Tối ưu điện năng tiêu thụ trong Data center nhờ OpenStack
Nhu cầu lưu trữ và tính toán ngày càng tăng đã thúc đẩy sự phát triển của các trung tâm dữ liệu (data center – DC). Năng lượng tiêu thụ trong các DC đang tăng trưởng chóng mặt trong những năm gần đây. Số lượng DC gia tăng dẫn đến áp lực tối ưu tài nguyên và giảm thiểu các ảnh hưởng tiêu cực đến môi trường.
Cho dù là bạn đang chỉ xem series “Squid Game” trên Netflix hay đăng một status trên Facebook cũng đều gây ra một phản ứng dây chuyền và gây tiêu hao năng lượng. Việc tiêu hao này không chỉ xảy ra trên các thiết bị cá nhân mà còn ở các trung tâm dữ liệu nằm rải rác trên thế giới, nơi thông tin được lưu trữ. Ngày nay, gần như tất cả lưu lượng IP trên thế giới đều đi qua các DC. Nó không chỉ được truyền một lần. “Đối với mỗi bit dữ liệu đi qua mạng lưới internet từ DC đến người dùng cuối, 5 bit dữ liệu khác được truyền trong và giữa các DC”.
Việc thực hiện tìm kiếm trên Google sẽ chẳng thấm vào đâu nếu so với những hóa đơn tiền điện khổng lồ đằng sau điện toán đám mây, trí tuệ nhân tạo (AI), sự gia tăng của mạng di động 5G, xe tự lái hay khai thác tiền điện tử. Báo cáo cho biết chỉ riêng các dịch vụ phát trực tuyến có thể chiếm 87% lưu lượng truy cập internet của người tiêu dùng trong năm nay. Không có gì ngạc nhiên khi chỉ có một số ít công ty đứng sau tỷ lệ sử dụng điện này. Đứng đầu danh sách là những gã khổng lồ công nghệ lớn của Mỹ như Amazon, Microsoft và Google, cũng như Alibaba ở Trung Quốc. Xếp sau họ là Facebook và Apple.
Nhu cầu lớn về DC
Đầu tiên, DC là gì? Nó chắc chắn không phải là những tủ quá nóng ở phía sau văn phòng với một hoặc hai máy chủ ồn ào. Chúng thường là những tòa nhà hình hộp không có gì đặc biệt được xây dựng đặc biệt với hàng dãy máy móc chuyên dụng lưu trữ, xử lý và gửi dữ liệu đến người dùng. Các trung tâm dữ liệu có thể quy mô từ nhỏ cho một tổ chức cá nhân đến xử lý lưu lượng truy cập cho các tập đoàn toàn cầu như Amazon với hàng trăm triệu người tiêu dùng và dữ liệu sản phẩm.
DC đang mọc lên ở nhiều nơi hơn do số hóa tăng lên và nhiều quy định hơn. Đồng thời, nhiều doanh nghiệp đang loại bỏ các máy chủ tại chỗ của riêng họ và thuê không gian trên các máy chủ đám mây để tập trung vào hoạt động kinh doanh cốt lõi của họ mà không phải lo lắng về các vấn đề CNTT. Trong nhiều trường hợp, chi phí mua và bảo trì thiết bị đó cho các công ty bên ngoài sẽ rẻ hơn và hiệu quả hơn. Không có gì ngạc nhiên khi nhiều DC là trung tâm dữ liệu được chia sẻ bởi người dùng và được quản lý bởi các công ty chuyên môn.
Tại sao DC lại sử dụng nhiều năng lượng như vậy?
Hiện tại có 7,2 triệu DC trên thế giới, theo văn phòng thống kê Đức. Cho đến nay, Mỹ có 2.670, nhiều nhất. Tiếp theo là Anh với 452, Đức với 443, Trung Quốc, Hà Lan, Úc, Canada, Pháp và Nhật Bản.
