mỗi object như một file trong hệ thống file mức kernel như Btrfs and XFS. Tuy nhiên, FileStore gặp nhiều vấn đề về hiệu năng nên trong các phiên bản, Ceph sử dụng loại OSD BlueStore. BlueStore có 2 đặc điểm cơ bản:
- Truy cập trực tiếp mức raw data của các thiết bị lưu trữ(thay vì qua filesystem)
- Lưu trữ các metadata của object trong CSDL key/value RockDB riêng biệt

Các yêu cầu đọc ghi từ client chỉ được thực hiện trên primary OSD, các replica sẽ được primary OSD thực hiện trên các secondary OSD

Ceph hỗ trợ quản lý theo pool. Một Pool là tập hợp logic các object. Pool được lưu trữ tại nhiều PG,một PG thì chỉ được sử dụng lưu trữ cho một pool. Để truy cập object cần có thông tin Object ID và Pool ID. Thông tin PG là nội tại của Ceph và có thể tính toán được từ Object ID và Pool ID.
Cơ chế truy cập dữ liệu

- Để đảm bảo tính sẵn sàng và khả năng mở rộng, Ceph sử dụng thuật toán CRUSH để truy xuất đến các dữ liệu. Theo mô hình truyền thống, client cần phải truy cập thông qua một gateway tập trung như một điểm vào duy nhất, tạo ra nút thắt trong hệ thống làm giảm hiệu năng cũng như khả năng mở rộng. Ceph loại bỏ các điểm truy cập tập trung này và cho phép các client truy cập trực tiếp đến các OSDs (primary). Các OSD sẽ tạo các replica trên các node khác nhau để đảm bảo tính HA và an toàn dữ liệu.
Để thực hiện điều này, Ceph duy trì các MON Daemon để quản lý các Maps của toàn bộ Ceph Storage Cluster(gồm 5 Maps đã trình bày trên phần Kiến trúc). Các map này là bản đồ chỉ dẫn cách truy cập đến các dữ liệu cần thiết. Do tầm quan trong của MON Daemon nên thường được triển khai dạng cluster trên nhiều node để đảm bảo tính HA.
- Ceph sử dụng thuật CRUSH (Control Replica Under Scalable Hashing) để truy cập đến các dữ liệu được lưu trữ. Cả client và OSD Daemons sẽ cùng sử dụng CRUSH để tính toán thông tin vị trí của các object thay vì truy cập đến cổng tập trung.
- Khi thực hiện yêu cầu truy cập dữ liệu Client sẽ lấy thông tin Cluster Map từ MON Daemon. Dựa trên thông tin Cluster Map, Client sẽ truy cập trực tiếp đến OSD lưu trữ object. Nếu là các dịch vụ Ceph FS thì có thể sử dụng thêm MDS để lấy thông tin MDS map. Trên mỗi OSD sẽ kết nối MON Daemon để lấy thông tin Cluster Map để thực hiện các thao tác trên các bản replica.

Cơ chế mapping để truy cập object như sau:

Mỗi Object thuộc về một PG. PG được map với OSD thông qua CRUSH. Khi Client cần thao tác với một object, Client gửi Object ID, Pool ID đến RADOS. Dựa trên Pool ID và Object ID, RADOS thực hiện hashing để tìm ra PG ID.
Dựa trên PG ID và PG Map, CRUSH MAP, CRUSH tìm ra OSD (primary) lưu trữ Object. Sau đó Client sẽ kết nối trực tiếp đến OSD tìm được để đọc ghi trên object tương ứng.
Reference:
https://docs.ceph.com/en/latest/
https://ubuntu.com/ceph/docs
https://access.redhat.com/documentation/en-us/red_hat_ceph_storage/6/html/architecture_guide/index
https://github.com/ceph/ceph