DC cần điện, rất nhiều, để chạy các thiết bị của họ. Ngoài ra, điện cũng cần để giữ cho cả hệ thống vận hành tốt và luôn mát mẻ. Hiện tại, nhiều chuyên gia ước tính rằng chỉ riêng việc lưu trữ và truyền dữ liệu giữa các DC đã sử dụng 1% điện năng toàn cầu. Một nghiên cứu của Ủy ban EU năm 2020 cho thấy các DC tại 28 quốc gia của khối đã sử dụng 53,9 terawatt giờ vào năm 2010. Con số này đã tăng lên 76,8 terawatt giờ vào năm 2018, chiếm 2,7% tổng nhu cầu điện của EU. Nghiên cứu dự kiến mức tiêu thụ sẽ đạt 3,2% tổng nhu cầu vào năm 2030.
Cho đến nay, phần cứng hiệu quả hơn và những đổi mới trong các tòa nhà vật lý và hệ thống làm mát đã có thể bù đắp nhu cầu điện ngày càng tăng. Tuy nhiên, nghiên cứu lo ngại rằng nhu cầu hiện nay quá mạnh, đến mức tăng trưởng không còn có thể được bù đắp bằng hiệu quả phần cứng hoặc cơ sở hạ tầng.
Giải pháp nào cho thực trạng trên?
Các DC lớn không chỉ trở nên hiệu quả hơn mà chúng còn được sử dụng nhiều hơn. Nhiều nhu cầu gần đây về DC là từ các công ty đã từng lưu trữ các hệ thống nội bộ của riêng họ. Việc chuyển nhiều hệ thống nhỏ, kém hiệu quả sang các DC lớn đã mang lại hiệu quả rõ rệt. Tuy nhiên, một khi phần lớn các công ty đã thực hiện động thái này, việc kiểm soát việc sử dụng năng lượng sẽ khó hơn vì các tùy chọn để tối ưu hóa bị giảm đi.
Rất nhiều các giải pháp đã được các ông lớn trên thế giới áp dụng, từ việc sử dụng năng lượng tái tạo, đặt DC ở các khu vực thời tiết lạnh đến việc áp dụng các công nghệ carbon thấp. Mặc dù thực tế là hai thập kỷ qua đã chứng kiến những tiến bộ đáng kể về giảm thiểu sự kém hiệu quả trong sử dụng điện, nhưng có những dấu hiệu cho thấy điều này có thể sắp kết thúc. Cứ sau 1,5 năm, theo Định luật Moore, hiệu suất trên mỗi watt của CPU tăng gấp đôi. Tuy nhiên, có thể lợi ích lớn như vậy sẽ không có tác dụng vì thiết bị trong các DC sẽ không được thay thế thường xuyên. Các hạn chế vật lý của các chip ngày càng nhỏ sẽ ngày càng khó vượt qua.
Với mong muốn góp phần giải quyết vấn đề về tiêu thụ năng lượng điện, nhóm nghiên cứu thuộc SDSRV chúng tôi đã phát triển 1 giải pháp lập lịch (scheduling) hiệu quả hơn và thử nghiệm trên nền tảng OpenStack. Chúng tôi cũng đã thực hiện một số bài test để chứng minh, bằng việc áp dụng giải pháp này, OpenStack sẽ có khả năng tự động sắp xếp và phân phối các máy ảo một cách thông minh hơn, qua đó giúp DC phục vụ được workload lớn hơn với cùng một lượng tài nguyên cố định. Mời các bạn cùng tìm hiểu chi tiết.
OpenStack là gì?
OpenStack là một hệ thống quản lý đám mây dùng để điều khiển các nguồn tài nguyên tính toán, lưu trữ và mạng trong trung tâm dữ liệu. Tất cả các tác vụ quản lý được thực hiện qua việc gọi các APIs với những cơ chế xác thực thông dụng. OpenStack cũng cung cấp một bảng điều khiển với giao diện web cho phép quản trị viên cấp quyền cấp phát tài nguyên cho người dùng.
Bên ngoài những tính năng tiêu chuẩn của infrastructure-as-a-service, OpenStack cung cấp những tính năng khác như quản lý lỗi, quản lý dịch vụ,… bên cạnh những dịch vụ khác để đảm bảo sự ổn định cao cho người dùng.
Các thành phần chính của OpenStack
OpenStack được chia thành các dịch vụ nhỏ cho phép người dùng có thể linh hoạt sử dụng các thành phần này dựa trên nhu cầu sử dụng thực tế. Hơn thế, OpenStack cung cấp một bản đồ biển diễn các dịch vụ cũng như mối liên hệ giữa các dịch vụ với nhau; từ đó người dùng sẽ dễ dàng lựa chọn các dịch vụ phù hợp với nhu cầu thực tế.
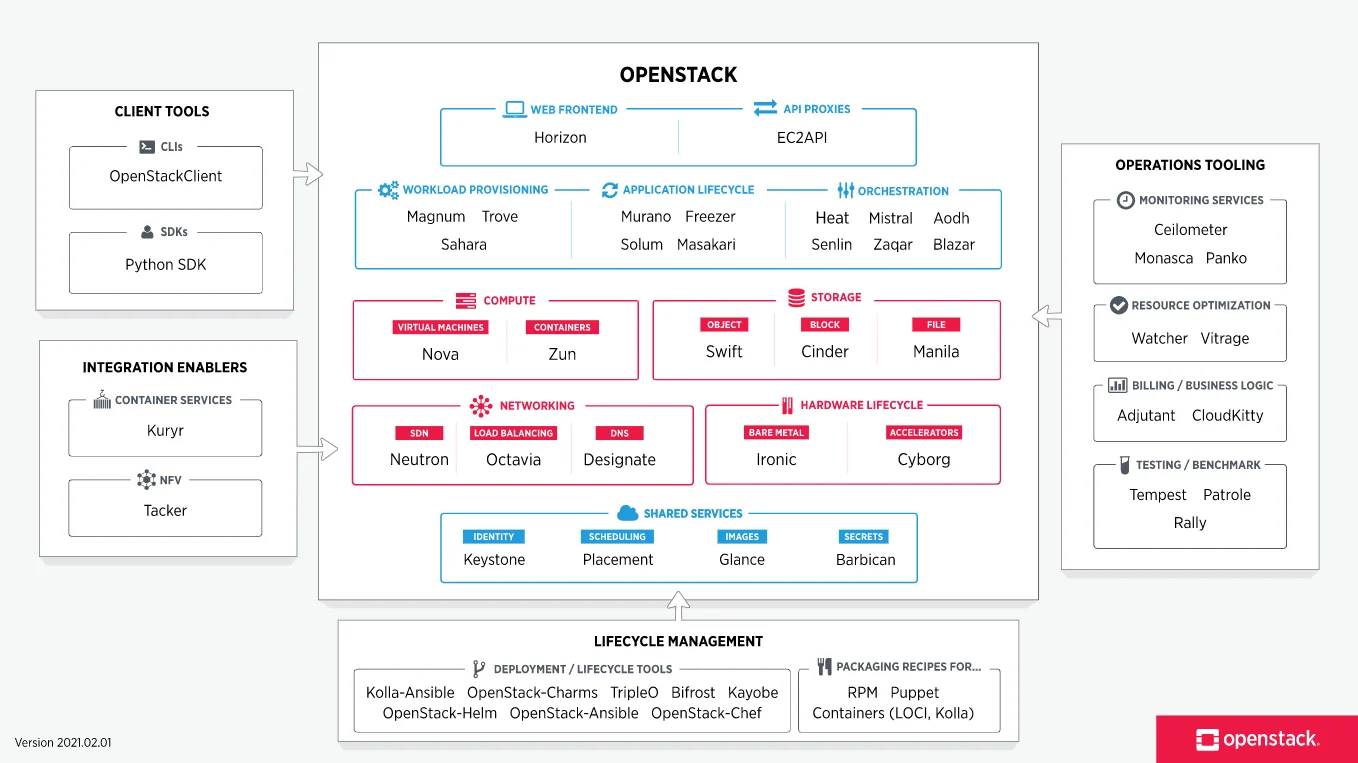
OpenStack bao gồm các thành phần chính sau:
Compute (Nova)
Compute được sử dụng để quản lý các tài nguyên trong môi trường ảo. Compute cũng có nhiệm vụ quản lý các máy ảo mới được triển khai và các máy ảo đang thực hiện các tác vụ tính toán.
Object Storage (Swift)
Được dùng để lưu trữ và backup dữ liệu trong trung tâm dữ liệu. Với Swift, ta có thể lưu trữ nhiều kiểu dữ liệu: văn bản, đối tượng, backup, ảnh, video, máy ảo và các loại dữ liệu không cấu trúc khác. Người phát triển có thể chỉ rõ vị trí OpenStack sẽ lưu trữ dữ liệu bằng cách sử dụng một loại chỉ định đặc biệt.
Block Storage (Cinder)
Block storage hoạt động theo cách truyền thống của thêm/bớt bộ nhớ ngoài cho hệ điều hành với mục đích sử dụng cục bộ. Cinder quản lý việc thêm, bớt, tạo thêm không gian nhớ trong server. Nói theo cách khác, block storage cung cấp bộ môi trường lưu trữ ảo cho máy ảo trong hệ thống.
Networking (Neutron)
Thành phần này được sử dụng như hệ thống mạng trong hệ thống. Neutron quản lý tất cả các truy vấn liên quan đến mạng như quản lý địa chỉ IP, router, subnet, tường lửa, VPNs,…. Neuron đảm bảo rằng tất cả các thành phần trong OpenStack được kết nối với nhau.
Dashboard (Horizon)
Horizon là có giao diện web được người dùng sử dụng để truy cập tới các dịch vụ back-end khác. Thông qua những API, những người phát triển có thể truy cập các thành phần của OpenStack; tuy nhiên thông qua dashboard, người vận hành hệ thống có thể thấy được những gì đang diễn ra trong hệ thống cũng như điều chỉnh chúng theo nhu cầu.
Identity Service (Keystone)
Keystone quản lý người dùng và quyền của người dùng trong việc sử dụng các dịch vụ của OpenStack. Keystone được sử dụng để quản lý các dịch vụ định danh như quyền, xác thực, đăng nhập,…
Image Service (Glance)
Được sử dụng để cung cấp các image service cho OpenStack. Những image service lưu ở glance sẽ được dùng như template khi người dùng triển khai máy ảo mới.
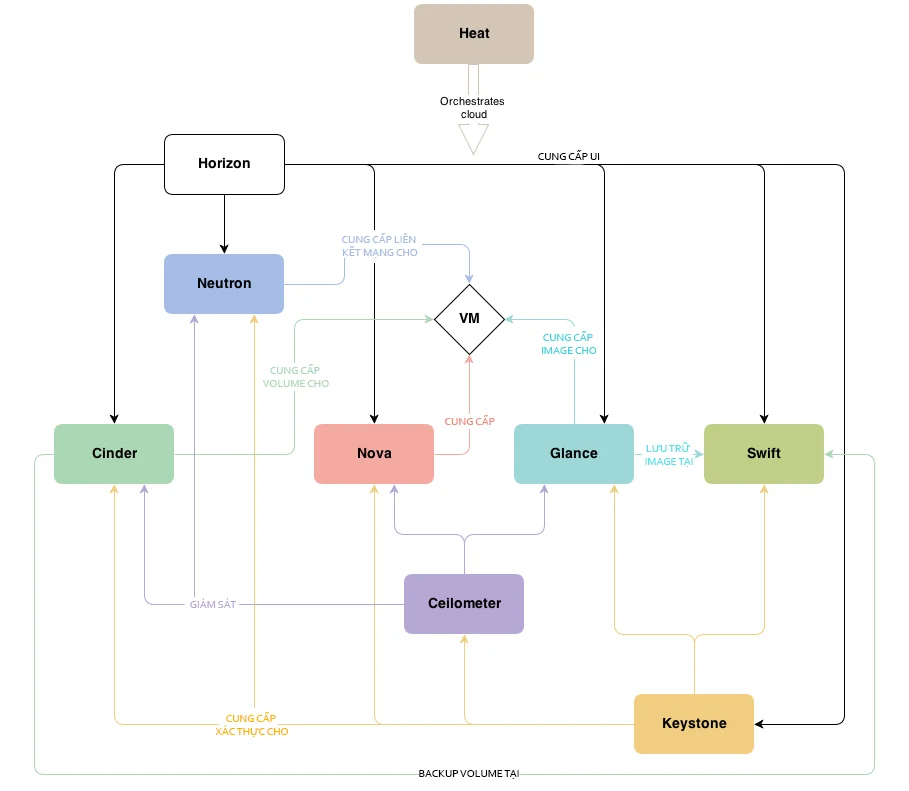
Kiến trúc tổng quan của OpenStack được chia thành 3 tầng
- Tầng ứng dụng (Your Application) : Các ứng dụng/phần mềm sử dụng OpenStack
- Tầng Hypervisor (Standard Hardware) : Phần cứng máy chủ đã được ảo hóa để chia sẻ cho người dùng.
- Dịch vụ OpenStack (Openstack Shared Services) : Các thành phần cơ bản như Dashboard, Compute, Networking, API, Storage.
Cài đặt và cấu hình OpenStack
Trong dự án của chúng tôi, OpenStack được dùng để mô phỏng một trung tâm dữ liệu được tạo thành từ nhiều máy tính vật lý. Trung tâm dữ liệu này bao gồm những dịch vụ rất phổ biến như: Horizon, Nova, Cinder, Neutron, và các dịch vụ chung (shared services) – Keystone, Placement, Glance…
Phiên bản OpenStack được sử dụng là “Yoga”. Cách thức cài đặt được cung cấp đầy đủ tại: https://docs.openstack.org/yoga/install/. Hệ thống thử nghiệm bao gồm 04 máy ảo (node) được cài đặt trên nền tảng VirtualBox. Thông số cụ thể như sau:
Physical computer
CPU: Intel Core i9-9900k 16 cores @ 3.6 GHZ
RAM: 128GB DDR4
SSD: 1TB Samsung 980 Evo Plus (Read: 3.5GB/s, Write: 3.0GB/s)
HDD: 4TB Seagate 7200RPM
Controller node
CPU: 8 cores (execution cap: 50%)
RAM: 16GB
SSD: 50GB
Compute node (x3)
CPU: 8 cores (execution cap: 50%)
RAM: 16GB
SSD: 50GB
Controller node sẽ được sử dụng để cài đặt các dịch vụ cần thiết ngoại trừ Nova. Các compute node được cài đặt trên các VM riêng biệt nhằm đảm bảo khả năng hoạt động. Về phần networking, OpenStack hỗ trợ hai lựa chọn cấu hình mạng tuỳ theo yêu cầu của bạn.
Provider networks
Tùy chọn theo cách đơn giản nhất có thể với các dịch vụ chủ yếu là layer 2 (bắc cầu / chuyển mạch) và VLAN segmentation. Về cơ bản, nó làm cầu nối mạng ảo với mạng vật lý và dựa vào cơ sở hạ tầng mạng vật lý cho các dịch vụ layer 3 (định tuyến). Ngoài ra, dịch vụ DHCP cung cấp thông tin địa chỉ IP cho các instance (máy ảo được tạo ra trong OpenStack).
Khi lựa chọn cấu hình mạng này, quản trị viên OpenStack cần phải nắm rõ thông tin về mạng vật lý để tạo mạng ảo khớp chính xác với cơ sở hạ tầng.
Self-service networks
Cấu hình này tăng cường tùy chọn mạng của nhà cung cấp với các dịch vụ layer 3 (định tuyến) cho phép các mạng self-service sử dụng các phương pháp segmentation như VXLAN. Về cơ bản, nó định tuyến các mạng ảo đến các mạng vật lý bằng NAT. Ngoài ra, tùy chọn này cung cấp nền tảng cho các dịch vụ nâng cao như LBaaS và FWaaS.
Với lựa chọn này, quản trị viên OpenStack có thể tạo mạng ảo mà không cần biết về cơ sở hạ tầng. Điều này cũng có thể bao gồm mạng VLAN nếu layer-2 plugins được định cấu hình phù hợp.
Để đảm bảo tính linh hoạt và mở rộng về sau, SDSRV đã lựa chọn Self-service network cho dự án của mình. Cụ thể, cả 04 node đều sử dụng chung cấu hình mạng bao gồm 03 virtual network adapter như sau:
- Host-only adapter (Management network)
- NAT Network (Provider network)
- Bridged Adapter (Mạng bổ sung cho các tác dụng khác)
Sau khi hoàn tất việc cài đặt, phân quyền người dùng là bạn đã có một private cloud để vận hành hệ thống CNTT trong doanh nghiệp của mình. Tuy nhiên, nếu chỉ dừng ở đây thì OpenStack cũng không mang lại thêm bất cứ lợi ích nào quá rõ rệt so với các hệ thống đang được triển khai tại các DC khác.
Chi tiết về cách lập lịch mặc định của OpenStack
Mặc định, compute node sử dụng dịch vụ nova-scheduler để xác định cách gửi các yêu cầu tính toán. Ví dụ: dịch vụ nova-scheduler xác định máy chủ (host) ảo nào sẽ khởi chạy. Trong phạm vi của bài viết này, thuật ngữ host có nghĩa là một máy ảo (vm) có dịch vụ nova-compute đang chạy trên đó. Bạn có thể cấu hình scheduler thông qua nhiều tùy chọn.
Theo mặc định, scheduler_driver được cấu hình như một bộ lập lịch lọc (filter scheduler). Scheduler này sẽ phân tích các host đáp ứng tất cả các tiêu chí sau:
- Chưa từng được phân tích cho mục đích lập lịch (RetryFilter).
- Đang ở trong nhóm khả dụng được yêu cầu (Av AvailableZoneFilter).
- Có đủ RAM (RamFilter).
- Có đủ dung lượng ổ đĩa cho lưu trữ gốc và lưu trữ tạm thời (DiskFilter).
- Có thể phục vụ yêu cầu (ComputeFilter).
- Đáp ứng các thông số kỹ thuật bổ sung được liên kết với loại instance (ComputeCapabilitiesFilter).
- Đáp ứng mọi thuộc tính kiến trúc, kiểu hypervisor hoặc chế độ máy ảo được chỉ định (ImagePropertiesFilter).
- Nằm trên một máy chủ lưu trữ khác với các phiên bản khác của nhóm (nếu được yêu cầu) (ServerGroupAntiAffinityFilter).
Scheduler lưu trữ danh sách các máy chủ có sẵn của nó; sử dụng tùy chọn scheduler_driver_task_period để chỉ định tần suất cập nhật danh sách và lựa chọn một máy chủ mới khi một instance được di chuyển. Khi di chuyển các instance khỏi một host, dịch vụ scheduler sẽ ưu tiên host được định nghĩa bởi quản trị viên khi thực thi lệnh. Nếu mục tiêu không được xác định, scheduler sẽ tự xác định host đích.
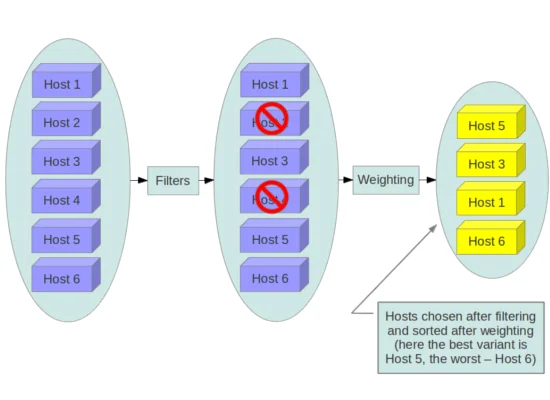
Filter scheduler sẽ đánh trọng số các máy chủ dựa trên tùy chọn cấu hình filter_scheduler.weight_classes, mặc định là nova.scheduler.weights.all_weighers, sẽ lựa chọn các bộ trọng số sau:
- RAMWeigher: Tính toán trọng số dựa trên RAM có sẵn trên node. Sắp xếp từ lớn đến bé.
- CPUWeigher: Tính toán dựa trên số vCPU có sẵn trên node, cũng sắp xếp từ lớn đến bé.
- DiskWeigher của host: Được tính trọng số và sắp xếp theo dung lượng ổ đĩa trống, từ lớn đến bé.
- Các bộ trọng số các như MetricsWeigher, IoOpsWeigher, PCIWeigher, ServerGroupSoftAffinityWeigher, ServerGroupSoftAntiAffinityWeigher
Filter scheduler sẽ tạo danh sách các máy chủ được chấp nhận bằng cách lặp đi lặp lại việc lọc và đánh trọng số. Mỗi khi chọn một host, filter scheduler sẽ chiếm dụng tài nguyên của host đó. Vì vậy, những lần lựa chọn tiếp theo có thể được điều chỉnh cho phù hợp. Điều này sẽ rất có lợi nếu khách hàng yêu cầu một khối lượng lớn các instance, vì trọng số được tính cho mỗi instance được yêu cầu.
Việc phân bố instance dựa trên lọc và đánh trọng số (filtering and weighting) không phải lúc nào cũng tối ưu. Trong thực tế triển khai và thử nghiệm, chúng tôi đã gặp trường hợp khi tài nguyên trống trên từng node không đủ cho việc tạo mới một instance. Trong trường hợp này, việc migrate (di chuyển) các instance qua lại giữa các compute node sẽ giúp phân bố lại resource trống và có thể giúp ta tạo được thêm instance trên hệ thống. Quá trình migrate này không tự động thực hiện bởi OpenStack mà sẽ do quản trị viên thực thi khi cần thiết.
Ta có thể dễ dàng nhận ra, khi hệ thống chỉ bao gồm số ít các node compute, quản trị viên có thể dễ dàng tự thực hiện quá trình migrate instance này. Tuy nhiên, đối với một hệ thống gồm hàng trăm, thậm chí hàng nghìn node compute, migrate instance một cách thủ công là bất khả thi. Nắm bắt được vấn đề này, chúng tôi đã xây dựng và phát triển riêng một phân hệ để quản lý, phân chia tài nguyên cho OpenStack.
Giải pháp lập lịch thông minh do SDSRV phát triển trên nền tảng OpenStack
Đây là một phân hệ được tách biệt hoàn toàn với OpenStack và được cài đặt trên Controller node như một ứng dụng của bên thứ ba (3rd party service). Chúng tôi đặt tên cho phân hệ này là “Smart Scheduler”, bao gồm các thành phần chính như sau:
Database
Chúng tôi sử dụng SQLite để lưu trữ thông tin, dữ liệu về các instance và node trong hệ thống.
Agent service
Các dịch vụ ngầm được cài đặt trên các node compute và toàn bộ instance được khởi tạo. Các agent này sẽ được thiết lập để định kỳ truy vấn các thông tin về tài nguyên và gửi về cho Core Scheduler.
Core scheduler
Là thành phần quan trọng nhất, Core scheduler sẽ tổng hợp dữ liệu được gửi về từ các agent. Sau khi tổng hợp, áp dụng xử lý dữ liệu bằng các thuật toán cân bằng tải (load balancing), heuristics, kết quả cuối cùng sẽ được gửi đến OpenStack thông qua API hoặc SDK để yêu cầu các compute node khởi tạo hoặc migrate các instance.
Reporting service
Là các dịch vụ có chức năng tổng hợp, báo cáo về tình trạng sử dụng tài nguyên theo dạng timeline trên các node vận hành cũng như các instance được khởi tạo và đang hoạt động.
Temporary Instance
Mặc định, toàn bộ instance được tạo ra đều cùng một loại, thường được gọi là “regular instance” hoặc “reserved instance”. Các instance này sẽ được thường trú trong các compute node và chỉ bị ngừng hoặc loại bỏ khi có yêu cầu. Để tăng thêm tính linh hoạt và đáp ứng được nhiều nhu cầu khác nhau của khách hàng, chúng tôi đã bổ sung thêm một loại instance mới, “temporary instance”.
Temporary instance là các instance được khởi tạo và hoạt động một cách tạm thời khi tài nguyên trên hệ thống không được sử dụng đến. Thông thường, chúng thường được sử dụng cho các mục đích không quan trọng, không ảnh hưởng quá nhiều đến hệ thống, ví dụ như các công việc chạy 1 lần, CI, CD,…
Khi có yêu cầu khởi tạo regular instance, các temporary instance này sẽ được phân tích lượng tài nguyên đang sử dụng và được loại bỏ lần lượt cho đến khi lượng tài nguyên còn trống đủ để khởi tạo các instance regular.
Kết quả, so sánh
Smart Scheduler hoạt động như một load balancer cho OpenStack. Khi chạy, cơ chế filtering và weighting của OpenStack sẽ được vô hiệu hoá. Smart Scheduler sẽ quản lý theo chu kỳ mà quản trị viên thiết lập sẵn từ đầu. Để đảm bảo tài nguyên cho phần quản lý này không chiếm quá nhiều, chúng tôi sửa dụng một khoảng thời gian nhất định để thiết lập chu kỳ tổng hợp và báo cáo chứ không phải là thời gian thực. Sau mỗi chu kỳ như vậy, toàn bộ agent được cài đặt trong các instance, các compute node sẽ gửi về thông tin về tình trạng sử dụng tài nguyên của hệ thống. Dựa trên các dữ liệu này, Smart Scheduler sẽ phân tích, lọc, sắp xếp, di chuyển các instance qua lại giữa các compute node để đảm bảo:
- Mức tải của các compute node là tương đương nhau trong suốt quá trình vận hành.
- Tận dụng tốt nhất lượng tài nguyên còn trống trên mỗi compute node.
Lợi ích mang lại từ quá trình trên là rất đáng kể, khi mức tải giữa các compute node được cân bằng và ổn định trong quá trình vận hành, các lỗi thường xảy ra như treo, đơ, lag được giảm thiểu một cách tối đa. Với việc triển khai “temporary instance”, tài nguyên trống trên hệ thống cũng được sử dụng hiệu quả nhất có thể.
Khi thử nghiệm thực tế, với cơ chế mặc định của OpenStack, chúng tôi chỉ có thể khởi tạo và vận hành 10 instance. Con số này là 13 khi sử dụng Smart Scheduler. Sự khác biệt không lớn nhưng nếu so sánh ở một phạm vi rộng hơn, ta có thể dễ dàng nhận thấy ưu thế của Smart Scheduler so với phương thức hoạt động truyền thống. Với cùng một nền tảng hạ tầng, Smart Scheduler đã mang lại cải thiện về mặt hiệu suất đến 130%, thậm chí còn có thể lớn hơn nữa nếu được áp dụng ở quy mô lớn.
Nâng cấp và phát triển
Smart Scheduler sau một quá trình thử nghiệm đã phần nào chứng minh được ưu điểm khi cải thiện được hiệu suất cũng như giảm thiểu chi phí vận hành một cách rõ ràng. Tuy nhiên, SDSRV cũng nhận thấy để sản phẩm được hoàn thiện, một chặng đường phát triển rất dài vẫn còn ở phía trước. Smart Scheduler lúc này vẫn chỉ hoạt động như một add-on, plugin của OpenStack, giao tiếp qua lại thông qua API và SDK và chưa can thiệp sâu vào bất cứ phần core nào.
Việc phải cài đặt, tích hợp cũng sẽ gây khó khăn cho người dùng khác khi sử dụng công nghệ này. Chúng tôi sẽ tiếp tục nghiên cứu, cải thiện và phát triển sản phẩm ngày một tốt hơn nữa. Hi vọng, Smart Scheduler sẽ hoàn thiện và được tích hợp vào OpenStack như một thành phần chính trong một tương lai không xa.
Tham khảo:
[1] Big data centers are power-hungry, but increasingly efficient
[2] OpenStack